Principle
Principle
Consider about these challenges of Sharding-Scaling, the solution is: Use two database clusters temporarily, and switch after the scaling is completed.
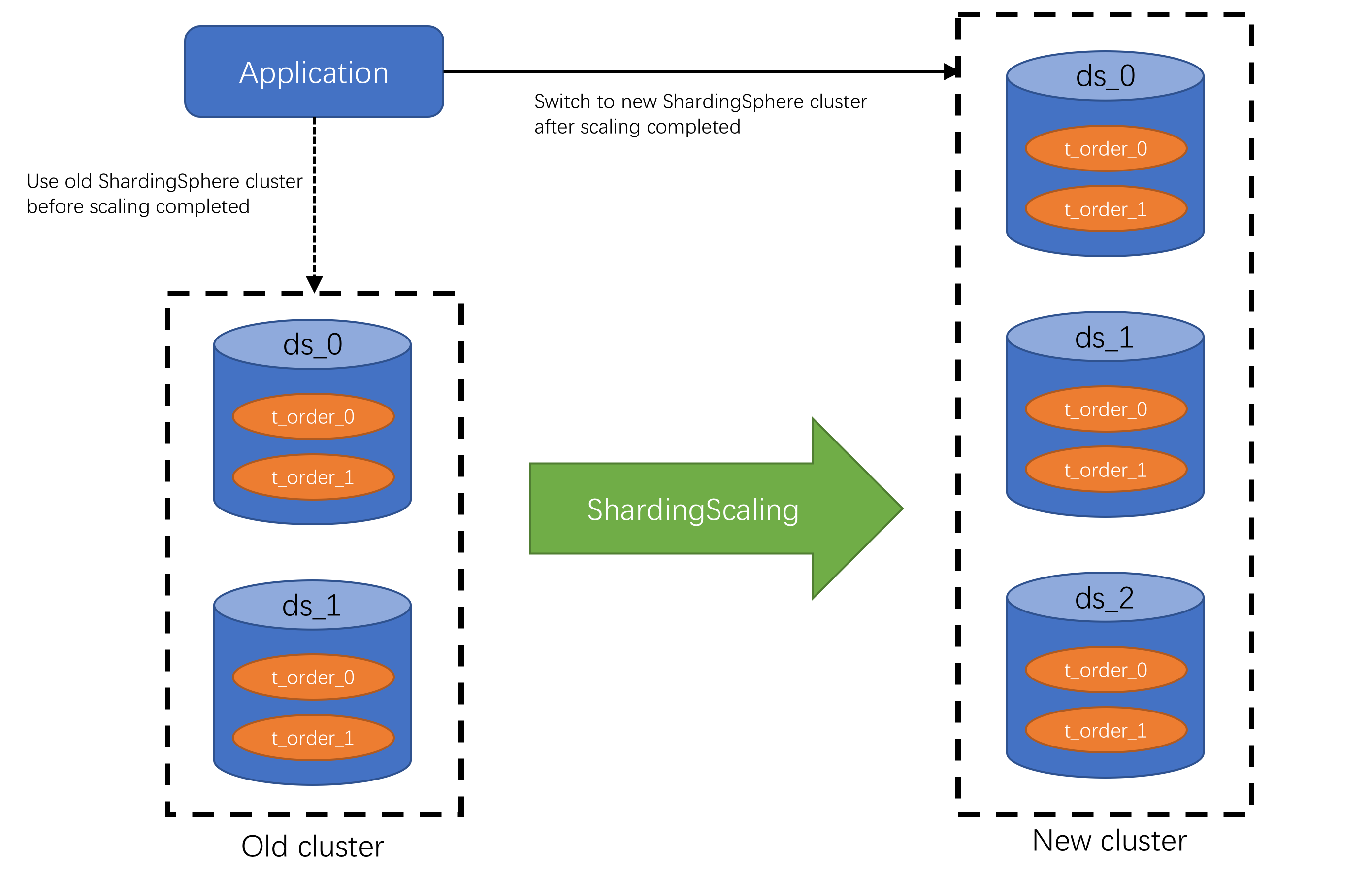
Advantages:
- No effect for origin data during scaling.
- No risk for scaling failure.
- No limited by sharding strategies.
Disadvantages:
- Redundant servers during scaling.
- All data needs to be moved.
Sharding-Scaling will analyze the sharding rules and extract information like datasource and data nodes. According the sharding rules, Sharding-Scaling create a scaling job with 4 main phases.
- Preparing Phase.
- Inventory Phase.
- Incremental Phase.
- Switching Phase.
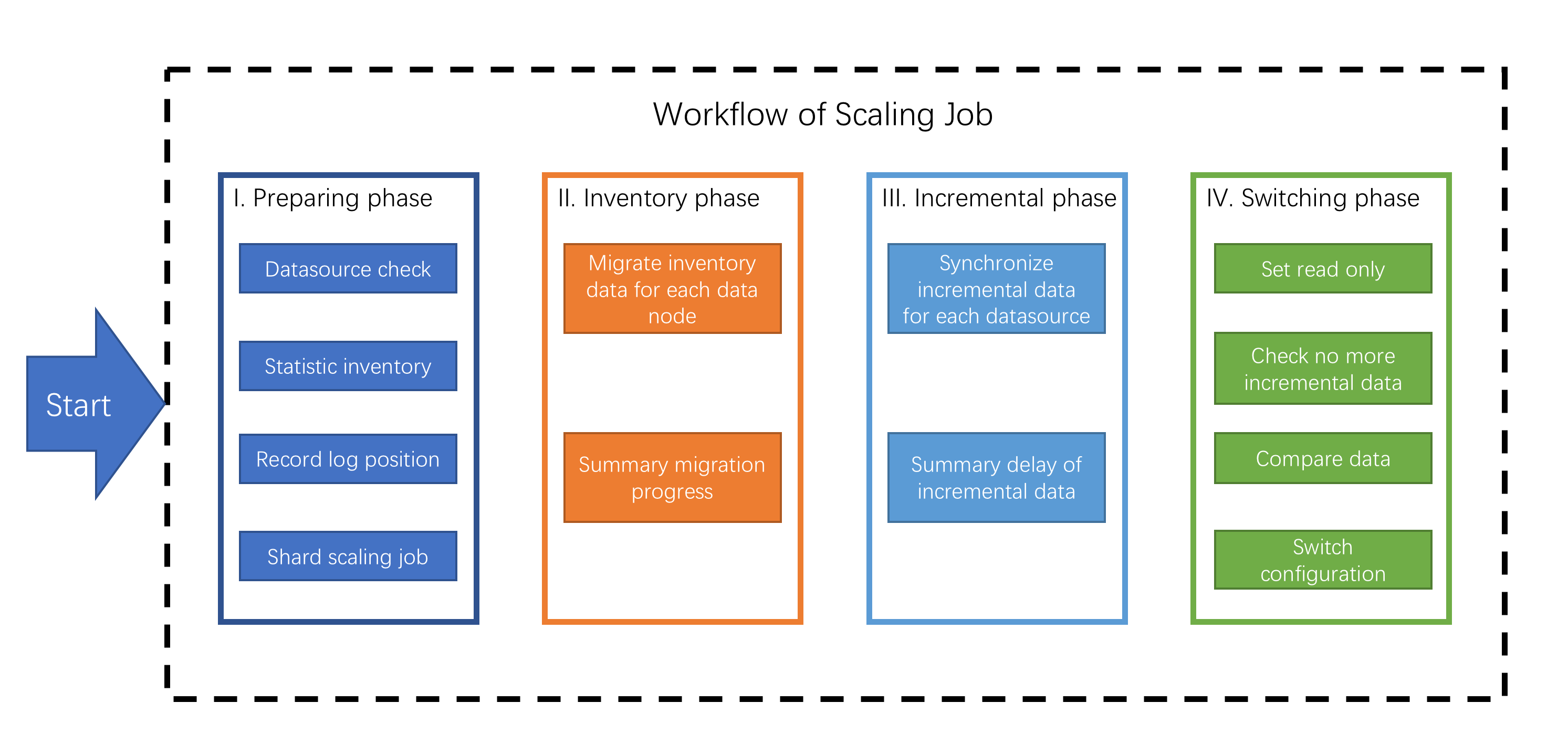
Preparing Phase
Sharding-Scaling will check the datasource connectivity and permissions, statistic the amount of inventory data, record position of log, shard tasks based on amount of inventory data and the parallelism set by the user.
Inventory Phase
Executing the Inventory data migration tasks sharded in preparing phase. Sharding-Scaling uses JDBC to query inventory data directly from data nodes and write to the new cluster using new rules.
Incremental Phase
The data in data nodes is still changing during the inventory phase, so Sharding-Scaling need to synchronize these incremental data to new data nodes. Different databases have different implementations, but generally implemented by change data capture function based on replication protocols or WAL logs.
- MySQL:subscribe and parse binlog.
- PostgreSQL:official logic replication test_decoding.
These captured incremental data, ShardingSphere also write to the new cluster using new rules.
Switching Phase
In this phase, there may be a temporary read only time, make the data in old data nodes static so that the incremental phase complete fully. The read only time is range seconds to minutes, it depends on the amount of data and the checking data. After finished, ShardingSphere can switch the configuration by register-center and config-center, make application use new sharding rule and new data nodes.