背景
在 Apache ShardingSphere 中,很多功能实现类的加载方式是通过 SPI(Service Provider Interface) 注入的方式完成的。 SPI 是一种为了被第三方实现或扩展的 API,它可以用于实现框架扩展或组件替换。
挑战
可插拔架构对程序架构设计的要求非常高,需要将各个模块相互独立,互不感知,并且通过一个可插拔内核,以叠加的方式将各种功能组合使用。 设计一套将功能开发完全隔离的架构体系,既可以最大限度的将开源社区的活力激发出来,也能够保障项目的质量。
Apache ShardingSphere 5.x 版本开始致力于可插拔架构,项目的功能组件能够灵活的以可插拔的方式进行扩展。 目前,数据分片、读写分离、数据库高可用、数据加密、影子库压测等功能,以及对 MySQL、PostgreSQL、SQLServer、Oracle 等 SQL 与协议的支持,均通过插件的方式织入项目。 Apache ShardingSphere 目前已提供数十个 SPI 作为系统的扩展点,而且仍在不断增加中。
目标
让开发者能够像使用积木一样定制属于自己的独特系统,是 Apache ShardingSphere 可插拔架构的设计目标。
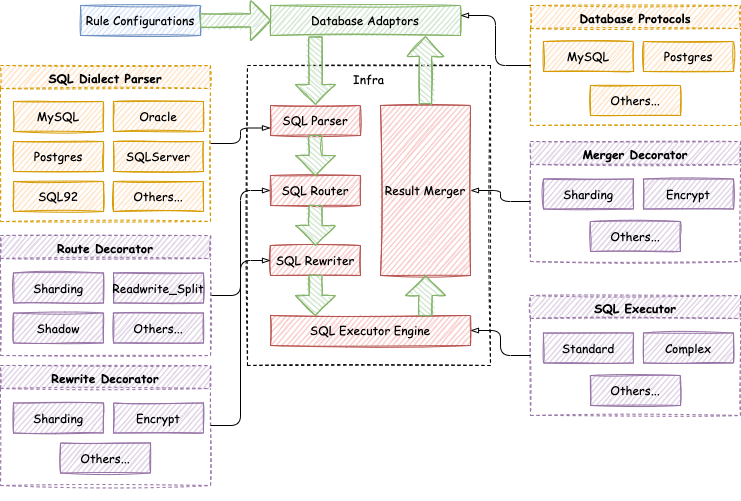
实现
Apache ShardingSphere 的可插拔架构划分为 3 层,它们是:L1 内核层、L2 功能层、L3 生态层。
L1 内核层
是数据库基本能力的抽象,其所有组件均必须存在,但具体实现方式可通过可插拔的方式更换。 主要包括查询优化器、分布式事务引擎、分布式执行引擎、权限引擎和调度引擎等。
L2 功能层
用于提供增量能力,其所有组件均是可选的,可以包含零至多个组件。组件之间完全隔离,互无感知,多组件可通过叠加的方式相互配合使用。 主要包括数据分片、读写分离、数据库高可用、数据加密、影子库等。用户自定义功能可完全面向 Apache ShardingSphere 定义的顶层接口进行定制化扩展,而无需改动内核代码。
L3 生态层
用于对接和融入现有数据库生态,包括数据库协议、SQL 解析器和存储适配器,分别对应于 Apache ShardingSphere 以数据库协议提供服务的方式、SQL 方言操作数据的方式以及对接存储节点的数据库类型。