Apache ShardingSphere includes two independent clients: ShardingSphere-JDBC & ShardingSphere-Proxy. They all provide functions of data scale-out, distributed transaction and distributed governance, applicable in a variety of scenarios such as Java isomorphism, heterogeneous languages, and a cloud-native environment.
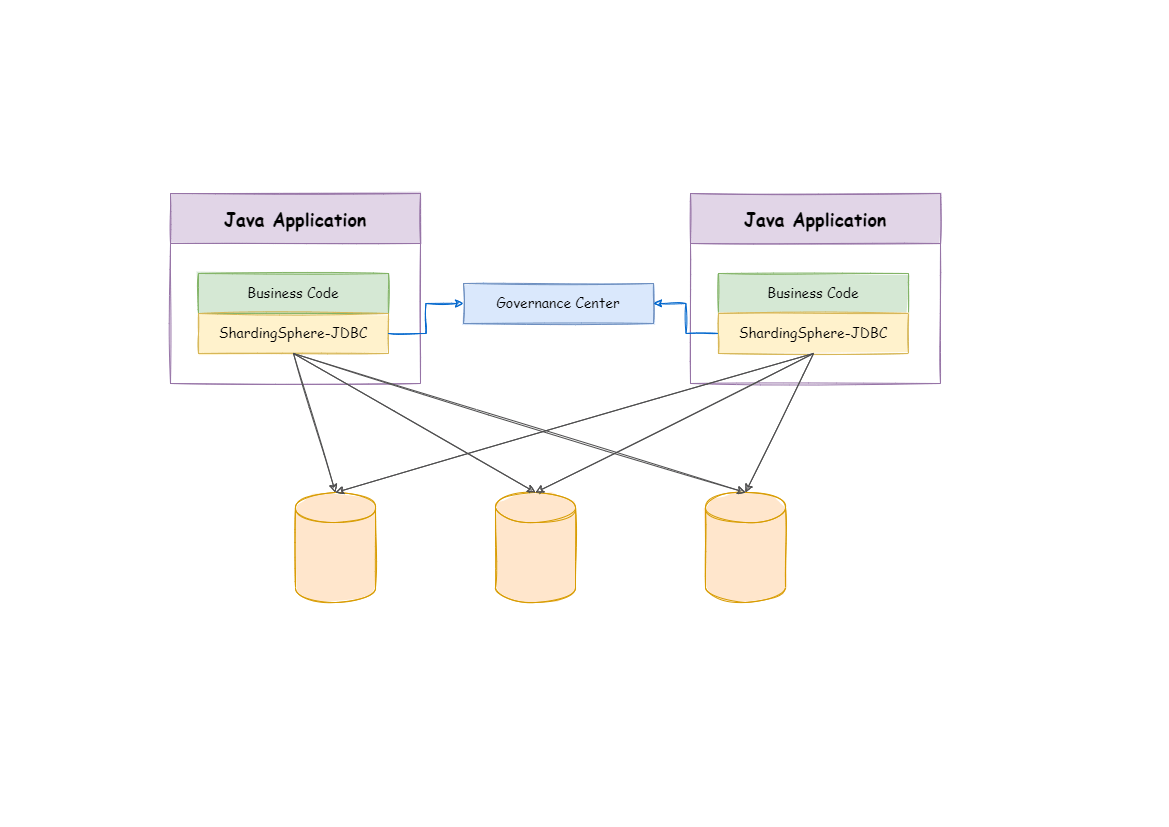
ShardingSphere-JDBC is a lightweight Java framework that provides additional services at Java’s JDBC layer. With the client connecting directly to the database, it provides services in the form of jar and requires no extra deployment and dependence. It can be considered as an enhanced version of the JDBC driver, which is fully compatible with JDBC and all kinds of ORM frameworks.
| ShardingSphere-JDBC | ShardingSphere-Proxy | |
|---|---|---|
| Database | Any |
MySQL/PostgreSQL |
| Connections Count Cost | More |
Less |
| Heterogeneous language | Java Only |
Any |
| Performance | Low loss |
Relatively High loss |
| Decentralization | Yes |
No |
| Static entry | No |
Yes |
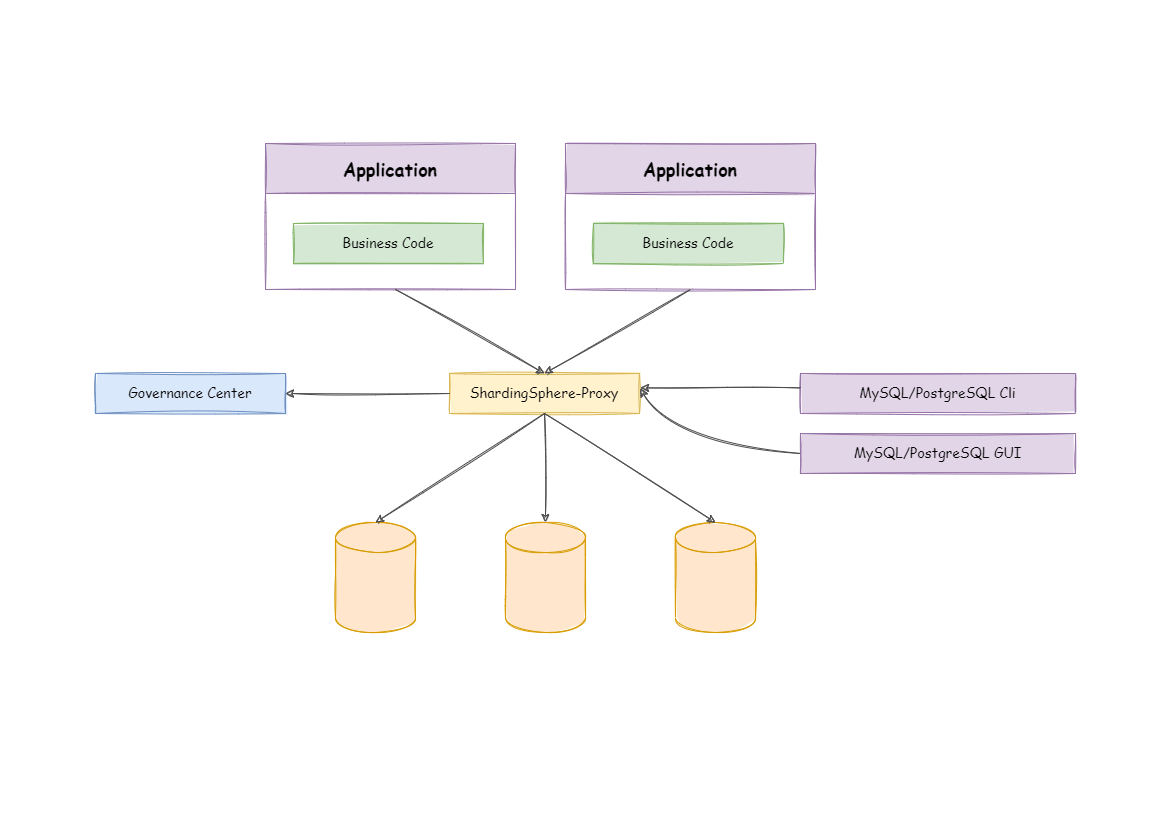
ShardingSphere-Proxy is a transparent database proxy, providing a database server that encapsulates database binary protocol to support heterogeneous languages. Currently, MySQL and PostgreSQL protocols are provided. It can use any kind of terminal that is compatible with MySQL or PostgreSQL protocol to operate data, which is more friendly to DBAs.
| ShardingSphere-JDBC | ShardingSphere-Proxy | |
|---|---|---|
| Database | Any | MySQL/PostgreSQL |
| Connections Count Cost | More | Less |
| Heterogeneous language | Java Only | Any |
| Performance | Low loss | Relatively High loss |
| Decentralization | Yes | No |
| Static entry | No | Yes |
ShardingSphere-JDBC adopts a decentralized architecture, applicable to high-performance light-weight OLTP applications developed with Java. ShardingSphere-Proxy provides static entry and supports all languages, applicable to OLAP applications and the sharding databases management and operation situation.
Apache ShardingSphere is an ecosystem composed of multiple access ports. By combining ShardingSphere-JDBC and ShardingSphere-Proxy, and using the same registry to configure sharding strategies, it can flexibly build application systems for various scenarios, allowing architects to freely adjust the system architecture according to the current businesses.
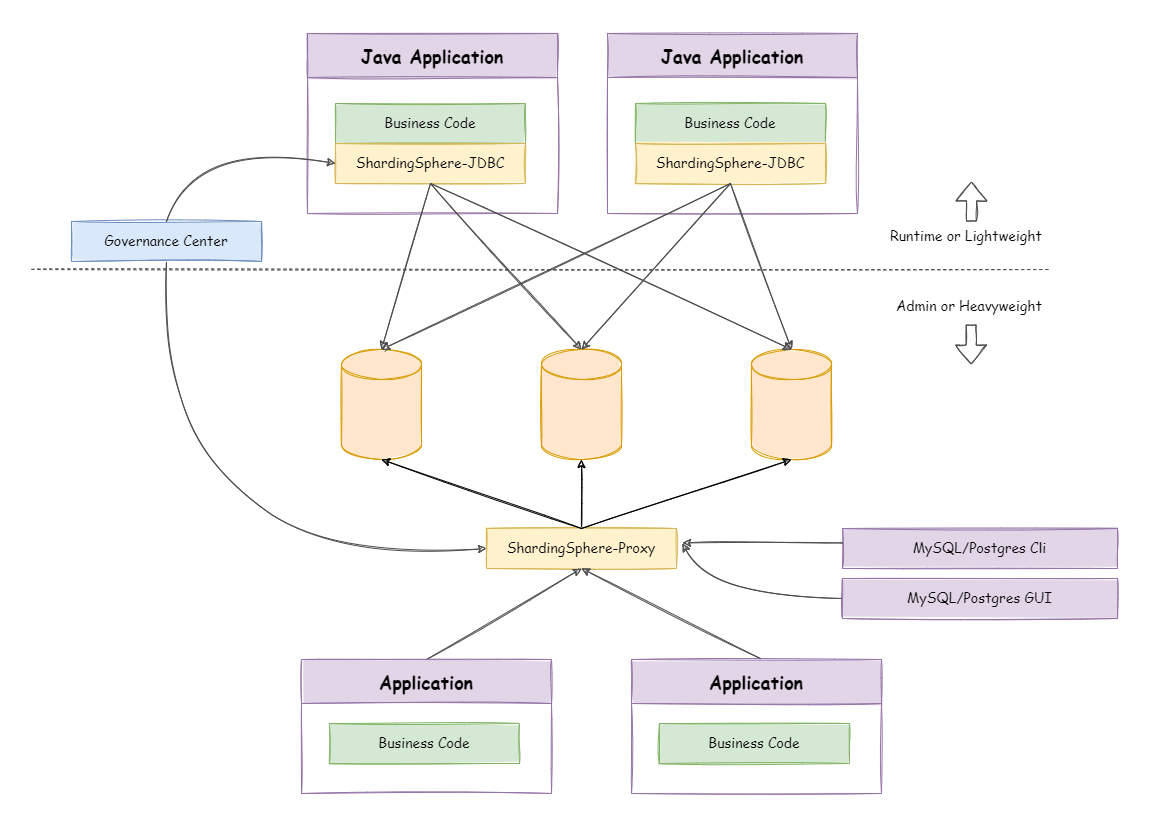
Apache ShardingSphere provides two running modes: standalone mode and cluster mode.
It can achieve data persistence in terms of metadata information such as data sources and rules, but it is not able to synchronize metadata to multiple Apache ShardingSphere instances or be aware of each other in a cluster environment. Updating metadata through one instance causes inconsistencies in other instances because they cannot get the latest metadata.
It is ideal for engineers to build a ShardingSphere environment locally.
It provides metadata sharing between multiple Apache ShardingSphere instances and the capability to coordinate states in distributed scenarios.
It provides the capabilities necessary for distributed systems, such as horizontal scaling of computing capability and high availability. Clustered environments need to store metadata and coordinate nodes’ status through a separately deployed registry center.
We suggest using cluster mode in production environment.