目前的数据迁移解决方案为:使用一个全新的数据库集群作为迁移目标库。
这种实现方式有以下优点:
同时也存在一定的缺点:
一次数据迁移包括以下几个主要阶段:
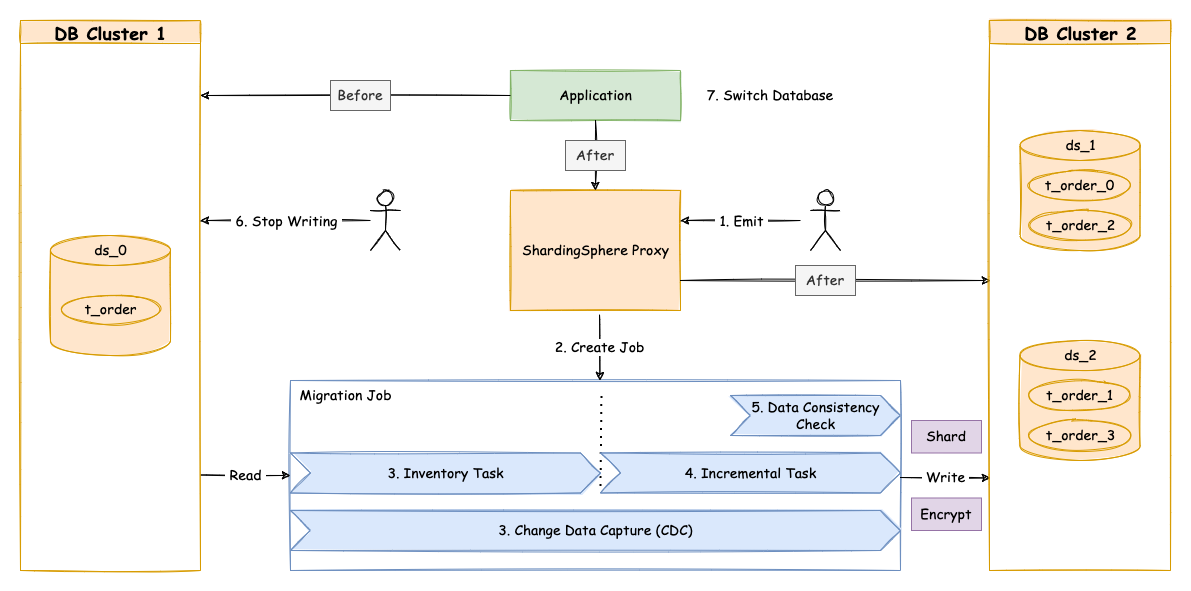
在准备阶段,数据迁移模块会进行数据源连通性及权限的校验,同时进行存量数据的统计、日志位点的记录,最后根据数据量和用户设置的并行度,对任务进行分片。
执行在准备阶段拆分好的存量数据迁移任务,存量迁移阶段采用 JDBC 查询的方式,直接从源端读取数据,基于配置的分片等规则写入到目标端。
由于存量数据迁移耗费的时间受到数据量和并行度等因素影响,此时需要对这段时间内业务新增的数据进行同步。 不同的数据库使用的技术细节不同,但总体上均为基于复制协议或 WAL 日志实现的变更数据捕获功能。
这些捕获的增量数据,同样会由数据迁移模块写入到新数据节点中。当增量数据基本同步完成时(由于业务系统未停止,增量数据是不断的),则进入流量切换阶段。
在此阶段,可能存在一定时间的业务只读窗口期,通过设置数据库只读、控制源头写流量等方式,让源端数据节点中的数据短暂静态,确保增量同步完全完成。
这个只读窗口期时长取决于用户是否需要对数据进行一致性校验以及数据量。一致性校验是独立的任务,支持单独启停,支持断点续传。
确认完成后,数据迁移完成。 然后用户可以把读流量或者写流量切换到 Apache ShardingSphere。