
ElasticJob will not re-shard during this execution, but wait for the next scheduling before starting the re-sharding process. When the server is down during job execution, failover allows the unfinished task to be compensated and executed on another job node.
Failover is a temporary compensation execution mechanism for the currently executed job. When the next job is run, the current job allocation will be adjusted through resharding. For example, if the job is executed at an hourly interval, each execution will take 30 minutes. As shown below.
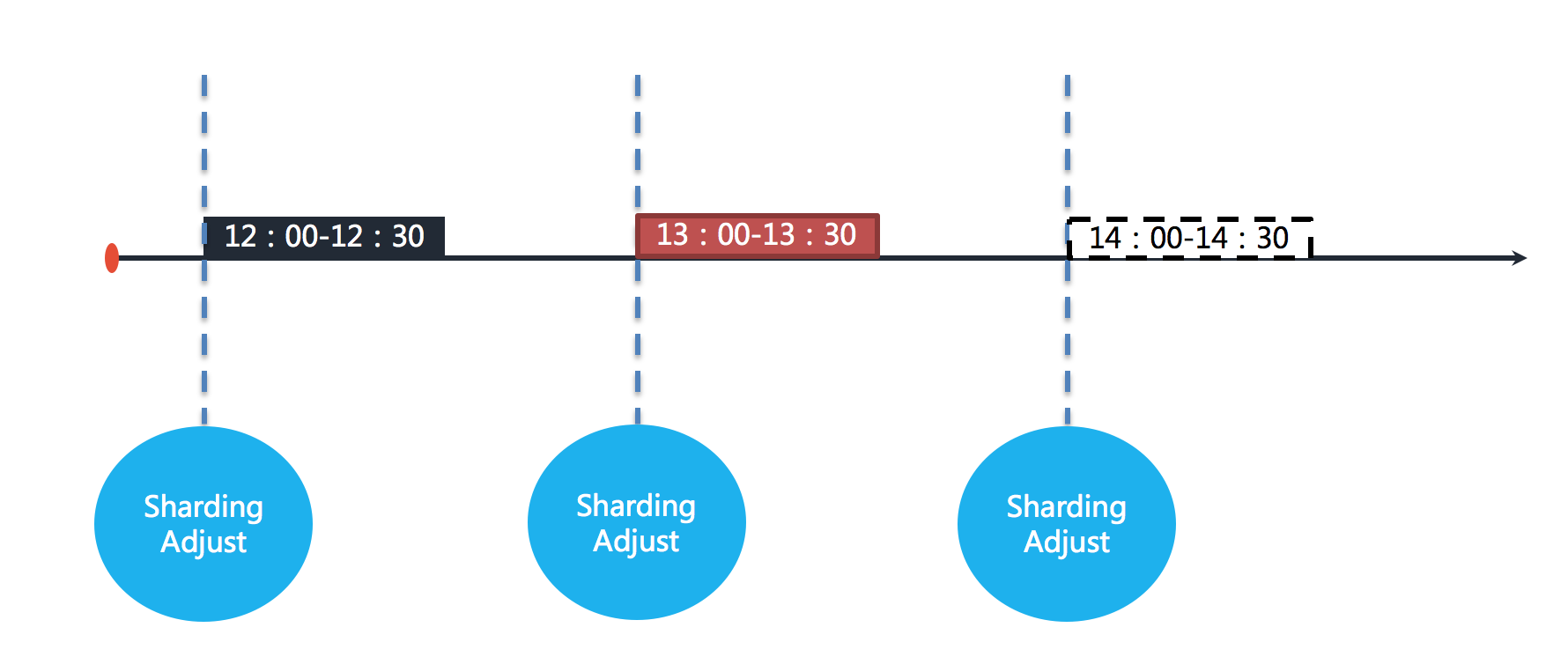
The figure shows that the jobs are executed at 12:00, 13:00 and 14:00 respectively. The current time point shown in the figure is the job execution at 13:00.
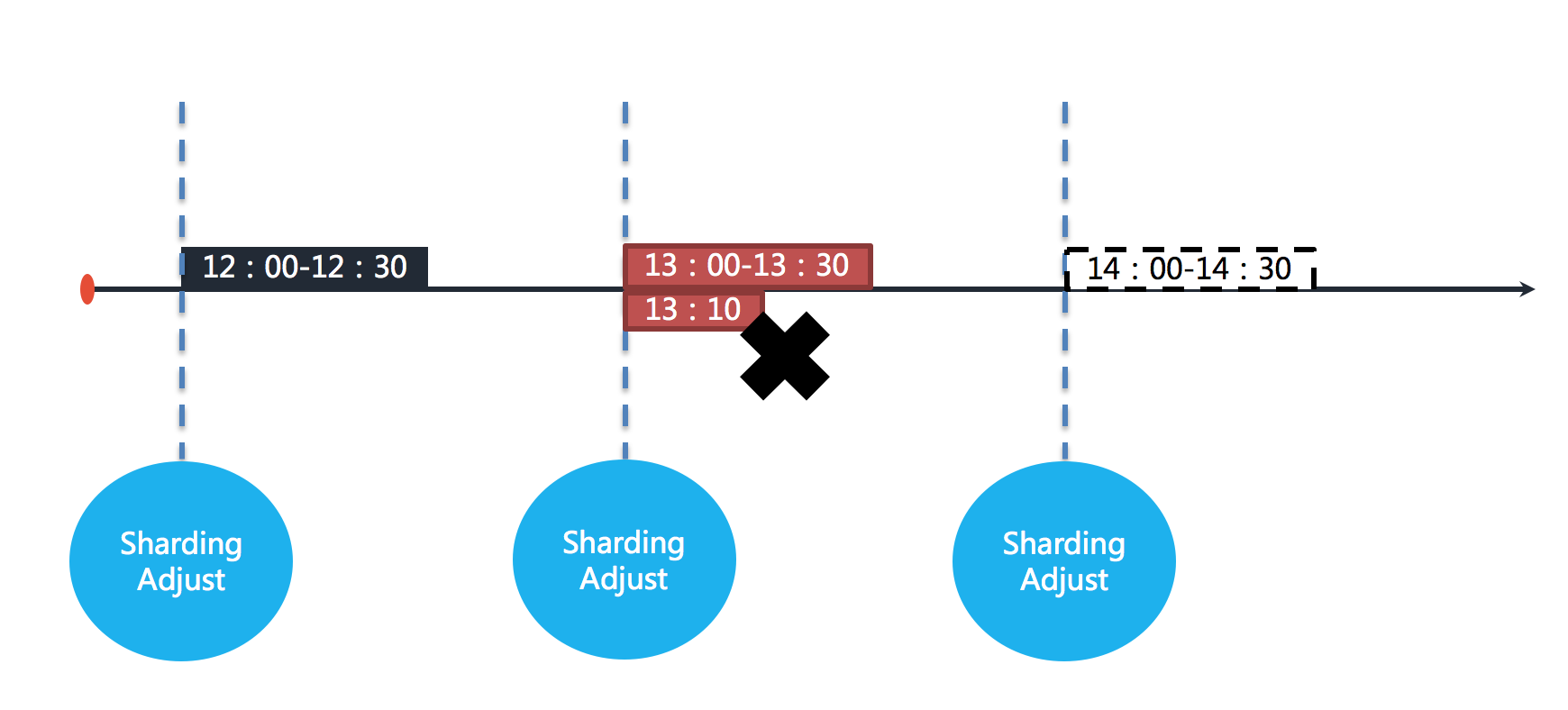
If one of the shard servers of the job goes down at 13:10, the remaining 20 minutes of the business that should be processed are not executed, and the next job can only be executed at 14:00. In other words, if failover is not turned on, there is a 50-minute idle period in this shard. As shown below.
After the failover is enabled, other ElasticJob servers can compensate for the execution of the sharding job after sensing the down job server. As shown below.
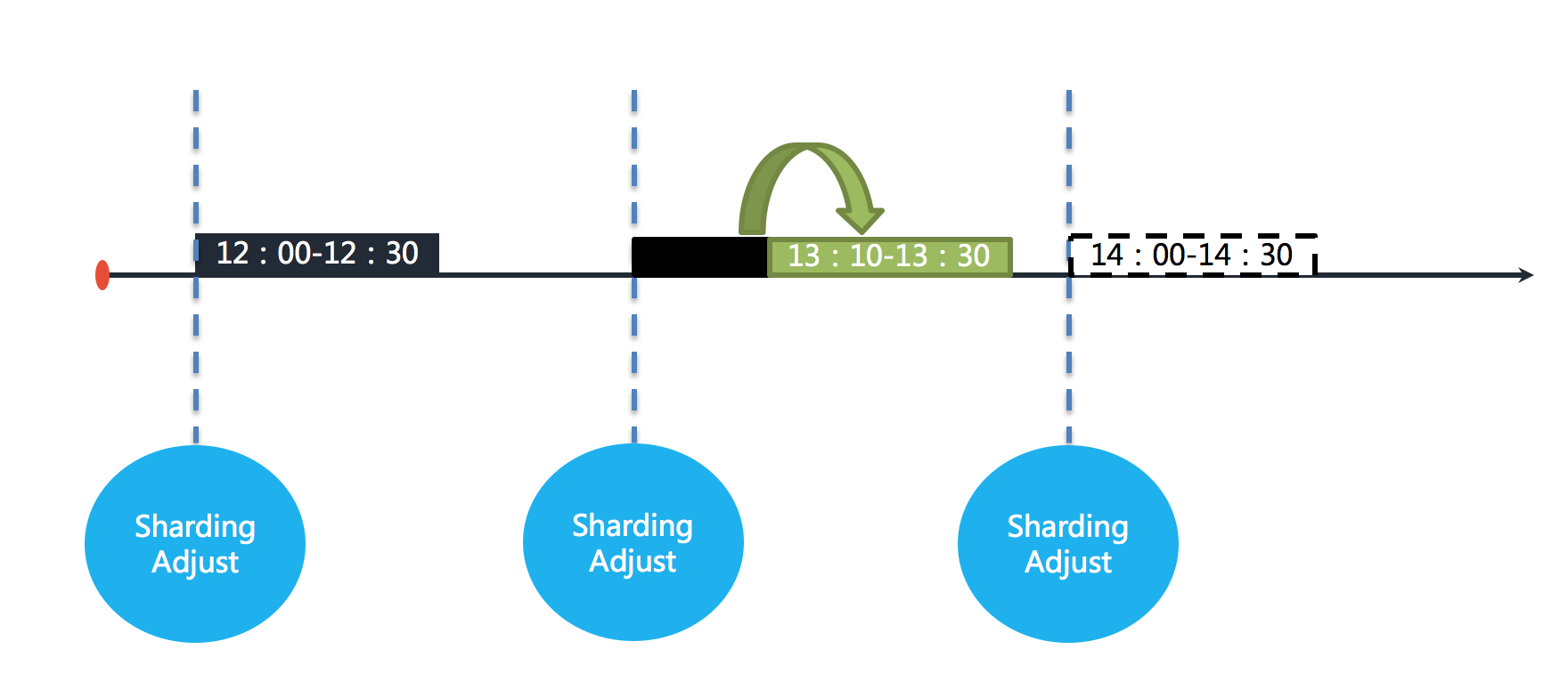
With sufficient resources, the job can still be executed completely at 13:30.
When the job execution node goes down, the failover process will be triggered. ElasticJob determines the execution timing of the failover according to the different conditions of the distributed job execution when it is triggered。
When other servers perceive that a failover job needs to be processed, and the job server has completed this task, it will pull the items to be failed over in real time and start compensation execution. Also called real-time execution.
After the execution of this task, the job service will inquire about the failover items to be executed from the registry, and if there are any, the compensation execution will start. Also called asynchronous execution.
With the failover enabled, ElasticJob will monitor the execution status of each shard of the job and write it to the registry for other nodes to perceive.
In a job scenario that takes a long time to run and has a long interval, failover is an effective means to improve the real-time operation of the job; For short-interval jobs, a large number of network communications with the registry will be generated, which will affect the performance of the cluster; Moreover, short-interval jobs do not necessarily pay attention to the real-time performance of a single job. You can use the re-shard of the next job execution to make all the items execute correctly. Therefore, it is not recommended to enable failover for short-interval jobs.
Another thing to note is that the idempotence of the job itself is a prerequisite to ensure the correctness of failover.