Distributed Primary Key
Motivation
In traditional database software development, the automatic primary key generation technology is a basic requirement. All kinds of databases have provided corresponding support for this requirement, such as MySQL auto-increment key, Oracle auto-increment sequence and so on. It is a tricky problem that different data nodes only generate one primary key after sharding. Auto-increment keys in different physical tables within the same logic table can not perceive each other and thereby generate repeated primary keys. Though it is possible to avoid clashes by restricting the initiative value and increase step of auto-increment key, but introducing extra operation rules can make the solution lack integrity and scalability.
Currently, there are many third-party solutions that can solve this problem perfectly, such as (UUID and others) relying on some particular algorithms to generate unrepeated keys, or leading in primary key generation services. But it is for this diversity that ShardingSphere may restrict its own development if relying on any solution.
For above reasons, ShardingSphere uses interfaces to access generated primary keys and separates the detailed underlying primary key generation.
Default Distributed Primary Key Generator
ShardingSphere provides flexible distributed primary key generation strategies. Users can configure the primary key generation strategy of each table in sharding rule configuration module, with default snowflake algorithm generating 64bit long integral data.
As the distributed primary key generation algorithm published by Twitter, snowflake algorithm can ensure the primary key of different processes are not repeated and those of the same process are ordered.
In the same process, it makes sure of unrepeated ID through time at first, or through order if the time is identical. In the same time,with monotonously increasing time, if servers are adjusted to be generally synchronized, it can be assumed that generated primary keys are overall ordered in distributed environment. This can guarantee the effectiveness in index field insertion, like the primary key of MySQL Innodb storage engine.
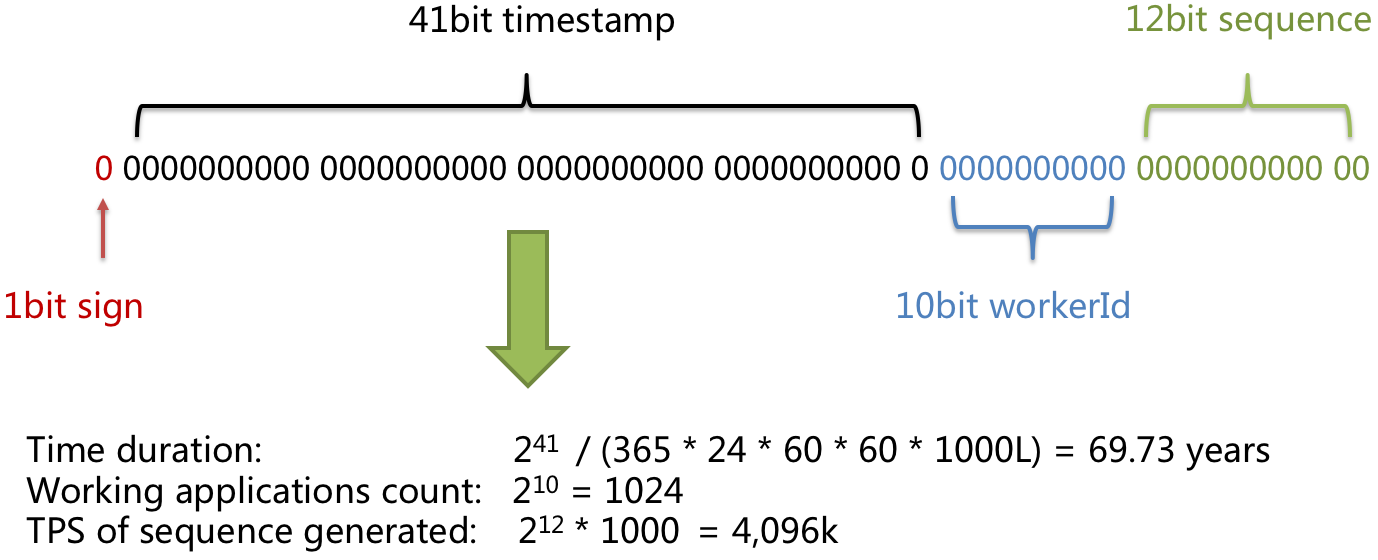
In the primary key generated with snowflake algorithm, binary form has 4 parts, and from high to low they are 1 bit sign, 41bit timestamp, 10bit work ID and 12bit sequence number.
- sign bit (1bit)
Reserved sign bit, constantly to be zero.
- timestamp bit (41bit)
41bit timestamp can contain 2 to the power of 41 milliseconds. One year can uses 365 * 24 * 60 * 60 * 1000 milliseconds. We can see from the calculation:
Math.pow(2, 41) / (365 * 24 * 60 * 60 * 1000L);
The result is approximately equal to 69.73 years. The time of ShardingSphere snowflake algorithm starts from November 1st, 2016, and can be used until the year of 2086, which we believe can satisfy the requirement of most systems.
- work ID bit (10bit)
The sign is only in Java process. If applied in distributed deployment, each work ID should be different.
The default value is 0 and can be set by calling for statistic method DefaultKeyGenerator.setWorkerId().
- sequence number bit (12bit)
The sequence number is used to generate different IDs in a millisecond. If the number generated in that millisecond exceeds 4,096 (2 to the power of 12), the generator will wait till the next millisecond to continue.
Clock-Back
Server clock-back can lead to the generation of repeated sequence, so the default distributed primary key generator has provided a maximumly tolerant clock-back millisecond number.
If the clock-back time has exceeded it, the program will report an error.
If it is within the tolerance range, the generator will wait till after the last generation time and then continue to work.
The default value of maximumly tolerant clock-back millisecond is 0 and can be set by calling for statistic method DefaultKeyGenerator.setMaxTolerateTimeDifferenceMilliseconds().
Please refer to the following picture for the detailed structure of snowflake algorithm primary key.