Shadow
Overall Architecture
Apache ShardingSphere makes shadow judgments on incoming SQL by parsing SQL, according to the shadow rules set by the user in the configuration file, route to production DB or shadow DB.
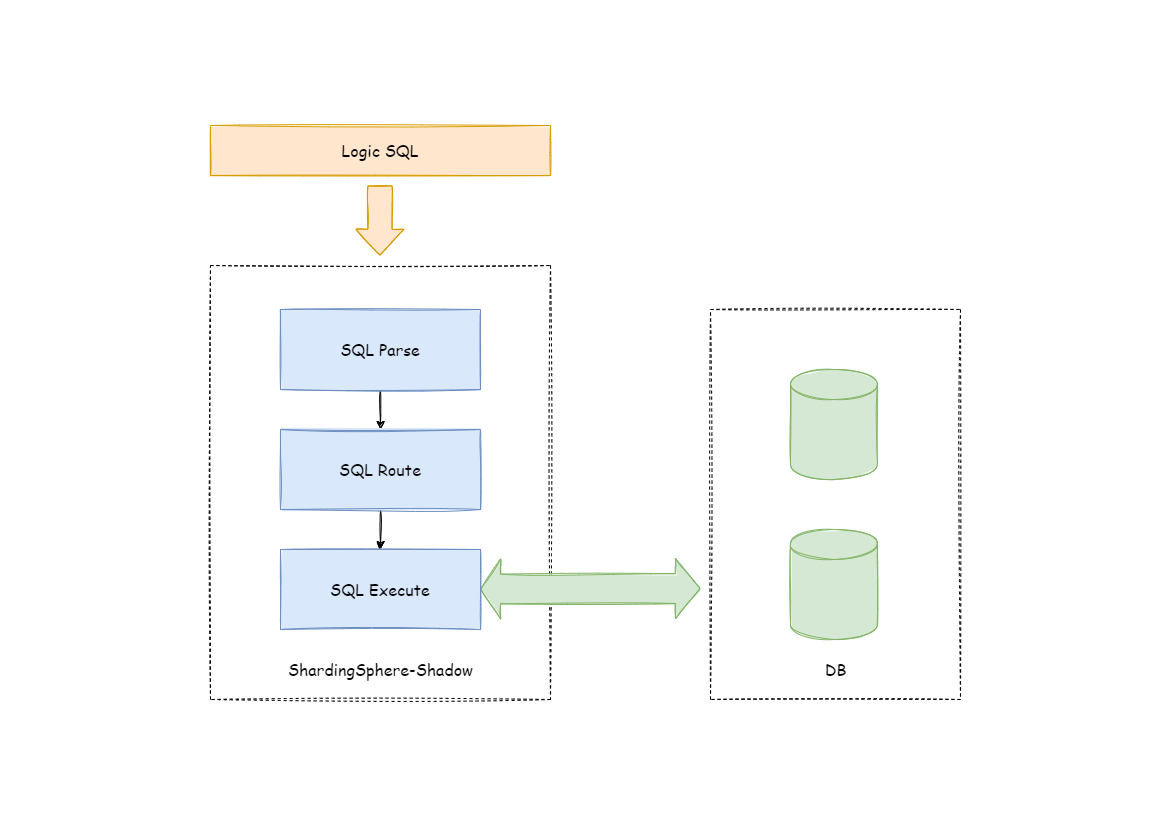
Shadow Rule
Shadow rules include shadow data source mapping, shadow tables, and shadow algorithms.
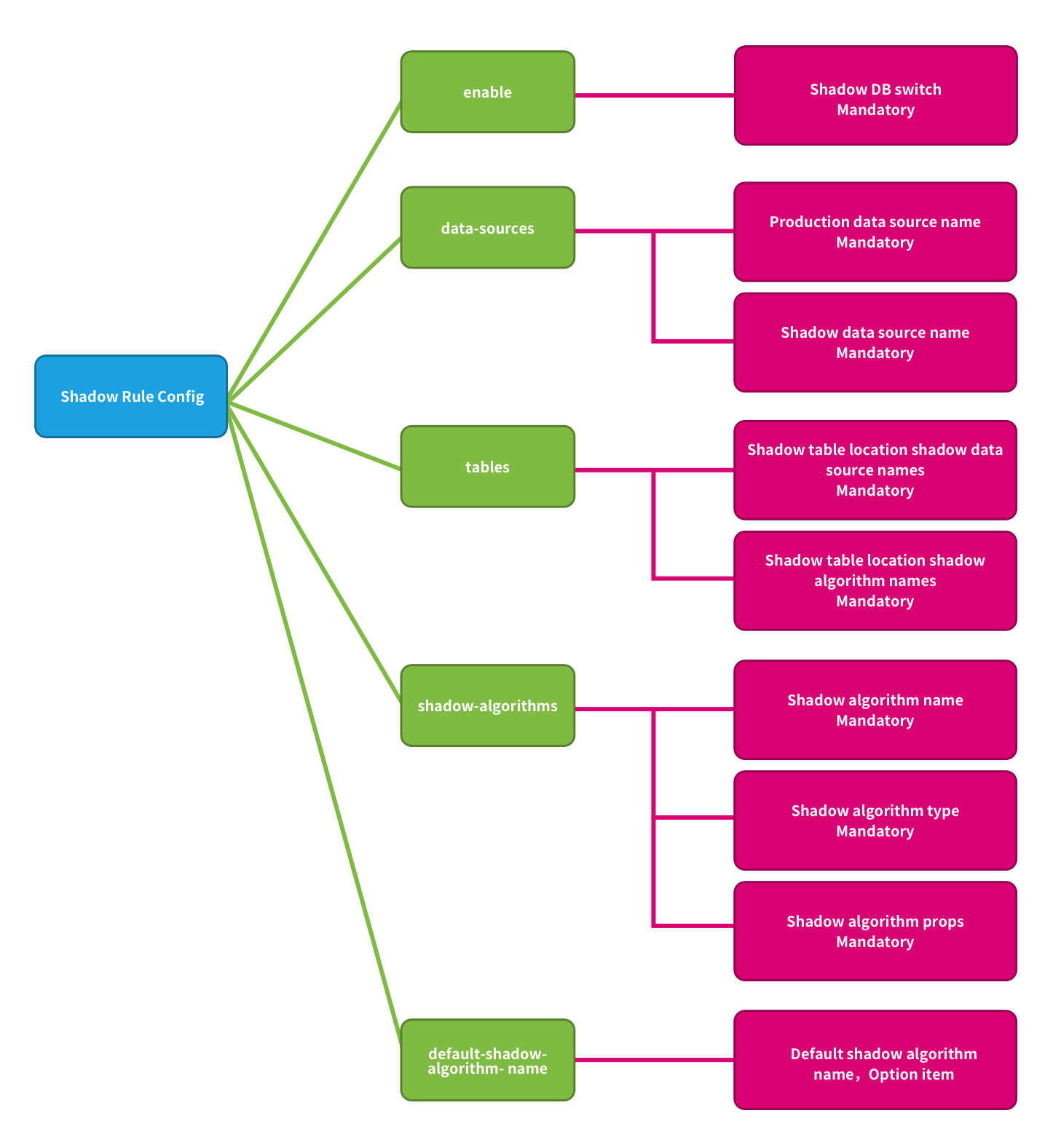
enable:Shadow DB switch. Optional value true/false, default value is false.
data-sources:Production data source name and shadow data source name mappings.
tables:Shadow tables related to stress testing. Shadow tables must exist in the specified shadow DB, and the shadow algorithm needs to be specified.
shadow-algorithms:SQL routing shadow algorithm.
default-shadow-algorithm-name:Default shadow algorithm. Optional item, the default matching algorithm for tables that not configured with the shadow algorithm.
Routing Process
Take the INSERT statement as an example. When writing data Apache ShardingSphere will parse the SQL, and then construct a routing chain according to the rules in the configuration file.
In the current version of the function, the shadow function is the last execution unit in the routing chain, that is, if there are other rules that require routing, such as sharding, Apache ShardingSphere will first route to a certain database according to the sharding rules, and then perform the shadow routing decision process.
It determined that the execution of SQL satisfies the configuration of the shadow rule, the data routed to the corresponding shadow database, and the production data remains unchanged.
Shadow Judgment Process
When the shadow DB switch turned on, shadow judgment will be made on the executed SQL statements.
Shadow judgment supports two types of algorithms, users can choose one or combine them according to actual business needs.
DML Statement
Support two type shadow algorithms.
The shadow judgment first judges whether there is an intersection between SQL related tables and configured shadow tables.
If there is an intersection, determine the shadow algorithm associated with the shadow table of the intersection in turn,and any one of them was successful. SQL statement executed shadow DB.
If shadow tables have no intersection, or shadow algorithms are unsuccessful, SQL statement executed production DB.
DDL Statement
Only support note shadow algorithm.
In the pressure testing scenarios, DDL statements are not need tested generally. It is mainly used when initializing or modifying the shadow table in the shadow DB.
The shadow judgment first judges whether the executed SQL contains notes.
If contains notes, determine the note shadow algorithms in the shadow rule in turn, and any one of them was successful. SQL statement executed shadow DB.
The executed SQL does not contain notes, or shadow algorithms are unsuccessful, SQL statement executed production DB.
Shadow Algorithm
Shadow algorithm details, please refer to List of built-in shadow algorithms
Use Example
Scenario
Assume that the e-commerce website wants to perform pressure testing on the order business,
the pressure testing related table t_order is a shadow table,the production data executed to the ds production DB, and the pressure testing data executed to the database ds_shadow shadow DB.
Shadow DB configuration
The shadow configuration for example(YAML):
enable: true
data-sources:
shadow-data-source:
source-data-source-name: ds
shadow-data-source-name: ds-shadow
tables:
t_order:
data-source-names: shadow-data-source
shadow-algorithm-names:
- simple-note-algorithm
- user-id-match-algorithm
shadow-algorithms:
simple-note-algorithm:
type: SIMPLE_NOTE
props:
shadow: true
foo: bar
user-id-match-algorithm:
type: COLUMN_VALUE_MATCH
props:
operation: insert
column: user_id
value: 0
props:
sql-comment-parse-enabled: true
Note: If you use the annotation shadow algorithm, the parse SQL comment configuration item sql-comment-parse-enabled: true need to be turned on. turned off by default.
please refer to Configuration Props
Shadow DB environment
-
Create the shadow DB
ds_shadow. -
Create shadow tables, tables structure must be consistent with the production environment. Assume that the
t_ordertable created in the shadow DB. Create table statement need to add SQL note/*shadow:true,foo:bar,.. .*/.
CREATE TABLE t_order (order_id INT(11) primary key, user_id int(11) not null, ...) /*shadow:true,foo:bar,...*/
Execute to the shadow DB.
Shadow algorithm example
- Column shadow algorithm example
Assume that the t_order table contains a list of user_id to store the order user ID.
The data of the order created by the user whose user ID is 0 executed to shadow DB, other data executed to production DB.
INSERT INTO t_order (order_id, user_id, ...) VALUES (xxx..., 0, ...)
No need to modify any SQL or code, only need to control the data of the testing to realize the pressure testing.
Column Shadow algorithm configuration (YAML):
shadow-algorithms:
user-id-match-algorithm:
type: COLUMN_VALUE_MATCH
props:
operation: insert
column: user_id
value: 0
Note: When the shadow table uses the column shadow algorithm, the same type of shadow operation (INSERT, UPDATE, DELETE, SELECT) currently only supports a single column.
- Note shadow algorithm example
Assume that the t_order table does not contain columns that can matching. Executed SQL statement need to add SQL note /*shadow:true,foo:bar,.. .*/
SELECT * FROM t_order WHERE order_id = xxx /*shadow:true,foo:bar,...*/
SQL executed to shadow DB, other data executed to production DB.
Note Shadow algorithm configuration (YAML):
shadow-algorithms:
simple-note-algorithm:
type: SIMPLE_NOTE
props:
shadow: true
foo: bar
- Hybrid two shadow algorithm example
Assume that the pressure testing of the t_order gauge needs to cover the above two scenarios.
INSERT INTO t_order (order_id, user_id, ...) VALUES (xxx..., 0, ...);
SELECT * FROM t_order WHERE order_id = xxx /*shadow:true,foo:bar,...*/;
Both will be executed to shadow DB, other data executed to production DB.
2 type of shadow algorithm example (YAML):
shadow-algorithms:
user-id-match-algorithm:
type: COLUMN_VALUE_MATCH
props:
operation: insert
column: user_id
value: 0
simple-note-algorithm:
type: SIMPLE_NOTE
props:
shadow: true
foo: bar
- Default shadow algorithm example
Assume that the column shadow algorithm used for the t_order, all other shadow tables need to use the note shadow algorithm.
INSERT INTO t_order (order_id, user_id, ...) VALUES (xxx..., 0, ...);
INSERT INTO t_xxx_1 (order_item_id, order_id, ...) VALUES (xxx..., xxx..., ...) /*shadow:true,foo:bar,...*/;
SELECT * FROM t_xxx_2 WHERE order_id = xxx /*shadow:true,foo:bar,...*/;
SELECT * FROM t_xxx_3 WHERE order_id = xxx /*shadow:true,foo:bar,...*/;
Both will be executed to shadow DB, other data executed to production DB.
Default shadow algorithm configuration (YAML):
enable: true
data-sources:
shadow-data-source:
source-data-source-name: ds
shadow-data-source-name: ds-shadow
tables:
t_order:
data-source-names: shadow-data-source
shadow-algorithm-names:
- simple-note-algorithm
- user-id-match-algorithm
default-shadow-algorithm-name: simple-note-algorithm
shadow-algorithms:
simple-note-algorithm:
type: SIMPLE_NOTE
props:
shadow: true
foo: bar
user-id-match-algorithm:
type: COLUMN_VALUE_MATCH
props:
operation: insert
column: user_id
value: 0
props:
sql-comment-parse-enabled: true
Note: The default shadow algorithm only supports note shadow algorithm.