影子库
整体架构
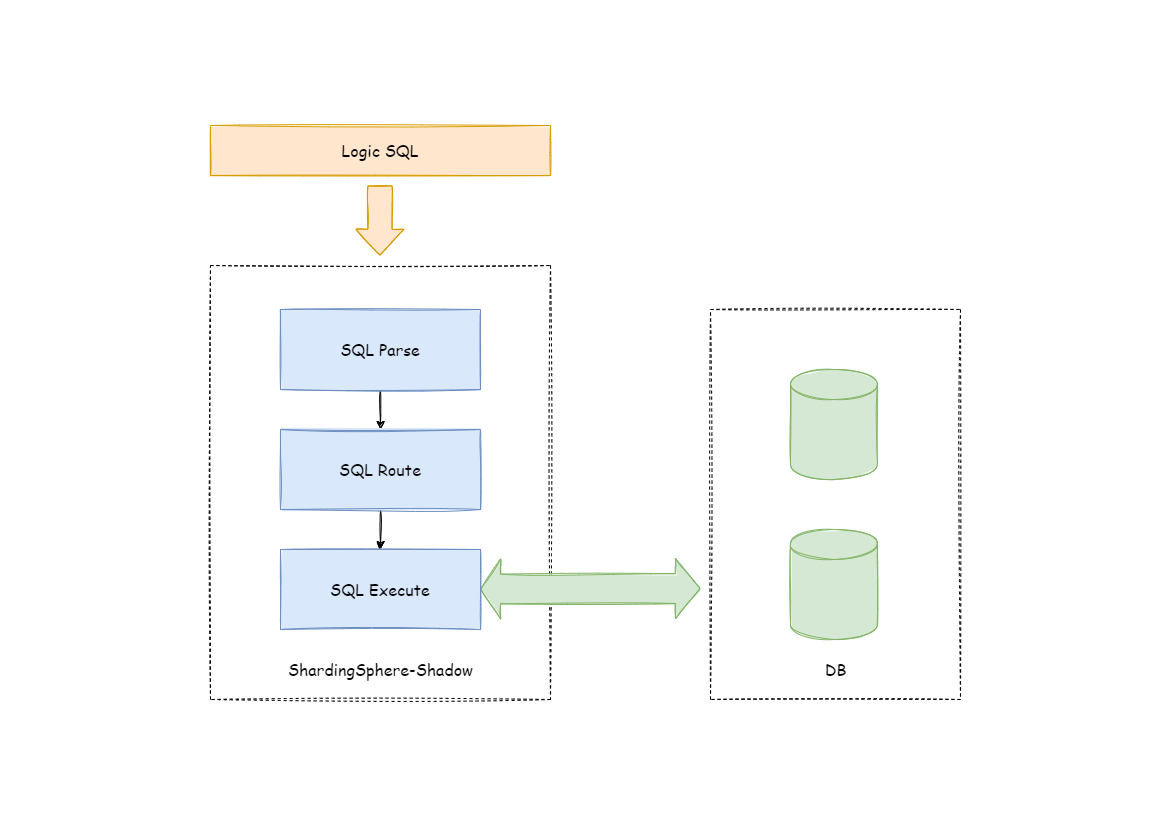
Apache ShardingSphere 通过解析 SQL,对传入的 SQL 进行影子判定,根据配置文件中用户设置的影子规则,路由到生产库或者影子库。
影子规则
影子规则包含影子数据源映射关系,影子表以及影子算法。
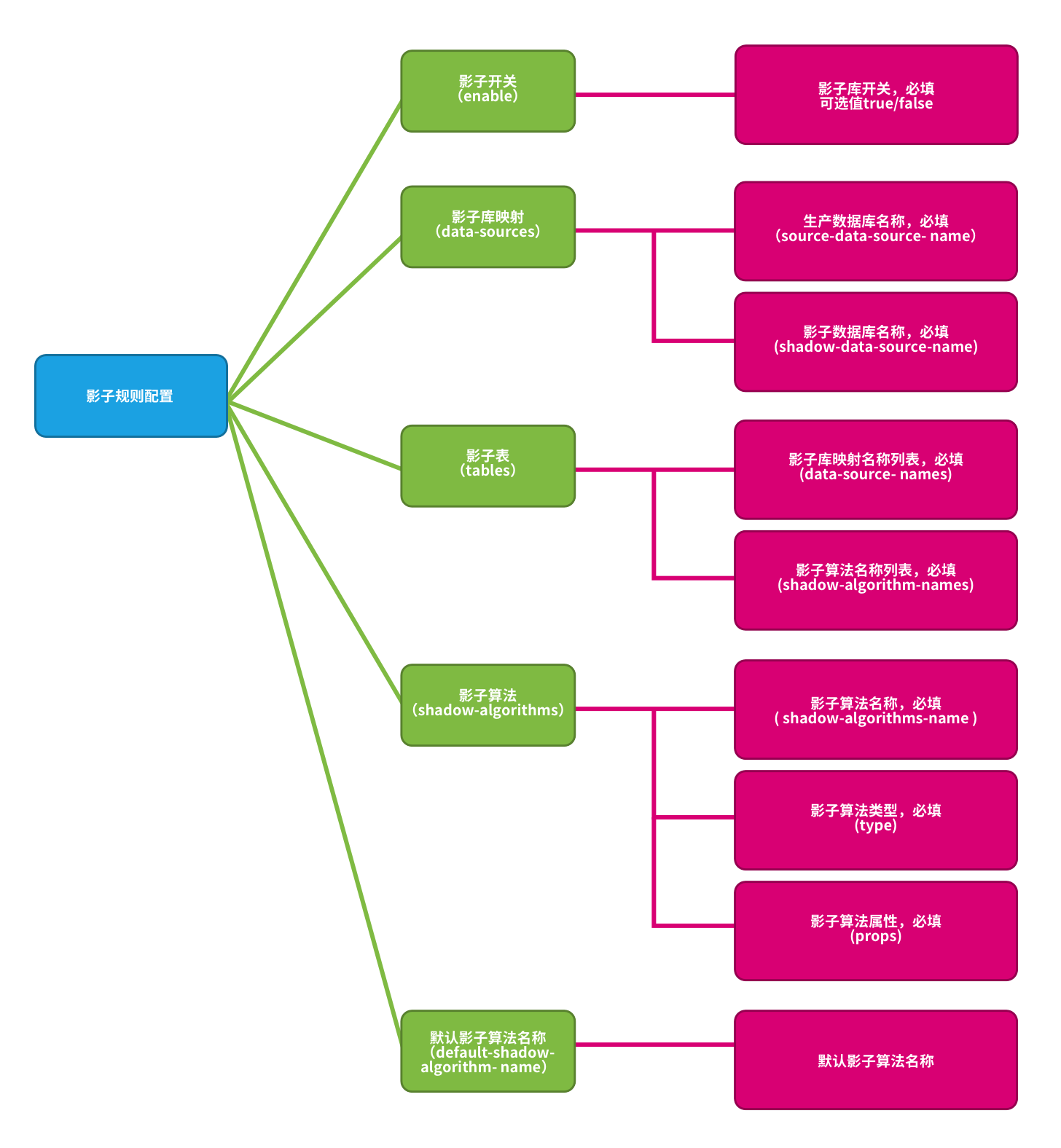
影子库开关:影子库功能开关,默认值 false。可选值 true/false
影子库映射:生产数据源名称和影子数据源名称映射关系。
影子表:压测相关的影子表。影子表必须存在于指定的影子库中,并且需要指定影子算法。
影子算法:SQL 路由影子算法。
默认影子算法:默认影子算法。选配项,对于没有配置影子算法表的默认匹配算法。
路由过程
以 INSERT 语句为例,在写入数据时,Apache ShardingSphere 会对 SQL 进行解析,再根据配置文件中的规则,构造一条路由链。在当前版本的功能中, 影子功能处于路由链中的最后一个执行单元,即,如果有其他需要路由的规则存在,如分片,Apache ShardingSphere 会首先根据分片规则,路由到某一个数据库,再 执行影子路由判定流程,判定执行SQL满足影子规则的配置,数据路由到与之对应的影子库,生产数据则维持不变。
影子判定流程
影子库开关开启时,会对执行的 SQL 语句进行影子判定。影子判定支持两种类型算法,用户可根据实际业务需求选择一种或者组合使用。
DML 语句
支持两种算法。影子判定会首先判断执行 SQL 相关表与配置的影子表是否有交集。如果有交集,依次判定交集部分影子表关联的影子算法,有任何一个判定成功。SQL 语句路由到影子库。 影子表没有交集或者影子算法判定不成功,SQL 语句路由到生产库。
DDL 语句
仅支持注解影子算法。在压测场景下,DDL 语句一般不需要测试。主要在初始化或者修改影子库中影子表时使用。
影子判定会首先判断执行 SQL 是否包含注解。如果包含注解,影子规则中配置的注解影子算法依次判定。有任何一个判定成功。SQL 语句路由到影子库。 执行 SQL 不包含注解或者注解影子算法判定不成功,SQL 语句路由到生产库。
影子算法
影子算法详情,请参见内置影子算法列表
使用案例
场景需求
假设一个电商网站要对下单业务进行压测。压测相关表 t_order 为影子表,生产数据执行到 ds 生产数据库,压测数据执行到数据库 ds_shadow 影子库。
影子库配置
建议配置如下(YAML 格式展示):
enable: true
data-sources:
shadow-data-source:
source-data-source-name: ds
shadow-data-source-name: ds-shadow
tables:
t_order:
data-source-names: shadow-data-source
shadow-algorithm-names:
- simple-note-algorithm
- user-id-match-algorithm
shadow-algorithms:
simple-note-algorithm:
type: SIMPLE_NOTE
props:
shadow: true
foo: bar
user-id-match-algorithm:
type: COLUMN_VALUE_MATCH
props:
operation: insert
column: user_id
value: 0
props:
sql-comment-parse-enabled: true
注意: 如果使用注解影子算法,需要开启解析 SQL 注释配置项 sql-comment-parse-enabled: true。默认关闭。
请参考 配置项说明
影子库环境
-
创建影子库
ds_shadow。 -
创建影子表,表结构与生产环境必须一致。假设在影子库创建
t_order表。创建表语句需要添加 SQL 注释/*shadow:true,foo:bar,...*/。即:
CREATE TABLE t_order (order_id INT(11) primary key, user_id int(11) not null, ...) /*shadow:true,foo:bar,...*/
执行到影子库。
影子算法使用
- 列影子算法使用
假设 t_order 表中包含下单用户ID的 user_id 列。 实现的效果,当用户ID为 0 的用户创建订单产生的数据。 即:
INSERT INTO t_order (order_id, user_id, ...) VALUES (xxx..., 0, ...)
会执行到影子库,其他数据执行到生产库。
无需修改任何 SQL 或者代码,只需要对压力测试的数据进行控制就可以实现在线的压力测试。
算法配置如下(YAML 格式展示):
shadow-algorithms:
user-id-match-algorithm:
type: COLUMN_VALUE_MATCH
props:
operation: insert
column: user_id
value: 0
注意:影子表使用列影子算法时,相同类型操作(INSERT, UPDATE, DELETE, SELECT)目前仅支持单个字段。
- 使用注解影子算法
假设 t_order 表中不包含可以对值进行匹配的列。添加注解 /*shadow:true,foo:bar,...*/ 到执行 SQL 中,即:
SELECT * FROM t_order WHERE order_id = xxx /*shadow:true,foo:bar,...*/
会执行到影子库,其他数据执行到生产库。
算法配置如下(YAML 格式展示):
shadow-algorithms:
simple-note-algorithm:
type: SIMPLE_NOTE
props:
shadow: true
foo: bar
- 混合使用影子模式
假设对 t_order 表压测需要覆盖以上两种场景,即,
INSERT INTO t_order (order_id, user_id, ...) VALUES (xxx..., 0, ...);
SELECT * FROM t_order WHERE order_id = xxx /*shadow:true,foo:bar,...*/;
都会执行到影子库,其他数据执行到生产库。
算法配置如下(YAML 格式展示):
shadow-algorithms:
user-id-match-algorithm:
type: COLUMN_VALUE_MATCH
props:
operation: insert
column: user_id
value: 0
simple-note-algorithm:
type: SIMPLE_NOTE
props:
shadow: true
foo: bar
- 使用默认影子算法
假设对 t_order 表压测使用列影子算法,其他相关其他表都需要使用注解影子算法。即,
INSERT INTO t_order (order_id, user_id, ...) VALUES (xxx..., 0, ...);
INSERT INTO t_xxx_1 (order_item_id, order_id, ...) VALUES (xxx..., xxx..., ...) /*shadow:true,foo:bar,...*/;
SELECT * FROM t_xxx_2 WHERE order_id = xxx /*shadow:true,foo:bar,...*/;
SELECT * FROM t_xxx_3 WHERE order_id = xxx /*shadow:true,foo:bar,...*/;
都会执行到影子库,其他数据执行到生产库。
配置如下(YAML 格式展示):
enable: true
data-sources:
shadow-data-source:
source-data-source-name: ds
shadow-data-source-name: ds-shadow
tables:
t_order:
data-source-names: shadow-data-source
shadow-algorithm-names:
- simple-note-algorithm
- user-id-match-algorithm
default-shadow-algorithm-name: simple-note-algorithm
shadow-algorithms:
simple-note-algorithm:
type: SIMPLE_NOTE
props:
shadow: true
foo: bar
user-id-match-algorithm:
type: COLUMN_VALUE_MATCH
props:
operation: insert
column: user_id
value: 0
props:
sql-comment-parse-enabled: true
注意:默认影子算法仅支持注解影子算法。