Data Masking
Background
Security control has always been a crucial link of orchestration; data masking falls into this category. For both Internet enterprises and traditional sectors, data security has always been a highly valued and sensitive topic. Data masking refers to transforming some sensitive information through masking rules to safely protect the private data. Data involves client’s security or business sensibility, such as ID number, phone number, card number, client number and other personal information, requires data masking according to relevant regulations.
Because of that, ShardingSphere has provided data masking, which stores users’ sensitive information in the database after encryption. When users search for them, the information will be decrypted and returned to users in the original form.
ShardingSphere has made the encryption and decryption processes totally transparent to users, who can store desensitized data and acquire original data without any awareness. In addition, ShardingSphere has provided internal masking algorithms, which can be directly used by users. In the same time, we have also provided masking algorithm related interfaces, which can be implemented by users themselves. After simple configurations, ShardingSphere can use algorithms provided by users to perform encryption, decryption and masking.
Preface
Apache ShardingSphere is an ecosystem of open source distributed database middleware solutions. It consists of Sharding-JDBC, Sharding-Proxy, and Sharding-Sidecar (in planning) which are independent of each other, but can be used in mixed deployment. All of these can provide standardized data sharding, distributed transactions, and distributed governance functions, and can be applied to various situation such as Java homogeneous, heterogeneous languages, containers, cloud native, and so on.
The data encryption module belongs to the sub-function module under the core function of ShardingSphere distributed governance. It parses the SQL input by the user and rewrites the SQL according to the encryption configuration provided by the user, thereby encrypting the original data and storing the original data and store the original data (optional) and cipher data to database at the same time. When the user queries the data, it takes the cipher data from the database and decrypts it, and finally returns the decrypted original data to the user. Apache ShardingSphere distributed database middleware automates and transparentizes the process of data encryption, so that users do not need to pay attention to the details of data decryption and use decrypted data like ordinary data. In addition, ShardingSphere can provide a relatively complete set of solutions for the encryption of online services or the encryption function of new services.
Demand Analysis
The demand for data encryption is generally divided into two situations in real business scenarios:
-
When the new business start to launch, and the security department stipulates that the sensitive information related to users, such as banks and mobile phone numbers, should be encrypted and stored in the database, and then decrypted when used. Because it is a brand new system, there is no inventory data cleaning problem, so the implementation is relatively simple.
-
For the service has been launched, and plaintext has been stored in the database before. The relevant department suddenly needs to encrypt the data from the on-line business. This scenario generally needs to deal with three issues as followings:
a) How to encrypt the historical data, a.k.a.s clean data.
b) How to encrypt the newly added data and store it in the database without changing the business SQL and logic; then decrypt the taken out data when use it.
c) How to securely, seamlessly and transparently migrate plaintext and ciphertext data between business systems
Detailed Process
Overall Architecture
Encrypt-JDBC provided by ShardingSphere are deployed with business codes. Business parties need to perform JDBC programming for Encrypt-JDBC. Since Encrypt-JDBC implements all JDBC standard interfaces, business codes can be used without additional modification. At this time, Encrypt-JDBC is responsible for all interactions between the business code and the database. Business only needs to provide encryption rules. ** As a bridge between the business code and the underlying database, Encrypt-JDBC can intercept user behavior and interact with the database after transforming the user behavior. **
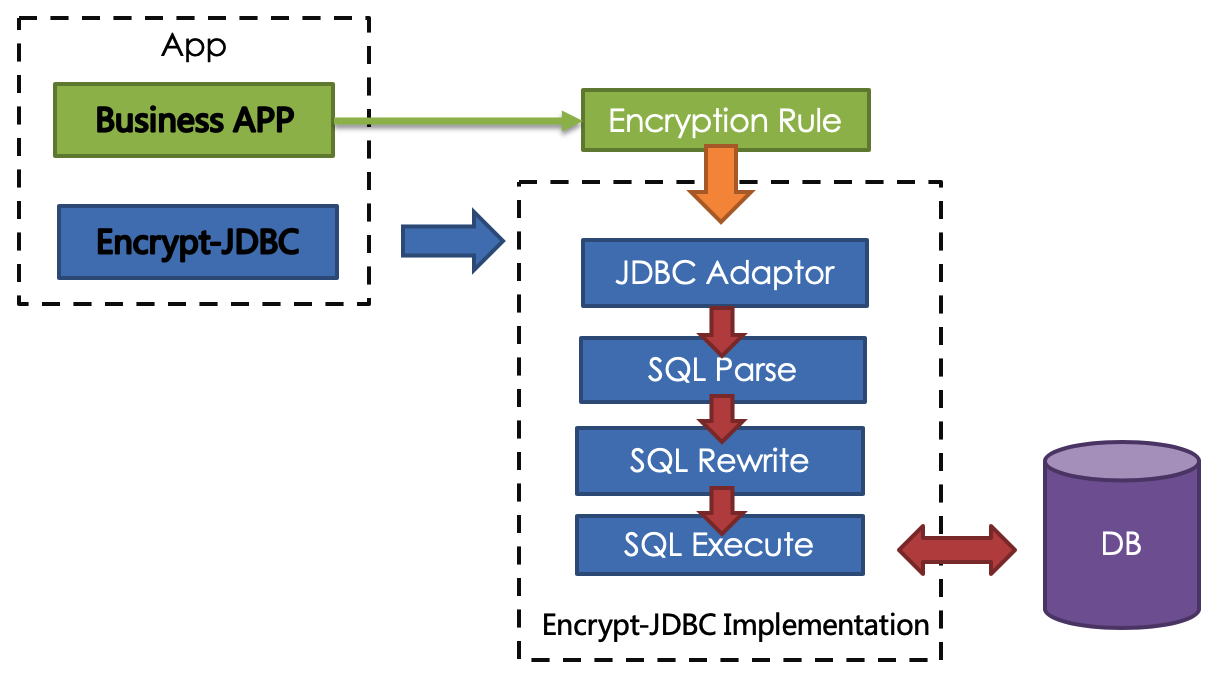
Encrypt-JDBC intercepts SQL initiated by user, analyzes and understands SQL behavior through the SQL syntax parser.According to the encryption rules passed by the user, find out the fields that need to be encrypted/decrypt and the encryptor/decryptor used to encrypt/decrypt the target fields, and then interact with the underlying database.ShardingSphere will encrypt the plaintext requested by the user and store it in the underlying database; and when the user queries, the ciphertext will be taken out of the database for decryption and returned to the end user.ShardingSphere shields the encryption of data, so that users do not need to perceive the process of parsing SQL, data encryption, and data decryption, just like using ordinary data.
Encryption Rule
Before explaining the whole process in detail, we need to understand the encryption rules and configuration, which is the basis of understanding the whole process. The encryption configuration is mainly divided into four parts: data source configuration, encryptor configuration, encryption table configuration, and query attribute configuration. The details are shown in the following figure:
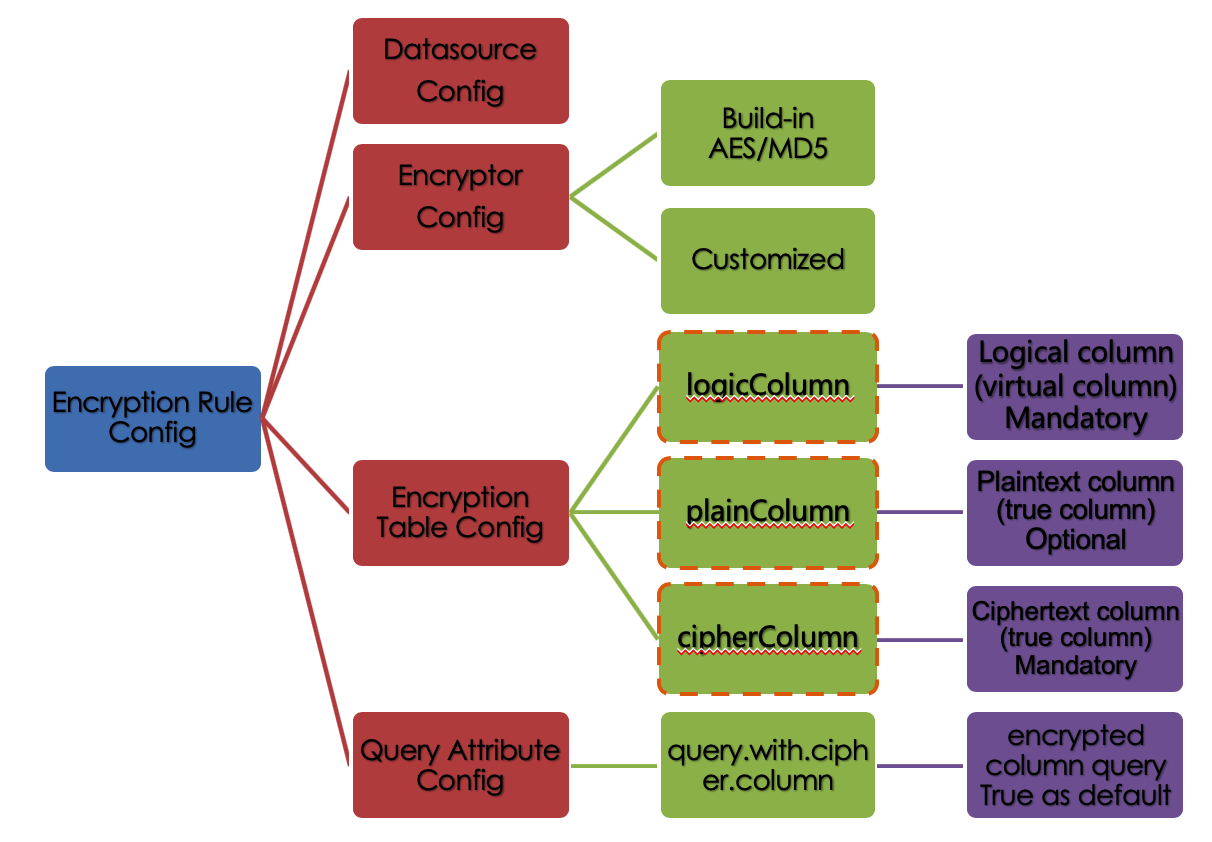
Datasource Configuration:The configuration of DataSource.
Encryptor Configuration:What kind of encryption strategy to use for encryption and decryption. Currently ShardingSphere has two built-in encryption/decryption strategies: AES / MD5. Users can also implement a set of encryption/decryption algorithms by implementing the interface provided by ShardingSphere.
Encryption Table Configuration:Show the ShardingSphere data table which column is used to store cipher column data (cipherColumn), which column is used to store plain text data (plainColumn), and which column users want to use for SQL writing (logicColumn)
How to understand
Which column do users want to use to write SQL (logicColumn)?We can understand according to the meaning of Encrypt-JDBC. The ultimate goal of Encrypt-JDBC is to shield the encryption of the underlying data, that is, we do not want users to know how the data is encrypted/decrypted, how to store plaintext data in plainColumn, and ciphertext data in cipherColumn. In other words, we do not even want users to know the existence and use of plainColumn and cipherColumn. Therefore, we need to provide users with a column in conceptual. This column can be separated from the real column of the underlying database. It can be a real column in the database table or not, so that the user can freely change the plainColumn and The column name of cipherColumn. Or delete plainColumn and choose to never store plain text and only store cipher text. As long as the user’s SQL is written according to this logical column, and the correct mapping relationship between logicColumn and plainColumn, cipherColumn is given in the encryption rule.
Why do you do this? The answer is at the end of the article, that is, to enable the online services to seamlessly, transparently, and safely carry out data encryption migration.
Query Attribute configuration:When the plaintext data and ciphertext data are stored in the underlying database table at the same time, this attribute switch is used to decide whether to directly query the plaintext data in the database table to return, or to query the ciphertext data and decrypt it through Encrypt-JDBC to return.
Encryption Process
For example, if there is a table in the database called t_user, there are actually two fields pwd_plain in this table, used to store plain text data, pwd_cipher, used to store cipher text data, and define logicColumn as pwd. Then, when writing SQL, users should write to logicColumn, that is, INSERT INTO t_user SET pwd = ‘123’. ShardingSphere receives the SQL, and through the encryption configuration provided by the user, finds that pwd is a logicColumn, so it decrypt the logical column and its corresponding plaintext data. As can be seen that ** ShardingSphere has carried out the column-sensitive and data-sensitive mapping conversion of the logical column facing the user and the plaintext and ciphertext columns facing the underlying database. **As shown below:
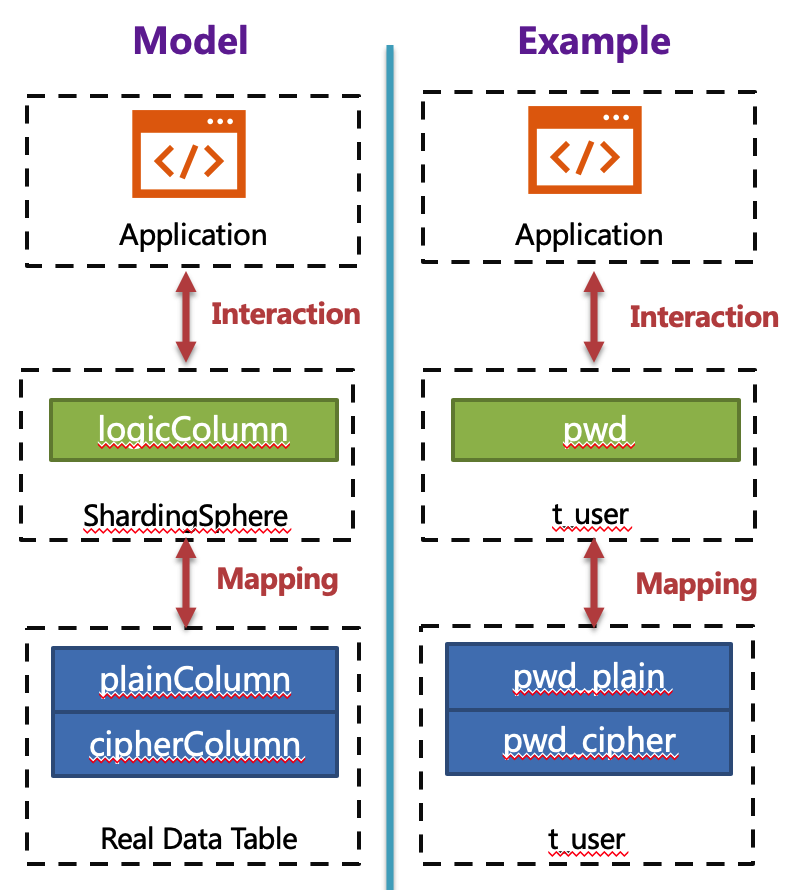
** This is also the core meaning of Encrypt-JDBC, which is to separate user SQL from the underlying data table structure according to the encryption rules provided by the user, so that the SQL writter by user no longer depends on the actual database table structure. The connection, mapping, and conversion between the user and the underlying database are handled by ShardingSphere. ** Why should we do this? It is still the same : in order to enable the online business to seamlessly, transparently and safely perform data encryption migration.
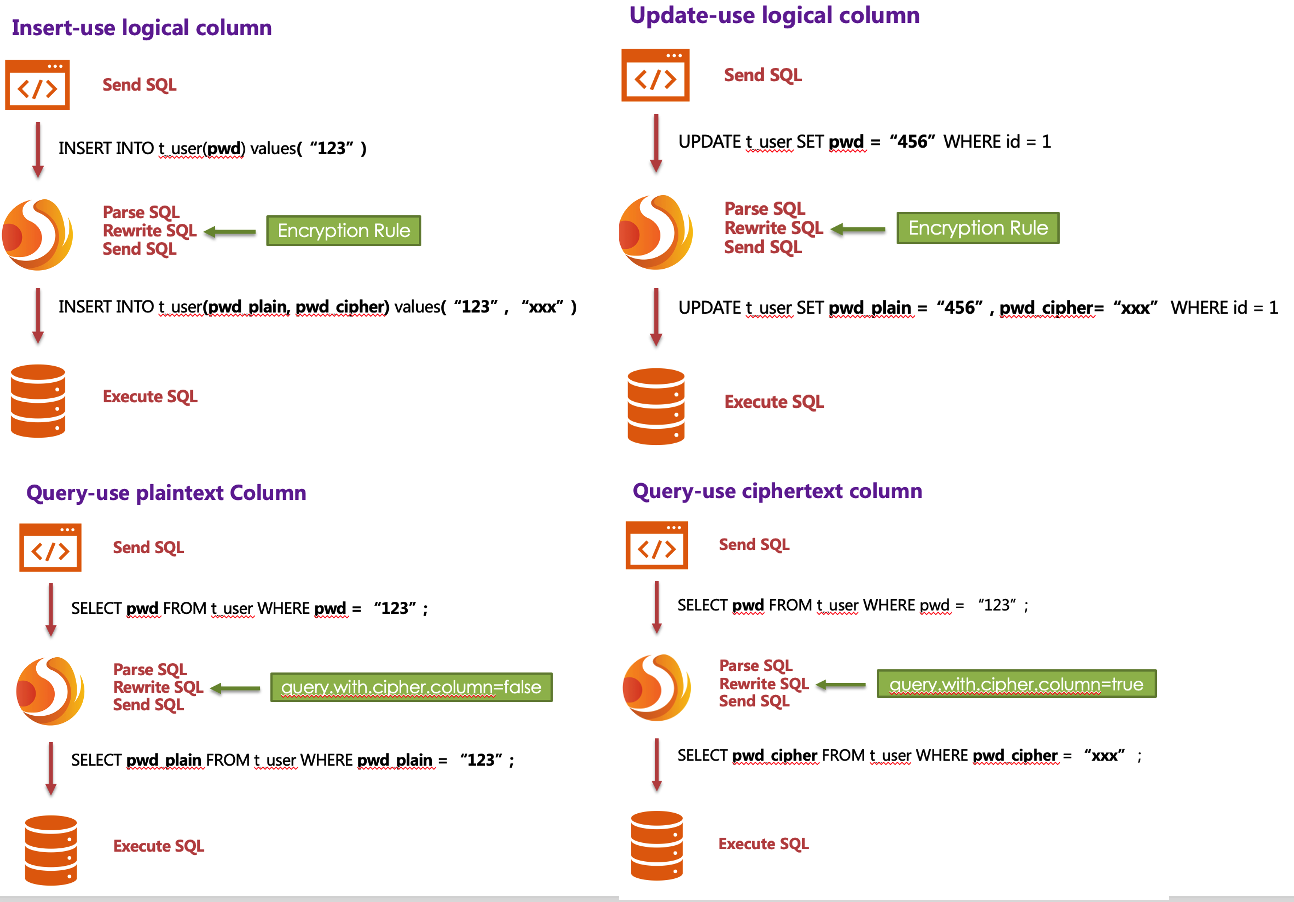
In order to make the reader more clearly understand the core processing flow of Encrypt-JDBC, the following picture shows the processing flow and conversion logic when using Encrypt-JDBC to add, delete, modify and check, as shown in the following figure.
Detailed Solution
After understanding the ShardingSphere encryption process, you can combine the encryption configuration and encryption process with the actual scenario. All design and development are to solve the problems encountered in business scenarios. So for the business scenario requirements mentioned earlier, how should ShardingSphere be used to achieve business requirements?
New Business
Business scenario analysis: The newly launched business is relatively simple because everything starts from scratch and there is no historical data cleaning problem.
Solution description: After selecting the appropriate encryptor, such as AES, you only need to configure the logical column (write SQL for users) and the ciphertext column (the data table stores the ciphertext data). It can also be different **. The recommended configuration is as follows (shown in Yaml format):
encryptRule:
encryptors:
aes_encryptor:
type: aes
props:
aes.key.value: 123456abc
tables:
t_user:
columns:
pwd:
cipherColumn: pwd
encryptor: aes_encryptor
With this configuration, Encrypt-JDBC only needs to convert logicColumn and cipherColumn. The underlying data table does not store plain text, only cipher text. This is also a requirement of the security audit part. If users want to store plain text and cipher text together in the database, they just need to add plainColumn configuration. The overall processing flow is shown below:
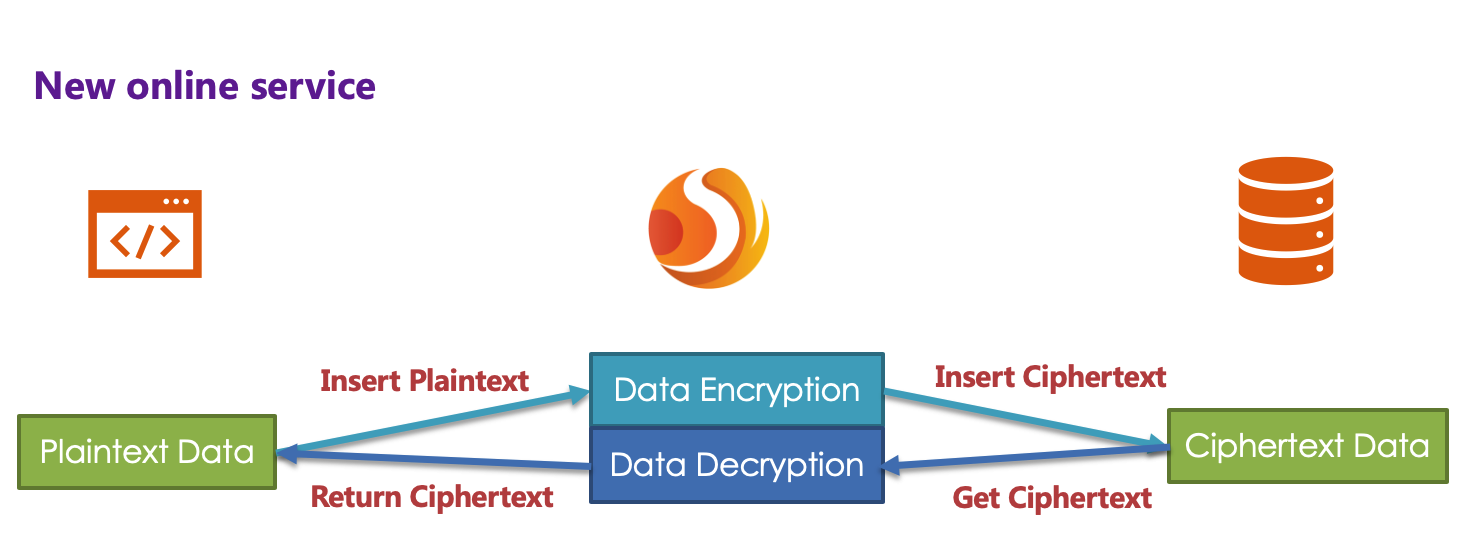
Online Business Transformation
Business scenario analysis: As the business is already running online, there must be a large amount of plain text historical data stored in the database. The current challenges are how to enable historical data to be encrypted and cleaned, how to enable incremental data to be encrypted, and how to allow businesses to seamlessly and transparently migrate between the old and new data systems.
Solution description: Before providing a solution, let ’s brainstorm: First, if the old business needs to be desensitized, it must have stored very important and sensitive information. This information has a high gold content and the business is relatively important. If it is broken, the whole team KPI is over. Therefore, it is impossible to suspend business immediately, prohibit writing of new data, encrypt and clean all historical data with an encrypter, and then deploy the previously reconstructed code online, so that it can encrypt and decrypt online and incremental data. Such a simple and rough way, based on historical experience, will definitely not work.
Then another relatively safe approach is to rebuild a pre-release environment exactly like the production environment, and then encrypt the ** Inventory plaintext data ** of the production environment through the relevant migration and washing tools and store it in the pre-release environment. The ** Increment data ** is encrypted by tools such as MySQL master-slave replication and the business party ’s own development, encrypted and stored in the database of the pre-release environment, and then the refactored code can be deployed to the pre-release environment. In this way, the production environment is a set of environment for ** modified/queries with plain text as the core **; the pre-release environment is a set of ** encrypt/decrypt queries modified with ciphertext as the core **. After comparing for a period of time, the production flow can be cut into the pre-release environment at night. This solution is relatively safe and reliable, but it takes more time, manpower, capital, and costs. It mainly includes: pre-release environment construction, production code rectification, and related auxiliary tool development. Unless there is no way to go, business developers generally go from getting started to giving up.
Business developers must hope: reduce the burden of capital costs, do not modify the business code, and be able to safely and smoothly migrate the system. So, the encryption function module of ShardingSphere was born. It can be divided into three steps:
-
Before system migration
Assuming that the system needs to encrypt the pwd field of t_user, the business side uses Encrypt-JDBC to replace the standardized JDBC interface, which basically requires no additional modification (we also provide SpringBoot, SpringNameSpace, Yaml and other access methods to achieve different services demand). In addition, demonstrate a set of encryption configuration rules, as follows:
encryptRule: encryptors: aes_encryptor: type: aes props: aes.key.value: 123456abc tables: t_user: columns: pwd: plainColumn: pwd cipherColumn: pwd_cipher encryptor: aes_encryptor props: query.with.cipher.column: falseAccording to the above encryption rules, we need to add a column called pwd_cipher in the t_user table, that is, cipherColumn, which is used to store ciphertext data. At the same time, we set plainColumn to pwd, which is used to store plaintext data, and logicColumn is also set to pwd . Because the previous SQL was written using pwd, that is, the SQL was written for logical columns, so the business code did not need to be changed. Through Encrypt-JDBC, for the incremental data, the plain text will be written to the pwd column, and the plain text will be encrypted and stored in the pwd_cipher column. At this time, because query.with.cipher.column is set to false, for business applications, the plain text column of pwd is still used for query storage, but the cipher text data of the new data is additionally stored on the underlying database table pwd_cipher. The processing flow is shown below:
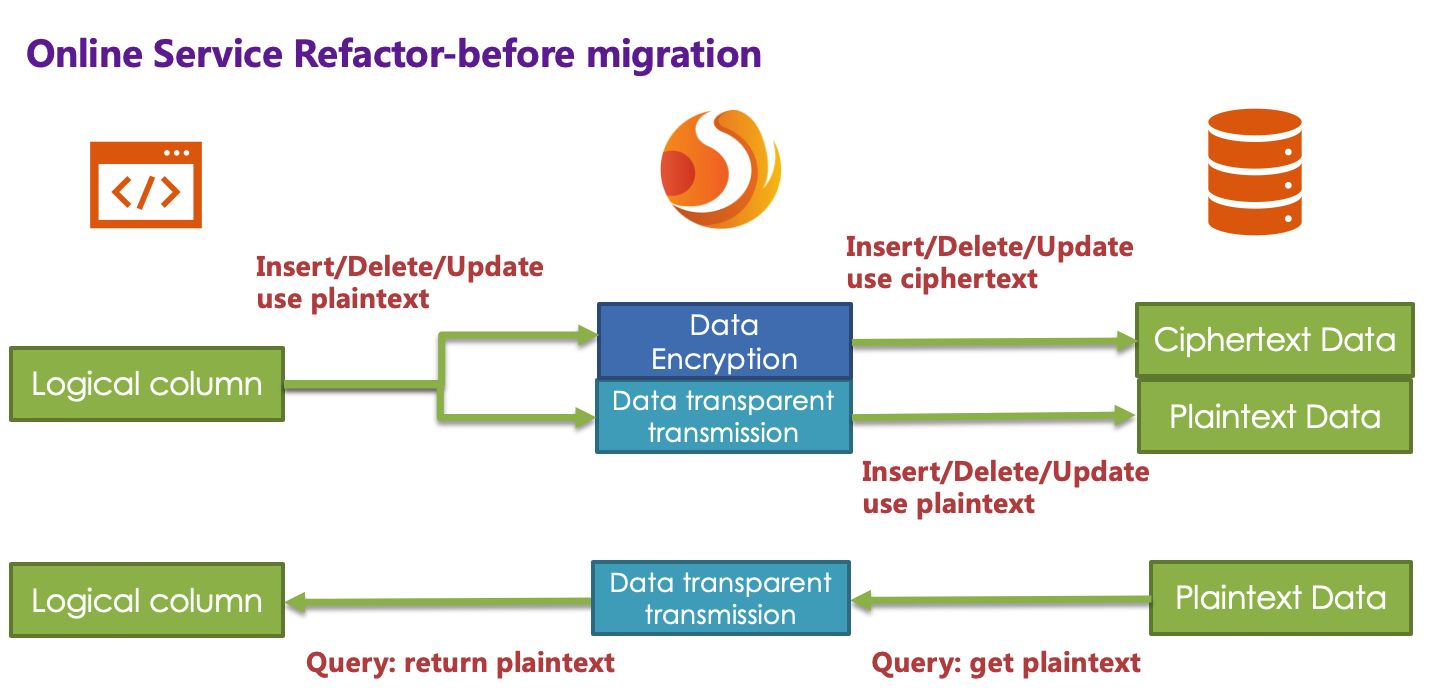
When the newly added data is inserted, it is encrypted as ciphertext data through Encrypt-JDBC and stored in the cipherColumn. Now it is necessary to process historical plaintext inventory data. ** As Apache ShardingSphere currently does not provide the corresponding migration and washing tools, the business party needs to encrypt and store the plain text data in pwd to pwd_cipher. **
-
During system migration
The incremental data has been stored by Encrypt-JDBC in the ciphertext column and the plaintext is stored in the plaintext column; after the historical data is encrypted and cleaned by the business party itself, the ciphertext is also stored in the ciphertext column. That is to say, the plaintext and the ciphertext are stored in the current database. Since the query.with.cipher.column = false in the configuration item, the ciphertext has never been used. Now we need to set the query.with.cipher.column in the encryption configuration to true in order for the system to cut the ciphertext data for query. After restarting the system, we found that the system business is normal, but Encrypt-JDBC has started to extract the ciphertext data from the database, decrypt it and return it to the user; and for the user’s insert, delete and update requirements, the original data will still be stored The plaintext column, the encrypted ciphertext data is stored in the ciphertext column.
Although the business system extracts the data in the ciphertext column and returns it after decryption; however, it will still save a copy of the original data to the plaintext column during storage. Why? The answer is: in order to be able to roll back the system. ** Because as long as the ciphertext and plaintext always exist at the same time, we can freely switch the business query to cipherColumn or plainColumn through the configuration of the switch item. ** In other words, if the system is switched to the ciphertext column for query, the system reports an error and needs to be rolled back. Then just set query.with.cipher.column = false, Encrypt-JDBC will restore, that is, start using plainColumn to query again. The processing flow is shown in the following figure:
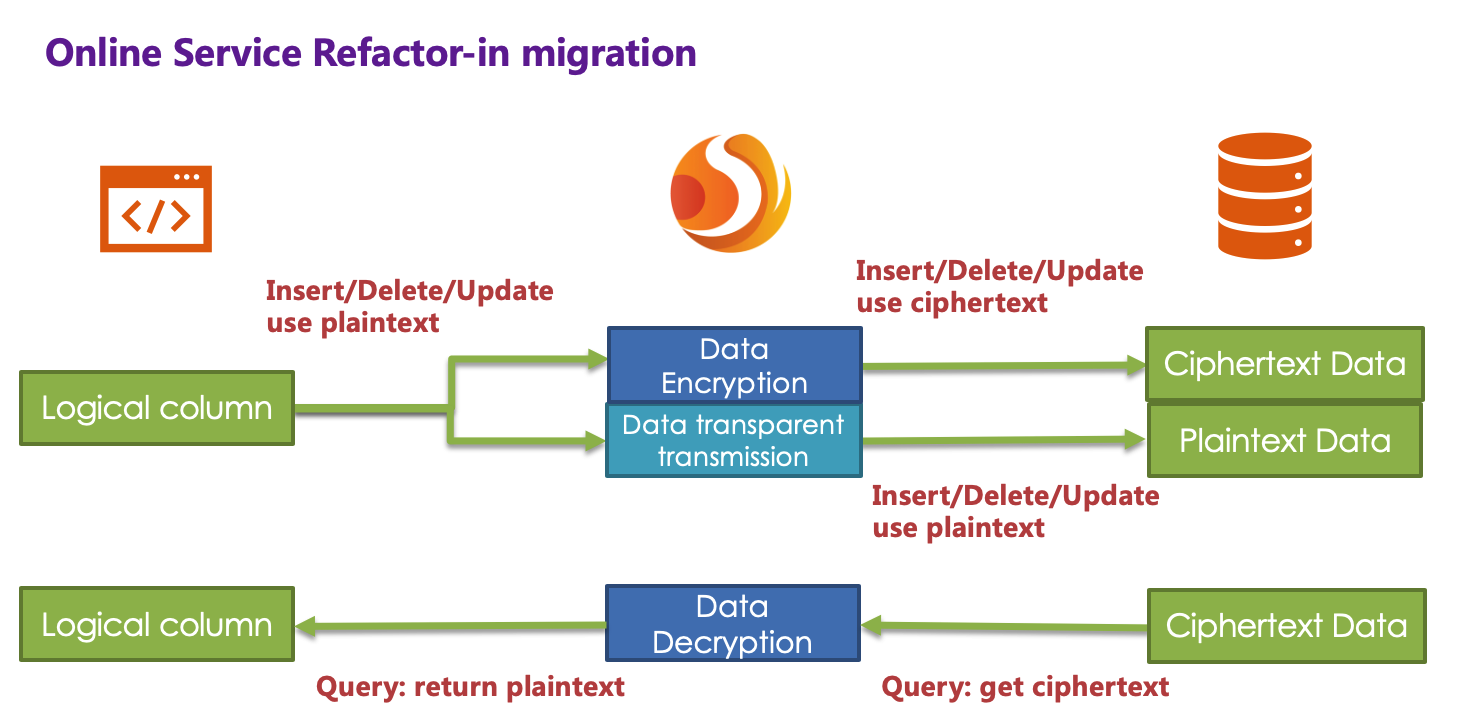
-
After system migration
Due to the requirements of the security audit department, it is generally impossible for the business system to keep the plaintext and ciphertext columns of the database permanently synchronized. We need to delete the plaintext data after the system is stable. That is, we need to delete plainColumn (ie pwd) after system migration. The problem is that now the business code is written for pwd SQL, delete the pwd in the underlying data table stored in plain text, and use pwd_cipher to decrypt to get the original data, does that mean that the business side needs to rectify all SQL, thus Do not use the pwd column that is about to be deleted? Remember the core meaning of our Encrypt-JDBC?
This is also the core meaning of Encrypt-JDBC. According to the encryption rules provided by the user, the user SQL is separated from the underlying database table structure, so that the user’s SQL writing no longer depends on the actual database table structure. The connection, mapping, and conversion between the user and the underlying database are handled by ShardingSphere.
Yes, because of the existence of logicColumn, users write SQL for this virtual column. Encrypt-JDBC can map this logical column and the ciphertext column in the underlying data table. So the encryption configuration after migration is:
encryptRule: encryptors: aes_encryptor: type: aes props: aes.key.value: 123456abc tables: t_user: columns: pwd: # pwd与pwd_cipher的转换映射 cipherColumn: pwd_cipher encryptor: aes_encryptor props: query.with.cipher.column: true
The processing flow is as follows:
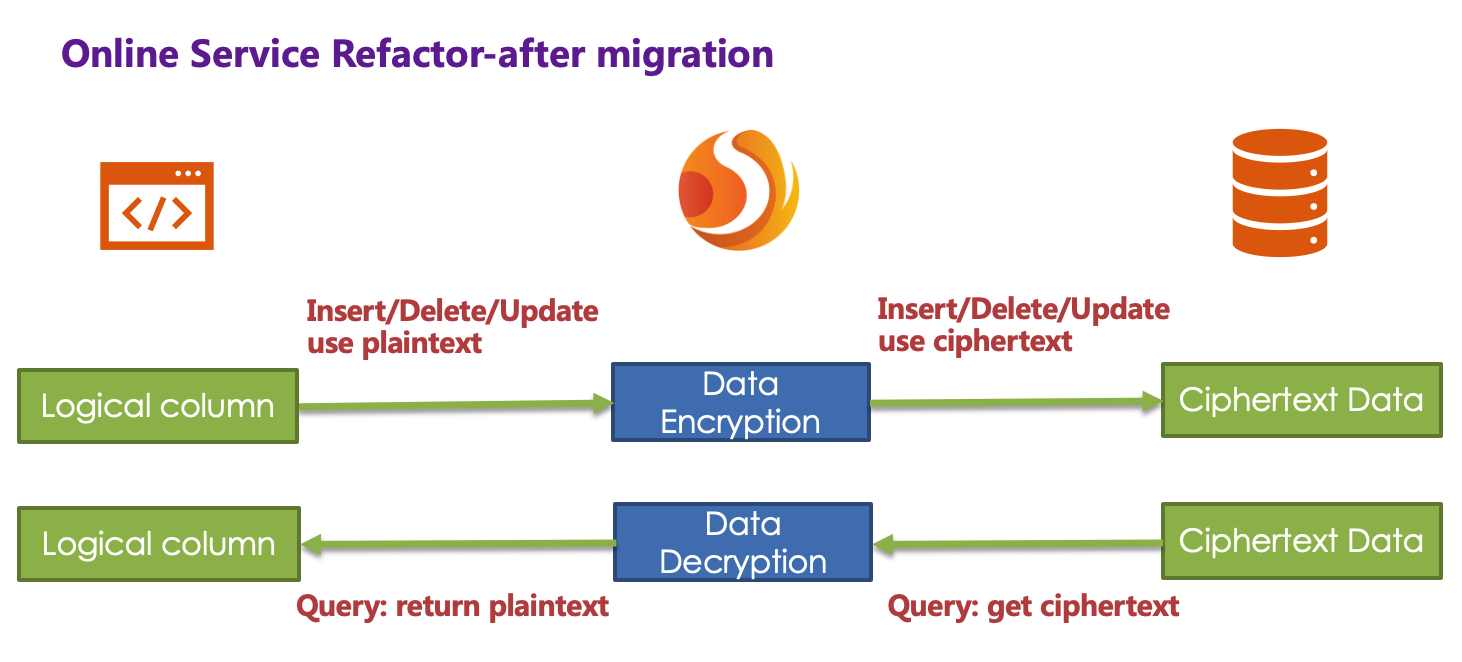
So far, the online service encryption and rectification solutions have all been demonstrated. We provide Java, Yaml, SpringBoot, SpringNameSpace multiple ways for users to choose to use, and strive to fulfil business requirements. The solution has been continuously launched on JD Digits, providing internal basic service support.
The advantages of Middleware encryption service
- Automated & transparent data encryption process, users do not need to pay attention to the implementation details of encryption.
- Provide a variety of built-in, third-party (AKS) encryption strategies, users only need to modify the configuration to use.
- Provides a encryption strategy API interface, users can implement the interface to use a custom encryption strategy for data encryption.
- Support switching different encryption strategies.
- For online services, it is possible to store plaintext data and ciphertext data synchronously, and decide whether to use plaintext or ciphertext columns for query through configuration. Without changing the business query SQL, the on-line system can safely and transparently migrate data before and after encryption.
Description of applicable scenarios
- User projects are developed in Java.
- The back-end databases are MySQL, Oracle, PostgreSQL, and SQLServer.
- The user needs to encrypt one or more columns in the database table (data encryption & decryption).
- Compatible with all commonly used SQL.
Limitation
- Users need to deal with the original inventory data and wash numbers in the database.
- Use encryption function + sub-library sub-table function, some special SQL is not supported, please refer to SQL specification。
- Encryption fields cannot support comparison operations, such as: greater than less than, ORDER BY, BETWEEN, LIKE, etc.
- Encryption fields cannot support calculation operations, such as AVG, SUM, and calculation expressions.
Solution
ShardingSphere has provided two data masking solutions, corresponding to two ShardingSphere encryption and decryption interfaces, i.e., ShardingEncryptor and ShardingQueryAssistedEncryptor.
On the one hand, ShardingSphere has provided internal encryption and decryption implementations for users, which can be used by them only after configuration. On the other hand, to satisfy users’ requirements for different scenarios, we have also opened relevant encryption and decryption interfaces, according to which, users can provide specific implementation types. Then, after simple configurations, ShardingSphere can use encryption and decryption solutions defined by users themselves to desensitize data.
ShardingEncryptor
The solution has provided two methods encrypt() and decrypt() to encrypt/decrypt data for encryption.
When users INSERT, DELETE and UPDATE, ShardingSphere will parse, rewrite and route SQL according to the configuration. It will also use encrypt() to encrypt data and store them in the database. When using SELECT, they will decrypt sensitive data from the database with decrypt() reversely and return them to users at last.
Currently, ShardingSphere has provided two types of implementations for this kind of masking solution, MD5 (irreversible) and AES (reversible), which can be used after configuration.
ShardingQueryAssistedEncryptor
Compared with the first masking scheme, this one is more secure and complex. Its concept is: even the same data, two same user passwords for example, should not be stored as the same desensitized form in the database. It can help to protect user information and avoid credential stuffing.
This scheme provides three functions to implement, encrypt(), decrypt() and queryAssistedEncrypt(). In encrypt() phase, users can set some variable, timestamp for example, and encrypt a combination of original data + variable. This method can make sure the encrypted masking data of the same original data are different, due to the existence of variables. In decrypt() phase, users can use variable data to decrypt according to the encryption algorithms set formerly.
Though this method can indeed increase data security, another problem can appear with it: as the same data is stored in the database in different content, users may not be able to find out all the same original data with equivalent query (SELECT FROM table WHERE encryptedColumnn = ?) according to this encryption column.Because of it, we have brought out assistant query column, which is generated by queryAssistedEncrypt(). Different from decrypt(), this method uses another way to encrypt the original data; but for the same original data, it can generate consistent encryption data. Users can store data processed by queryAssistedEncrypt() to assist the query of original data. So there may be one more assistant query column in the table.
queryAssistedEncrypt() and encrypt() can generate and store different encryption data; decrypt() is reversible and queryAssistedEncrypt() is irreversible. So when querying the original data, we will parse, rewrite and route SQL automatically. We will also use assistant query column to do WHERE queries and use decrypt() to decrypt encrypt() data and return them to users. All these can not be felt by users.
For now, ShardingSphere has abstracted the concept to be an interface for users to develop rather than providing accurate implementation for this kind of masking solution. ShardingSphere will use the accurate implementation of this solution provided by users to desensitize data.
Continuance
This article describes how to use Encrypt-JDBC, one of the ShardingSphere products, SpringBoot, SpringNameSpace are also could be the access form , etc. This form of access mainly focus to Java homogeneous, and is deployed together with business code In a production environment. For heterogeneous languages, ShardingSphere also provides Encrypt-Proxy client. Encrypt-Proxy is a server-side product that implements the binary protocol of MySQL and PostgreSQL. Users can independently deploy the Encrypt-Proxy service, User can access this virtual database server with encryption through third-party database management tools(e.g. Navicat), JAVA connection pool or the command line, just like access ordinary MySQL and PostgreSQL databases.
The encryption function belongs to distributed governance of Apache ShardingSphere. In fact, the Apache ShardingSphere ecosystem also has other more powerful capabilities, such as data sharding, read-write separation, distributed transactions, and monitoring governance. You can even choose any combination of these functions, such as encryption + data sharding, or data sharding + read-write separation, or monitoring governance + data sharding. In addition to the combination of these functions, ShardingSphere also provides various access forms, such as Sharding-JDBC and Sharding-Proxy for different situations.