Apache ShardingSphere parses the SQL entered by users and rewrites the SQL according to the encryption rules provided by users.
When a user queries data, it only retrieves ciphertext data from the database, decrypts it, and finally returns the decrypted source data to the user. Apache ShardingSphere achieves a transparent and automatic data encryption process. Users can use encrypted data as normal data without paying attention to the implementation details of data encryption.
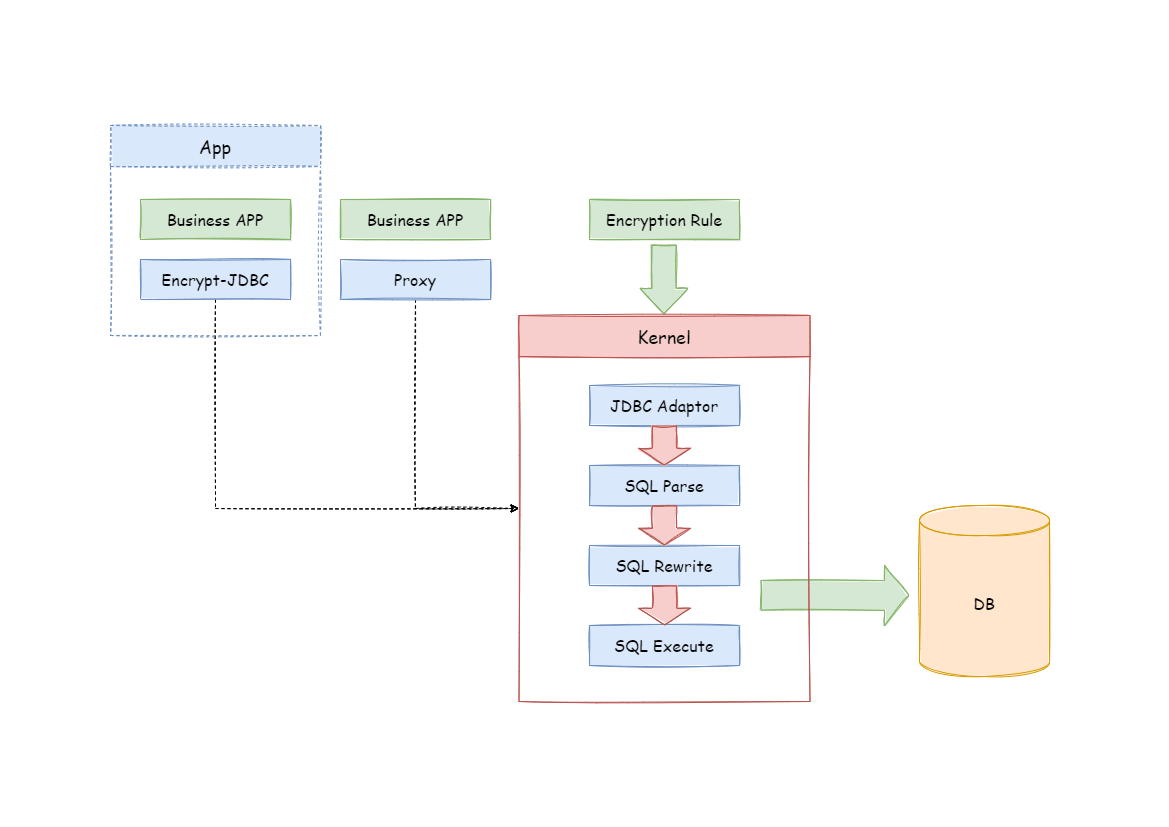
The encrypted module intercepts the SQL initiated by the user and parses and understands the SQL behavior through the SQL syntactic parser. Then it finds out the fields to be encrypted and the encryption and decryption algorithm according to the encryption rules introduced by the user and interacts with the underlying database.
Apache ShardingSphere will encrypt the plaintext requested by users and store it in the underlying database. When the user queries, the ciphertext is extracted from the database, decrypted, and returned to the terminal user. By shielding the data encryption process, users do not need to operate the SQL parsing process, data encryption, and data decryption.
Before explaining the whole process, we need to understand the encryption rules and configuration. Encryption configuration is mainly divided into three parts: data source configuration, encryptor configuration, encryption table configuration, as shown in the figure below:
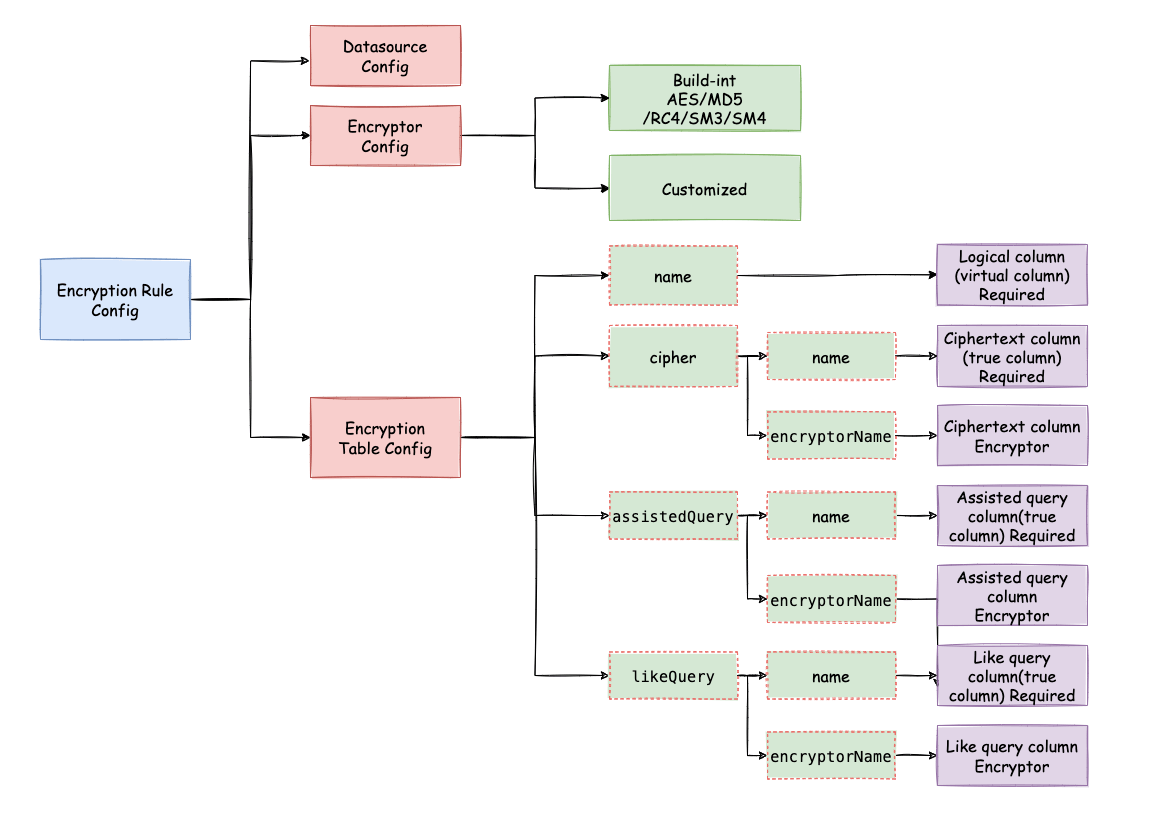
Data source configuration: the configuration of the data source.
Encryptor configuration: refers to the encryption algorithm used for encryption and decryption. Currently, ShardingSphere has three built-in encryption and decryption algorithms: AES, MD5 and RC4. Users can also implement a set of encryption and decryption algorithms by implementing the interfaces provided by ShardingSphere.
Encryption table configuration: it is used to tell ShardingSphere which column in the data table is used to store ciphertext data (cipherColumn), and which column the user would like to use for SQL writing (logicColumn).
What does it mean by “which column the user would like to use for SQL writing (logicColumn)”? We have to know first why the encrypted module exists. The goal of the encrypted module is to shield the underlying data encryption process, which means we don’t want users to know how data is encrypted and decrypted, and how to store ciphertext data into
cipherColumn. In other words, we don’t want users to know there is acipherColumnor how they are used. Therefore, we need to provide the user with a conceptual column that can be separated from the real column in the underlying database. It may or may not be a real column in the database table so that users can change the column names ofcipherColumnof the underlying database at will. The only thing we have to ensure is that the user’s SQL is written towards the logical column, and the correct mapping relation betweenlogicColumnandcipherColumncan be seen in the encryption rules.
Query attribute configuration: if both plaintext and ciphertext data are stored in the underlying database table, this attribute can be used to determine whether to query the plaintext data in the database table and return it directly, or query the ciphertext data and return it after decryption through Apache ShardingSphere. This attribute can be configured at the table level and the entire rule level. The table-level has the highest priority.
For example, if there is a table named t_user in the database, and they’re two fields in the table: pwd_cipher for storing ciphertext data, and logicColumn is defined as pwd, then users should write SQL for logicColumn, that is INSERT INTO t_user SET pwd = '123'. Apache ShardingSphere receives the SQL and finds that the pwd is the logicColumn based on the encryption configuration provided by the user. Therefore, it encrypts the logical column and its corresponding plaintext data.
Apache ShardingSphere transforms the column names and data encryption mapping between the logical columns facing users and cipher columns facing the underlying database. As shown in the figure below:
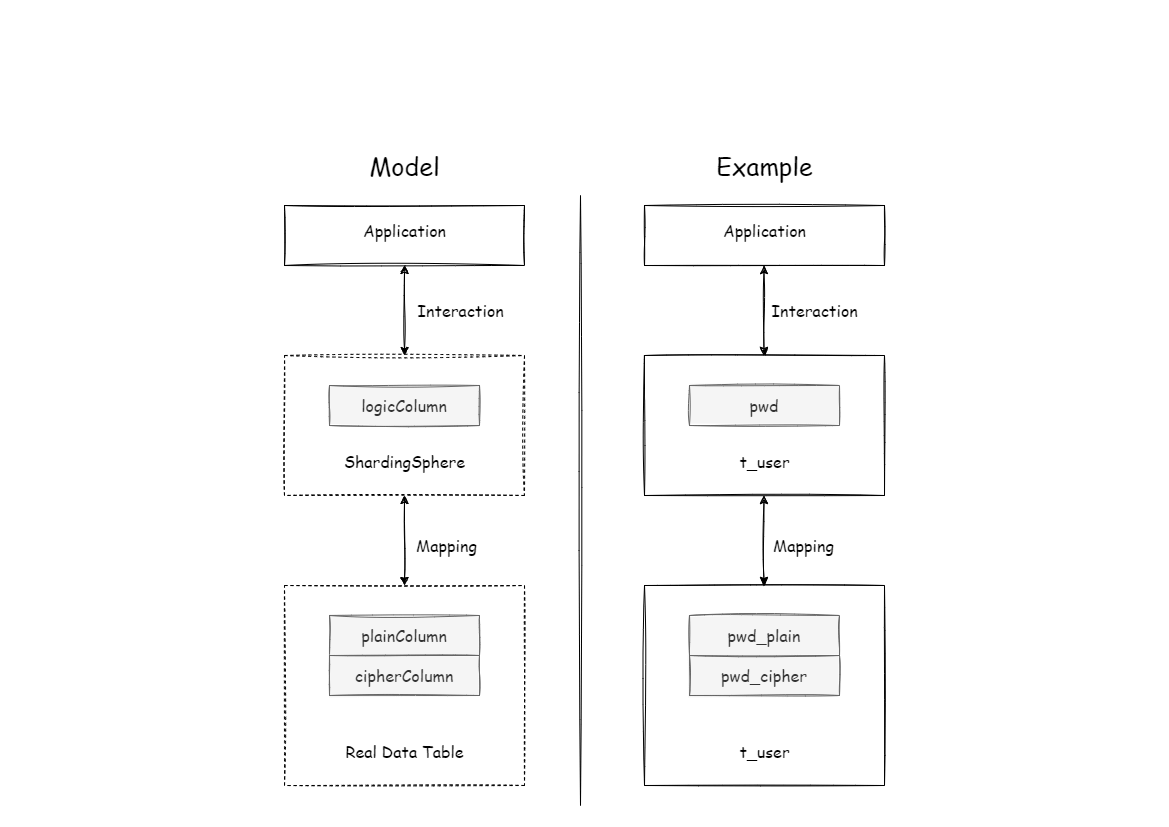
The user’s SQL is separated from the underlying data table structure according to the encryption rules provided by the user so that the user’s SQL writing does not depend on the real database table structure.
The connection, mapping, and transformation between the user and the underlying database are handled by Apache ShardingSphere.
The picture below shows the processing flow and conversion logic when the encryption module is used to add, delete, change and check, as shown in the figure below.

After understanding Apache ShardingSphere’s encryption process, you can combine the encryption configuration and encryption process according to your scenario. The entire design & development was conceived to address the pain points encountered in business scenarios. So, how to use Apache ShardingSphere to meet the business requirements mentioned before?
Business scenario analysis: the newly launched business is relatively simple because it starts from scratch and there’s no need to clean up historical data.
Solution description: after selecting the appropriate encryption algorithm, such as AES, you only need to configure the logical column (write SQL for users) and the ciphertext column (the data table stores the ciphertext data). The logical columns and ciphertext columns can also be different. The following configurations are recommended (in YAML format):
-!ENCRYPT
encryptors:
aes_encryptor:
type: AES
props:
aes-key-value: 123456abc
digest-algorithm-name: SHA-1
tables:
t_user:
columns:
pwd:
cipher:
name: pwd_cipher
encryptorName: aes_encryptor
assistedQuery:
name: pwd_assisted_query
encryptorName: pwd_assisted_query_cipher
With the above configuration, Apache ShardingSphere only needs to convert logicColumn, cipherColumn, and assistedQueryColumn.
The underlying data table does not store plaintext, and only ciphertext is stored, which is also the requirement of the security audit. The overall processing flow is shown in the figure below:
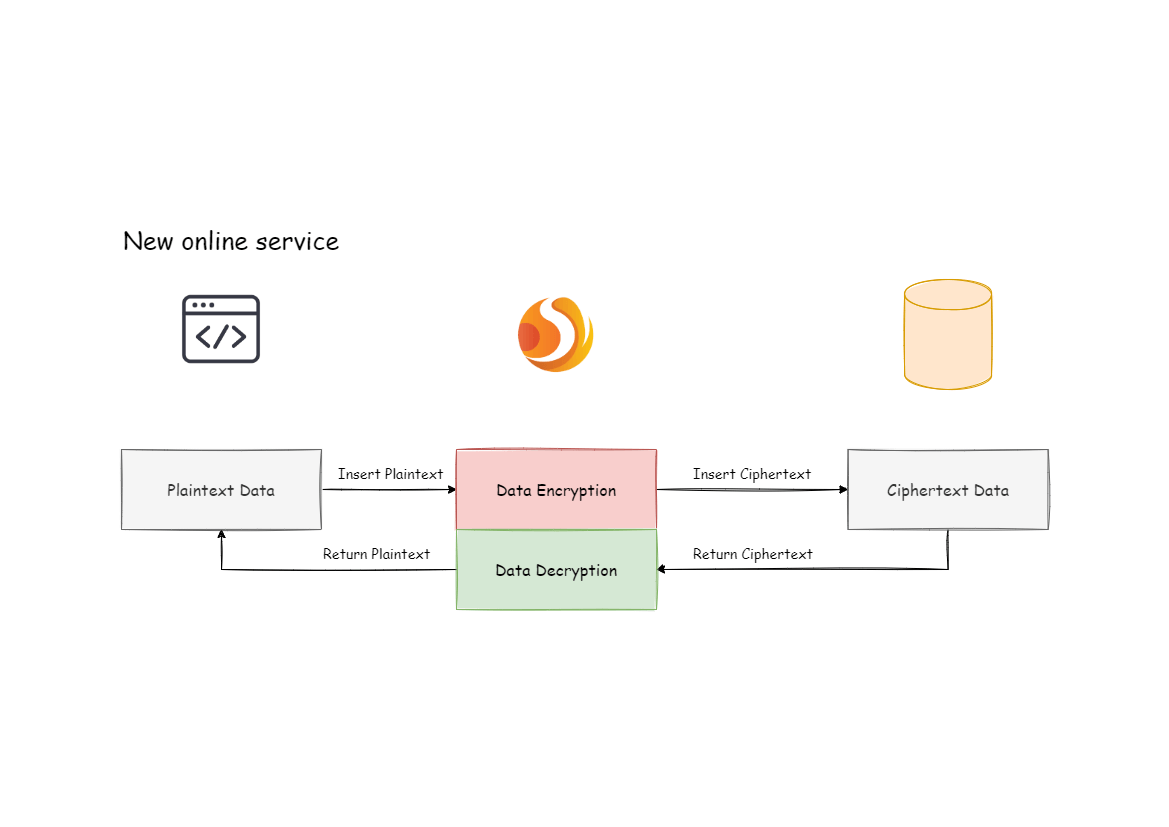
Apache ShardingSphere provides an encryption algorithm for data encryption, namely EncryptAlgorithm.
On the one hand, Apache ShardingSphere provides users with built-in implementation classes for encryption and decryption, which are available through configurations by users.
On the other hand, in order to be applicable to different scenarios, we also opened the encryption and decryption interfaces, and users can provide specific implementation classes according to these two types of interfaces.
After simple configuration, Apache ShardingSphere can call user-defined encryption and decryption schemes for data encryption.
The solution provides two methods, encrypt() and decrypt(), to encrypt or decrypt data.
When users perform INSERT, DELETE and UPDATE operations, ShardingSphere will parse, rewrite and route SQL according to the configuration.
It will also use encrypt() to encrypt data and store them in the database. When using SELECT, they will decrypt sensitive data from the database with decrypt() and finally return the original data to users.
Currently, Apache ShardingSphere provides three types of implementations for this kind of encryption solution, including MD5 (irreversible), AES (reversible) and RC4 (reversible), which can be used after configuration.