SQL is relatively simple compared with other programming languages, but it’s still a complete programming language. Therefore, there’s no essential difference between parsing SQL syntax and parsing other languages (such as Java, C and Go, etc.).
The parsing process is divided into lexical parsing and syntactic parsing. The lexical parser is used to split SQL into indivisible atomic symbols called Tokens.
Tokens are classified into keywords, expressions, literals, and operators based on the dictionaries provided by different database dialects. The syntactic parser is then used to convert the output of the lexical parser into an abstract syntax tree.
For example:
SELECT id, name FROM t_user WHERE status = 'ACTIVE' AND age > 18
After the above SQL is parsed, its AST (Abstract Syntax Tree) is as follows:
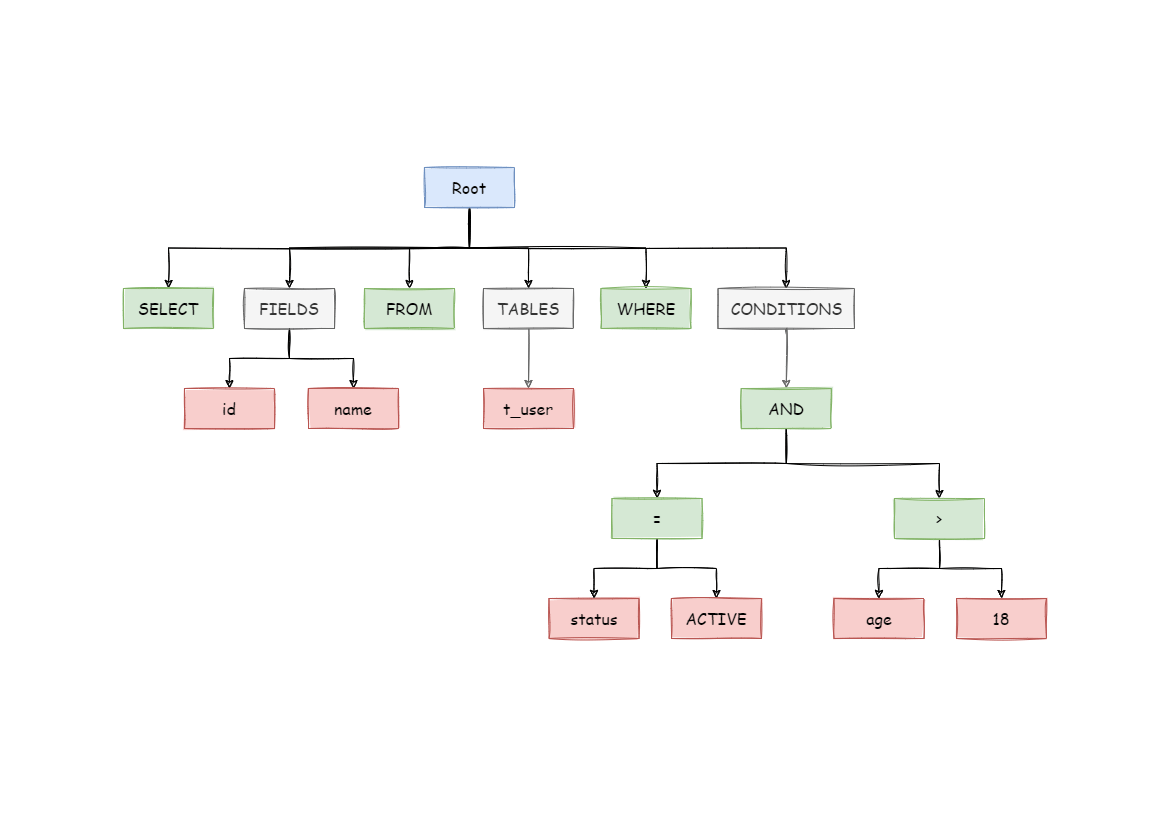
The tokens for keywords in the AST are green, while the tokens for variables are red, and gray ones indicate that further splitting is required.
Finally, the domain model is traversed through the abstract syntax tree by visitor; the context required for sharding is extracted through the domain model (SQLStatement); and then, mark locations that may need rewriting.
The parsing context for sharding includes select items, table, sharding condition, auto-increment primary key, and Order By, Group By, and pagination information (Limit, Rownum, Top). The SQL parsing process is irreversible.
Each Token is parsed in the original SQL order, providing high performance. Taking the similarities and differences of SQL dialects of various databases into consideration, the SQL dialect dictionary of various databases is provided in the parsing module.
SQL parsing is the core of sharding solutions, and its performance and compatibility are the most important indicators. ShardingSphere’s SQL parser has undergone three iterations and upgrades.
To achieve high performance and fast implementation, the first generation of SQL parsers used Druid prior to V1.4.x. In practical tests, its performance far exceeds that of other parsers.
The second generation of SQL parsers started from V1.5.x. ShardingSphere uses a completely self-developed SQL parsing engine. Owing to different purposes, ShardingSphere does not need to convert SQL into a complete abstract syntax tree, nor does it require a second traversal through the accessor pattern. It uses a half-parsing method to extract only the context required by data sharding, thus further improving the performance and compatibility of SQL parsing.
The third generation of SQL parsers, starting with V3.0.x, attempts to use ANTLR as a generator of SQL parsing engines and uses Visit to obtain SQL statements from the AST. Since V5.0.x, the architecture of the parsing engine has been restructured and adjusted. Moreover, the AST obtained from the first parsing is stored in the cache so that the parsing results of the same SQL can be directly obtained next time to improve parsing efficiency. Therefore, it is recommended that you use PreparedStatement, a SQL-precompiled method, to improve performance.
ANTLR)| Database | Status |
|---|---|
| MySQL | perfect supported |
| PostgreSQL | perfect supported |
| SQLServer | supported |
| Oracle | supported |
| SQL92 | supported |
| openGauss | supported |
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>shardingsphere-sql-parser-engine</artifactId>
<version>${project.version}</version>
</dependency>
<!-- According to the needs, introduce the parsing module of the specified dialect (take MySQL as an example), you can add all the supported dialects, or just what you need -->
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>shardingsphere-sql-parser-mysql</artifactId>
<version>${project.version}</version>
</dependency>
CacheOption cacheOption = new CacheOption(128, 1024L);
SQLParserEngine parserEngine = new SQLParserEngine(sql, cacheOption);
ParseASTNode parseASTNode = parserEngine.parse(sql, useCache);
CacheOption cacheOption = new CacheOption(128, 1024L);
SQLParserEngine parserEngine = new SQLParserEngine(sql, cacheOption);
ParseASTNode parseASTNode = parserEngine.parse(sql, useCache);
SQLVisitorEngine sqlVisitorEngine = new SQLVisitorEngine(sql, "STATEMENT", useCache, new Properties());
SQLStatement sqlStatement = sqlVisitorEngine.visit(parseASTNode);
ParseASTNode parseASTNode = parserEngine.parse(sql, useCache);
SQLVisitorEngine sqlVisitorEngine = new SQLVisitorEngine(sql, "FORMAT", useCache, new Properties());
String result = sqlVisitorEngine.visit(parseASTNode);
Example:
| Original SQL | Formatted SQL |
|---|---|
| select a+1 as b, name n from table1 join table2 where id=1 and name='lu’; | SELECT a + 1 AS b, name n FROM table1 JOIN table2 WHERE id = 1 and name = ‘lu’; |
| select id, name, age, sex, ss, yy from table1 where id=1; | SELECT id , name , age , sex , ss , yy FROM table1 WHERE id = 1; |
| select id, name, age, count(*) as n, (select id, name, age, sex from table2 where id=2) as sid, yyyy from table1 where id=1; | SELECT id , name , age , COUNT(*) AS n, ( SELECT id , name , age , sex FROM table2 WHERE id = 2 ) AS sid, yyyy FROM table1 WHERE id = 1; |
| select id, name, age, sex, ss, yy from table1 where id=1 and name=1 and a=1 and b=2 and c=4 and d=3; | SELECT id , name , age , sex , ss , yy FROM table1 WHERE id = 1 and name = 1 and a = 1 and b = 2 and c = 4 and d = 3; |
| ALTER TABLE t_order ADD column4 DATE, ADD column5 DATETIME, engine ss max_rows 10,min_rows 2, ADD column6 TIMESTAMP, ADD column7 TIME; |
ALTER TABLE t_order ADD column4 DATE, ADD column5 DATETIME, ENGINE ss MAX_ROWS 10, MIN_ROWS 2, ADD column6 TIMESTAMP, ADD column7 TIME |
CREATE TABLE IF NOT EXISTS runoob_tbl(runoob_id INT UNSIGNED AUTO_INCREMENT,runoob_title VARCHAR(100) NOT NULL,runoob_author VARCHAR(40) NOT NULL,runoob_test NATIONAL CHAR(40),submission_date DATE,PRIMARY KEY (runoob_id))ENGINE=InnoDB DEFAULT CHARSET=utf8; |
CREATE TABLE IF NOT EXISTS runoob_tbl (runoob_id INT UNSIGNED AUTO_INCREMENT,runoob_title VARCHAR(100) NOT NULL,runoob_author VARCHAR(40) NOT NULL,runoob_test NATIONAL CHAR(40),submission_date DATE,PRIMARY KEY ( runoob_id)) ENGINE = InnoDB DEFAULT CHARSET = utf8; |
| INSERT INTO t_order_item(order_id, user_id, status, creation_date) values (1, 1, ‘insert’, ‘2017-08-08’), (2, 2, ‘insert’, ‘2017-08-08’) ON DUPLICATE KEY UPDATE status = ‘init’; |
INSERT INTO t_order_item (order_id , user_id , status , creation_date) VALUES (1, 1, ‘insert’, ‘2017-08-08’), (2, 2, ‘insert’, ‘2017-08-08’) ON DUPLICATE KEY UPDATE status = ‘init’; |
| INSERT INTO t_order SET order_id = 1, user_id = 1, status = convert(to_base64(aes_encrypt(1, ‘key’)) USING utf8) ON DUPLICATE KEY UPDATE status = VALUES(status); |
INSERT INTO t_order SET order_id = 1, user_id = 1, status = CONVERT(to_base64(aes_encrypt(1 , ‘key’)) USING utf8) ON DUPLICATE KEY UPDATE status = VALUES(status); |
| INSERT INTO t_order (order_id, user_id, status) SELECT order_id, user_id, status FROM t_order WHERE order_id = 1; | INSERT INTO t_order (order_id , user_id , status) SELECT order_id , user_id , status FROM t_order WHERE order_id = 1; |