Apache ShardingSphere is an open source ecosystem that allows you to transform any database into a distributed database system. The project includes a JDBC and a Proxy, and its core adopts a micro-kernel and pluggable architecture. Thanks to its plugin-oriented architecture, features can be flexibly expanded at will.
The project is committed to providing a multi-source heterogeneous, enhanced database platform and further building an ecosystem around the upper layer of the platform. Database Plus, the design philosophy of Apache ShardingSphere, aims at building the standard and ecosystem on the upper layer of the heterogeneous database. It focuses on how to make full and reasonable use of the computing and storage capabilities of existing databases rather than creating a brand new database. It attaches greater importance to the collaboration between multiple databases instead of the database itself.

ShardingSphere-JDBC is a lightweight Java framework that provides additional services at Java’s JDBC layer.
![]()
![]()

ShardingSphere-Proxy is a transparent database proxy, providing a database server that encapsulates database binary protocol to support heterogeneous languages.
| Feature | Definition |
|---|---|
| Data Sharding | Data sharding is an effective way to deal with massive data storage and computing. ShardingSphere provides distributed database solutions that can scale out computing and storage levels on top of the underlying database. |
| Distributed Transaction | Transactional capability is key to ensuring database integrity and security and is also one of the databases’ core technologies. ShardingSphere provides distributed transaction capability on top of a single database, which can achieve data security across underlying data sources. |
| Read/write Splitting | Read/write splitting can be used to cope with business access with high stress. Based on its understanding of SQL semantics and the topological awareness of the underlying database, ShardingSphere provides flexible and secure read/write splitting capabilities and can achieve load balancing for read access. |
| Data Migration | Data migration is the key to connecting data ecosystems. ShardingSphere provides full-scenario data migration capability for users, which can cope with the surge of business data volume. |
| Federated Query | Federated queries are effective in utilizing data in a complex data environment. ShardingSphere is capable of querying and analyzing complex data across data sources, simplifying and improving the data usage experience. |
| Data Encryption | Data Encryption is a basic way to ensure data security. ShardingSphere provides a set of data encryption solutions that are complete, secure, transparent, and with low transformation costs. |
| Shadow Database | In the full-link stress testing scenario, ShardingSphere shadow DB is used for providing data isolation support for complex testing work. The obtained testing result can accurately reflect the system’s true capacity and performance. |
Having been polished for years, the driver is close to a native JDBC in terms of efficiency, with ultimate performance.
The proxy can be accessed by any application using MySQL/PostgreSQL protocol, and the driver can connect to any database that implements JDBC specifications.
In response to database switchover scenarios, ShardingSphere can achieve smooth business migration without business intrusion.
ShardingSphere offers a flat learning curve to DBAs and is interaction-friendly while allowing the original technology stack to remain unchanged.
It can provide enhancement capability based on mature databases while ensuring security and stability.
It supports computing, storage, and smooth online expansion, which can meet diverse business needs.
It can provide users with flexibility thanks to custom systems based on multi-level (kernel, feature, and ecosystem) plugin capabilities.
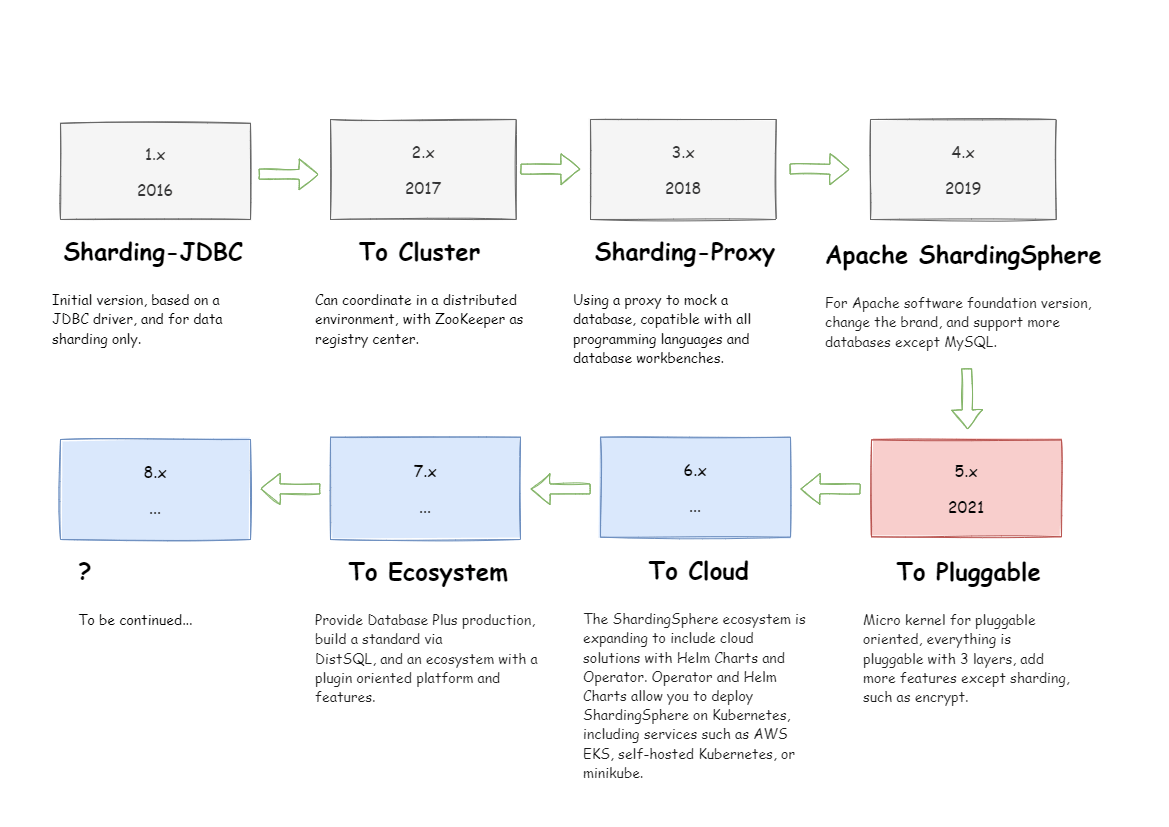
ShardingSphere became an Apache Top-Level Project on April 16, 2020. You are welcome to check out the mailing list and discuss via mail.