
Elastic schedule is the most important feature in ElasticJob, which acts as a job processing system that enables the horizontal scaling of jobs by sharding, it’s also the origin of the project name “ElasticJob”.
A concept in ElasticJob to split the job, enabling the job to be executed in distributed environment, where every single server only executes one of the slice that is assigned to it. ElasticJob is aware of the number of servers in an almost-real-time manner, with the increment/decrement number of the servers, it re-assigns the job slices to the distributed servers, maximizing the efficiency as the increment of resources.
To execute the job in distributed servers, a job will be divided into multiple individual job items, one or some of which will be executed by the distributed servers.
For example, if a job is divided into 4 slices, and there are two servers to execute the job, then each server is assigned 2 slices, undertaking 50% of the workload, as follows.
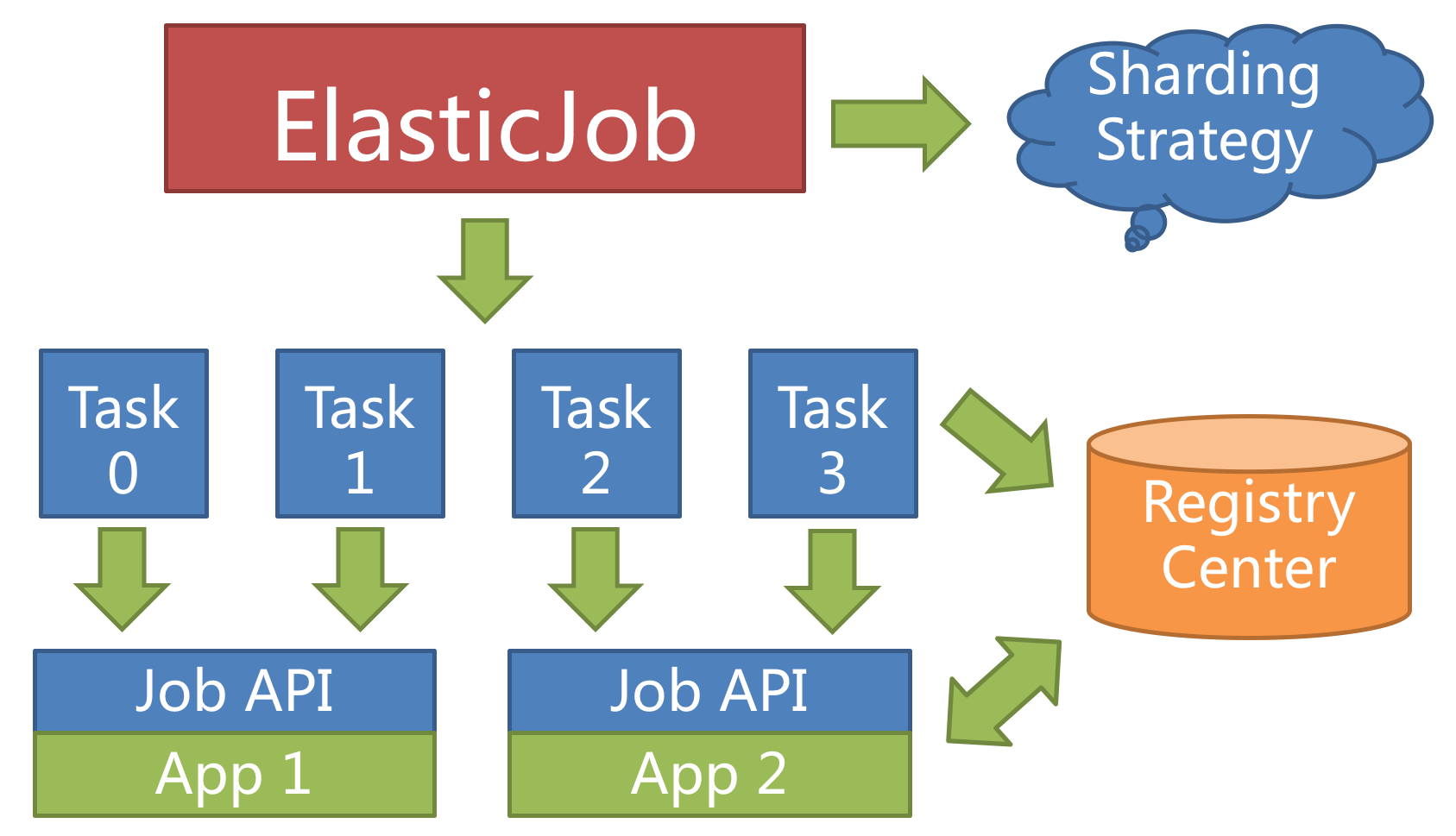
ElasticJob doesn’t directly provide the abilities to process the data, instead, it assigns the sharding items to the job servers, where the developers should process the sharding items and their business logic themselves. The sharding item is numeric type, in the range of [0, size(slices) - 1].
Customized sharding options can build a relationship with the sharding items, converting the sharding items' numbers to more readable business codes.
For example, to horizontally split the databases according to the regions, database A stores data from Beijing, database B stores data from Shanghai and database C stores data from Guangzhou.
If we configure only by the sharding items' numbers, the developers need the knowledge that 0 represents Beijing, 1 represents Shanghai and 2 represents Guangzhou.
Customized sharding options make the codes more readable, if we have customized options 0=Beijing,1=Shanghai,2=Guangzhou, we can simply use Beijing, Shanghai, Guangzhou in the codes.
ElasticJob provides a flexible way to maximize the throughput of the jobs. When new job server joins, ElasticJob will be aware of it from the registry, and will re-shard in the next scheduling process, the new server will undertake some of the job slices, as follows.
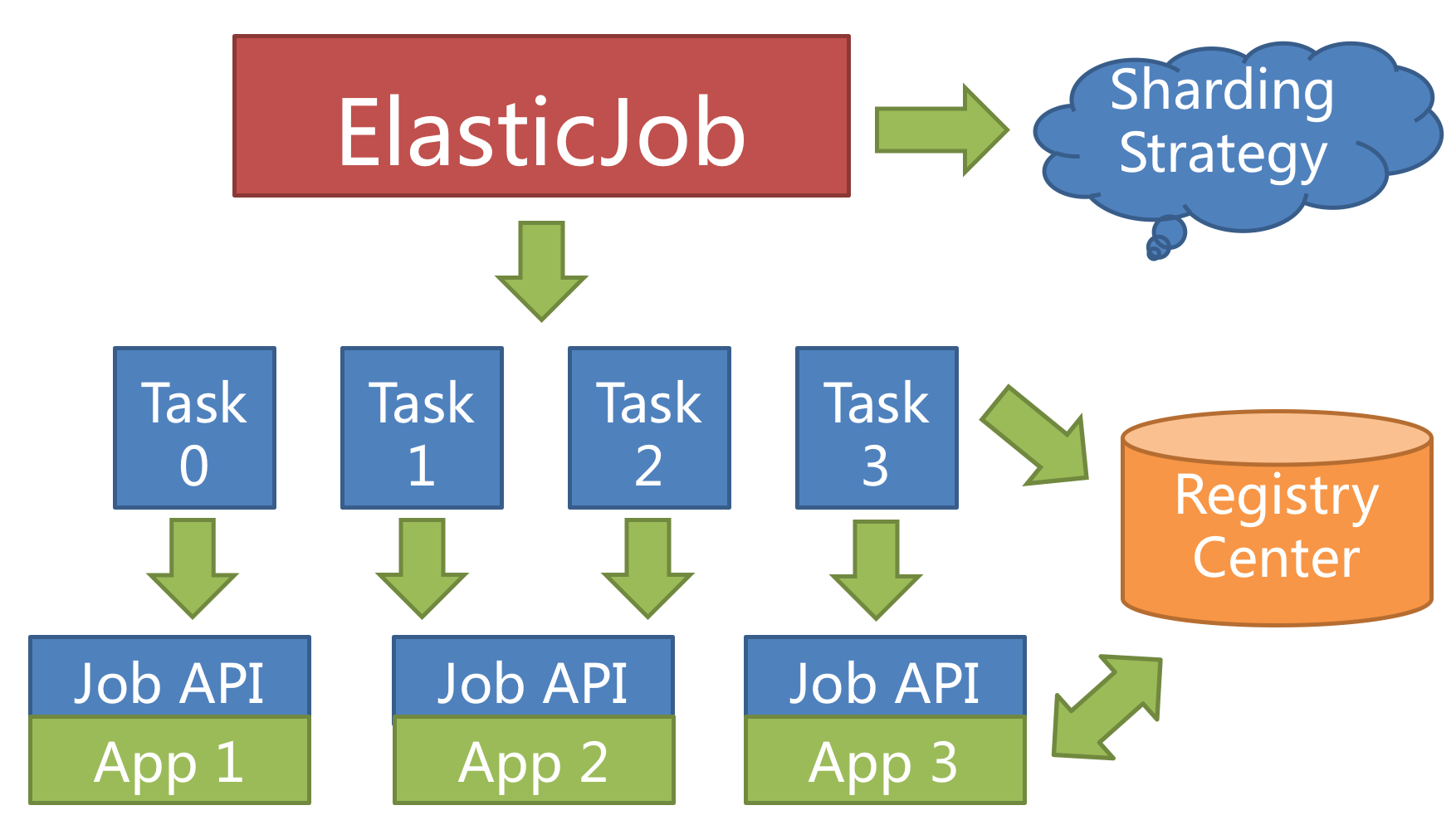
Configuring a larger number of sharding items than the number of servers, or better, a multiplier of the number of servers, makes it more reasonably for the job to leverage the resources, and assign the sharding items dynamically.
For example, we have 10 sharding items and there are 3 servers, the number of sharding items are server A = 0,1,2,9; server B = 3,4,5; server C = 6,7,8. If the server C is down, then server A = 0,1,2,3,4 and B = 5,6,7,8,9, maximizing the throughput without losing any sharding item.
When a server is down when executing a sharding item, the registry is also aware of that, and the sharding item will be transferred to another living server, thus achieve the goal of high availability. The unfinished job from a crashed server will be transferred and executed continuously, as follows.
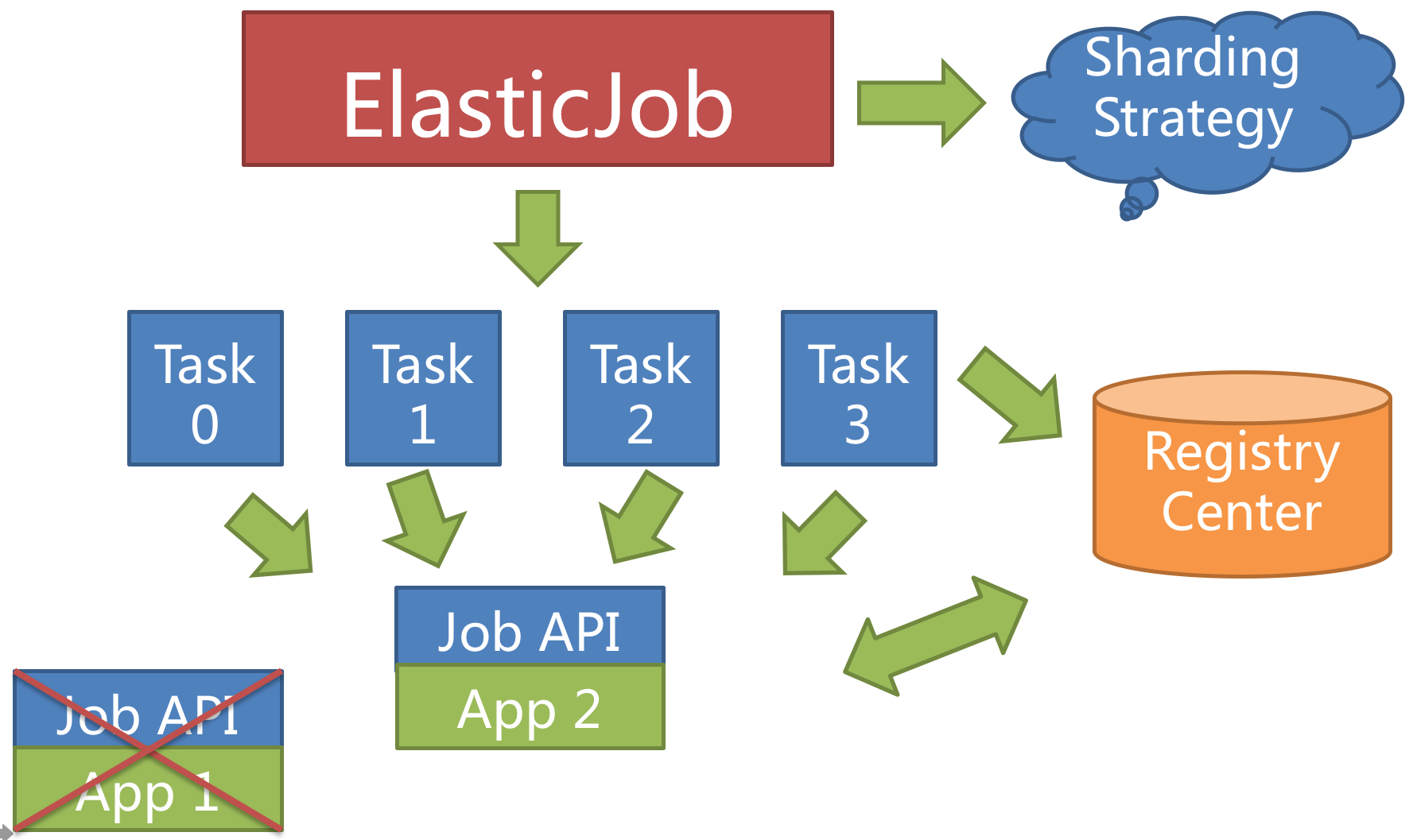
Setting the total number of sharding items to 1 and more than 1 servers to execute the jobs makes the job run in the mode of 1 master and n slaves.
Once the servers that are executing jobs are down, the idle servers will take over the jobs and execute them in the next scheduling, or better, if the failover option is enabled, the idle servers can take over the failed jobs immediately.
ElasticJob does not have a job scheduling center node, but the programs based on the deployment job framework trigger the scheduling when the corresponding time point is reached. The registration center is only used for job registration and monitoring information storage. The main job node is only used to handle functions such as sharding and cleaning.
The registration center creates a job name node under the defined namespace to distinguish different jobs, so once a job is created, the job name cannot be modified. If the name is modified, it will be regarded as a new job. There are 5 data sub-nodes under the job name node, namely config, instances, sharding, servers and leader.
Job configuration information, stored in YAML format.
Job running instance information, the child node is the primary key of the current job running instance. The primary key of the job running instance is composed of the IP address and PID of the job running server. The primary keys of the job running instance are all ephemeral nodes, which are registered when the job instance is online and automatically cleaned up when the job instance is offline. The registry monitors the changes of these nodes to coordinate the sharding and high availability of distributed jobs. You can write TRIGGER in the job running instance node to indicate that the instance will be executed once immediately.
Job sharding information. The child node is the sharding item sequence number, starting from zero and ending with the total number of shards minus one. The child node of the sharding item sequence number stores detailed information. The child node under each shard is used to control and record the running status of the shard. Node details description:
| Child node name | Ephemeral node | Description |
|---|---|---|
| instance | NO | The primary key of the job running instance that executes the shard |
| running | YES | The running state of the shard item. Only valid when monitorExecution is configured |
| failover | YES | If the shard item is assigned to another job server by failover, this node value records the job server IP that executes the shard |
| misfire | NO | Whether to restart the missed task |
| disabled | NO | Whether to disable this shard |
Job server information, the child node is the IP address of the job server. You can write DISABLED in the IP address node to indicate that the server is disabled. Under the new cloud-native architecture, the servers node is greatly weakened, only including controlling whether the server can be disabled. In order to achieve the core of the job more purely, the server function may be deleted in the future, and the ability to control whether the server is disabled should be delegated to the automated deployment system.
The master node information of the job server is divided into three sub-nodes: election, sharding and failover. They are used for master node election, sharding and failover processing respectively.
The leader node is an internally used node. If you are not interested in the principle of the job framework, you don’t need to pay attention to this node.
| Child node name | Ephemeral node | Description |
|---|---|---|
| election\instance | YES | The IP address of the master node server. Once the node is deleted, a re-election will be triggered. All operations related to the master node will be blocked during the re-election process. |
| election\latch | NO | Distributed locks elected by the master node Used for distributed locks of curator |
| sharding\necessary | NO | The flag for re-sharding. If the total number of shards changes, or the job server node goes online or offline or enabled/disabled, as well as the master node election, the re-sharded flag will be triggered. The master node is re-sharded without being interrupted in the middle The sharding will not be triggered when the job is executed |
| sharding\processing | YES | The node held by the master node during sharding. If there is this node, all job execution will be blocked until the sharding ends. The ephemeral node will be deleted when the master node sharding is over or the master node crashes |
| failover\items\shard item | NO | Once a job crashes, it will record to this node. When there is an idle job server, it will grab the job items that need to failover from this node |
| failover\items\latch | NO | Distributed locks used when allocating failover shard items. Used by curator distributed locks |