Refactoring the DistSQL Syntax | ShardingSphere 5.3.0 Deep Dive

Background
DistSQL (Distributed SQL) is ShardingSphere’s SQL-like functional language. Since we released version 5.0.0-Beta, we’ve been iterating rapidly and providing users with features including rule management, cluster management, and metadata management. It was an incremental improvement process including many steps.
At the same time, DistSQL is still releatively young. The ShardingSphere community often receives fresh ideas and suggestions about DistSQL, which means fast growth with lots of possible different development directions.
Before releasing version 5.3.0, our community refactored DistSQL systematically and optimized its syntax. This blog post will illustrate those adjustments one by one.
Related Concepts
We have sorted out objects managed by DistSQL and classified them into the following categories according to their characteristics and scope of functions, to facilitate the understanding and design of DistSQL syntax.
Node
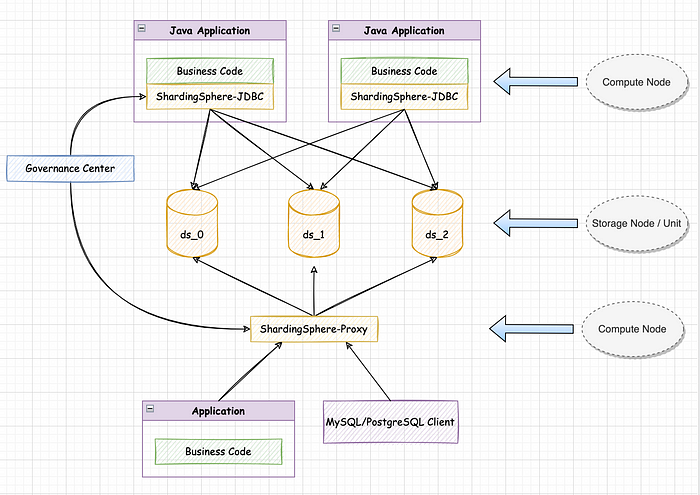
The following is a typical hybrid architecture of ShardingSphere, among which:
Compute Node
ShardingSphere-JDBC and ShardingSphere-Proxy instances both provide computing capabilities and they are called compute nodes.
Storage Node
Physical databases ds_0, ds_1, and ds_2 provide data storage capabilities and are called storage nodes. According to the different forms of storage nodes, the instance-level node is called a Storage Node (such as a MySQL instance), and the database-level node is called a Storage Unit (such as a MySQL database). A storage node can provide multiple storage units.
Instance Object
Instance objects can be applied to entire compute node instances, and their capabilities affect operations in all logical databases.
Global Rules
Global rules include rule configurations that take effect globally in ShardingSphere, such as Authority, Transaction, SQL Parser, and SQL Translator. They control the authentication and authorization, distributed transaction, SQL parser, SQL translator and other functional engines, and are the basic configuration of compute node runtime.
Note: all global rules in ShardingSphere have default values. If users have no special needs, just keep the default values.
Distributed Variables
Distributed variables are a group of system-level variables in ShardingSphere, whose configuration also affects the entire compute node. They’re called Dist Variables, so users can better distinguish them from the variables of the storage node and avoid confusion.
Additionally, if there are changes to distributed variable values, they are synchronized to the entire compute node cluster, for a truly distributed configuration.
Dist variables include SQL_SHOW, MAX_CONNECTIONS_SIZE_PER_QUERY, SQL_FEDERATION_TYPE and other commonly used compute node attributes, completely covering the props configuration in YAML.
Job
Job refers to the asynchronous job capability provided by Proxy compute nodes. For example, a migration job provides data migration for users. In the future, it may also provide more asynchronous job functions.
Database Object
Database objects are used to manage metadata in logical databases and provide operations on metadata such as REFRESH DATABASE METADATA and EXPORT DATABASE CONFIGURATION.
Table Object
A table object is an object whose scope is a specific logical table. It can be simply understood as table rule configurations.
Table objects contain common rules such as Broadcast (broadcast table), Encrypt (data encryption), Sharding (data sharding), and Single (single table), which are often named the same as the logical table name.
Relation Object
Relation objects are not used to manage a specific database or table. They are used to describe the relationship between a set of objects.
Currently, relation objects include two types: the DB_Discovery Rule which describes the relationship between storage nodes, and the Sharding Table Reference Rule which describes the relationship between sharding tables.
Traffic Object
Traffic objects are used to manage data traffic in ShardingSphere, including traffic rules such as Readwrite-splitting Rule and Shadow Rule.
Summary
Put the above concepts together and we’ll get an architecture diagram about DistSQL-managed objects, as shown below:
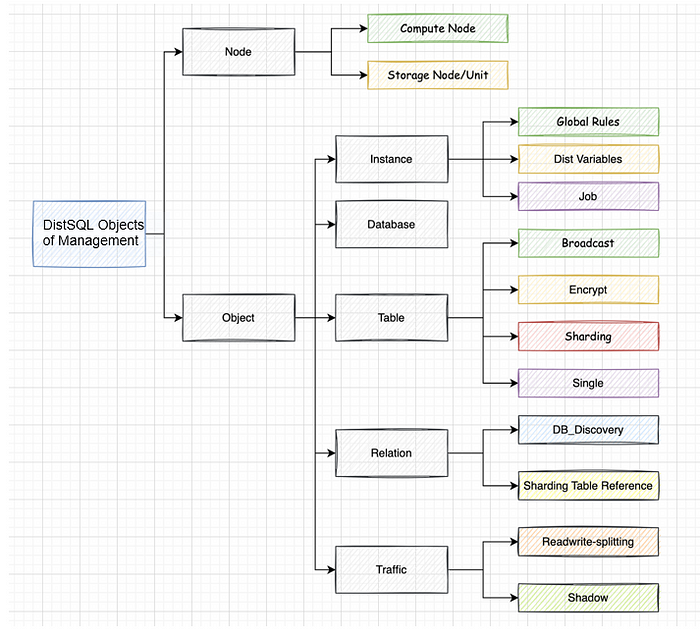
This diagram helps us better categorize DistSQL and design its syntax systematically.
Syntax Refactoring
The new release 5.3.0 has upgraded DistSQL. We have completely sorted out and refactored DistSQL statements in line with the long-term planning of the ShardingSphere community, to make each one more targeted and more compatible. This section shows the specific changes by comparing the content before and after the adjustments.
Node
Compute Node
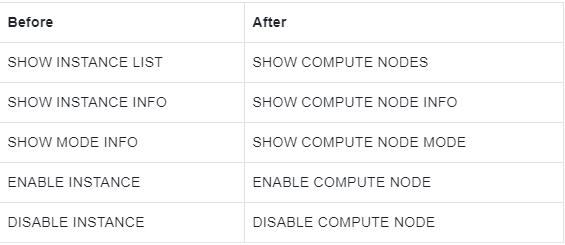
Description: keyword INSTANCE is updated to COMPUTE NODE.
Storage Node
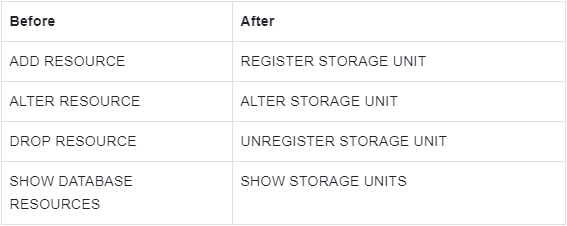
Description:
Keyword RESOURCE is updated to STORAGE NODE / STORAGE UNIT, which corresponds to instance-level storage and database-level storage respectively.
The STORAGE NODE is reserved and is not used currently.
Instance Object
Global Rules
Global rule syntax is not adjusted this time.
Dist Variables

Description: DIST is added before VARIABLE to represent a distributed variable.
MIGRATION Job
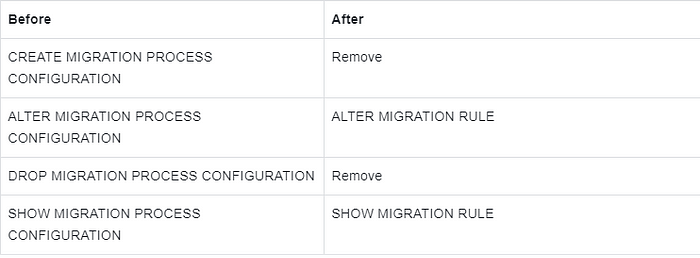
Description:
PROCESS CONFIGURATION keyword is changed to RULE.
Remove CREATE and DROP operations because MIGRATION RULE has default values.
Other syntax is not adjusted.
Database Object
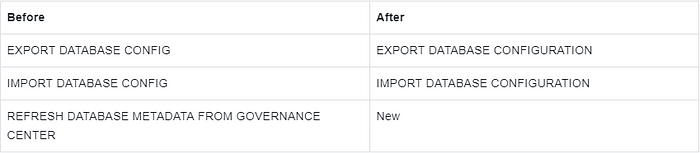
Description:
CONFIG is changed to CONFIGURATION, which is more accurate.
The REFRESH DATABASE METADATA statement is added to pull the configuration from the governance center to forcibly refresh the local metadata.
Table Object
Broadcast Table
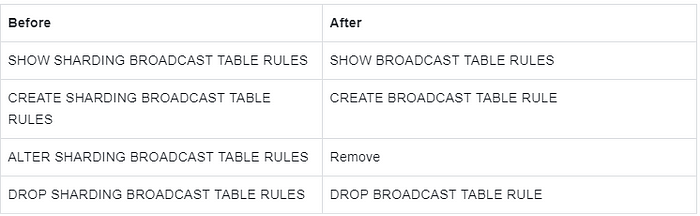
Description: SHARDING keyword is removed from the broadcast table.
Data Encryption
The syntax related to data encryption is not adjusted this time. Please refer to the official document [1].
Sharding table
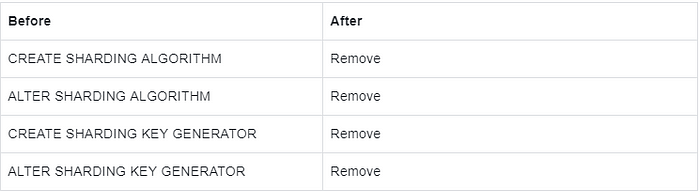
Description:
Remove the syntax for independently creating sharding algorithms and distributed ID generators and integrate them into the rule definition of CREATE SHARDING TABLE RULE.
Other syntax is not adjusted.
Single Table
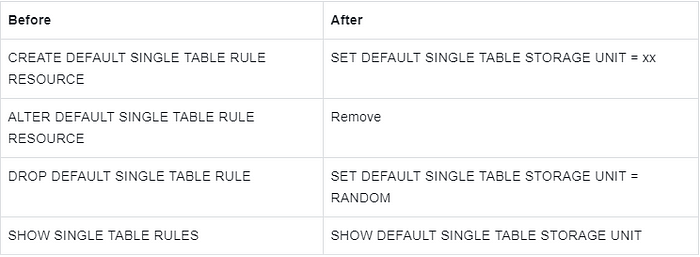
Description: by default, only one single-table router can be created. And CREATE is updated to SET.
Relation Object
Database Discovery
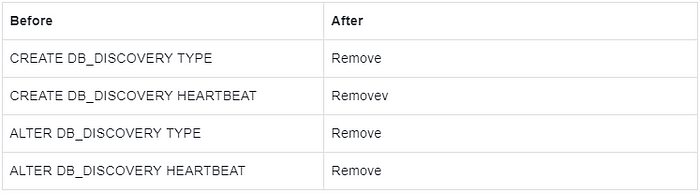
Description:
Remove the syntax for creating a DB_DISCOVERY TYPE and HEARTBEAT independently and integrate them into the rule definition of the CREATE DB_DISCOVERY RULE.
Other syntax is not adjusted.
Binding Table
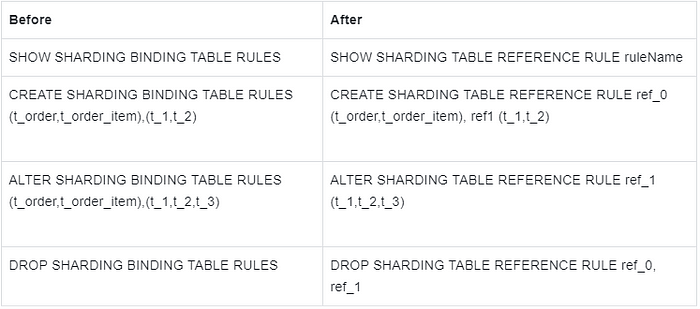
Description: adjust the keyword and add ruleName for easier management.
Traffic Object
Read/write Splitting
Description: there is no major change to read/write splitting syntax. Only RESOURCE is replaced with STORAGE_UNIT based on the keyword change of the storage node. For example:
CREATE READWRITE_SPLITTING RULE ms_group_0 (
WRITE_STORAGE_UNIT=write_ds,
READ_STORAGE_UNITS(read_ds_0,read_ds_1),
TYPE(NAME="random")
);
Shadow Database
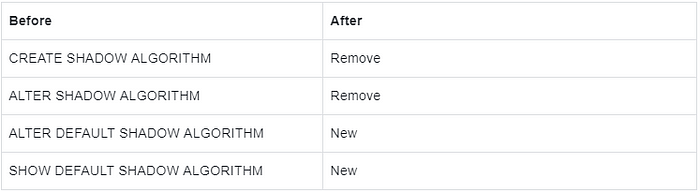
Description:
Remove syntax for creating shadow algorithms independently and integrate it into the rule definition of CREATE SHADOW RULE.
Add statements to ALTER and SHOW default shadow algorithm, corresponding to CREATE DEFAULT SHADOW ALGORITHM.
Property Specification Optimization
In addition to the syntax refactoring, this update further simplifies the operations of DistSQL for users, including:
- When referring to the built-in strategy type or algorithm type, omit quotation marks.
- The value type in
PROPERTIESis adjusted fromstringtoliteral, which supports strings, integers, and booleans.
Example
For example, when users create sharding rules, the algorithm must meet the following rules:
TYPE(NAME="MOD",PROPERTIES("sharding-count"="4"))
"MOD"is the name of the algorithm type and belongs to a string, so it needs to be quoted;- Although the value of
PROPERTIESis"4", it is also a string and needs to be quoted.
After this optimization, you can omit quotes when referencing a built-in algorithm type and the value of PROPERTIES can also omit quotes if it is not a string.
Therefore, the following is also rightful and equivalent:
TYPE(NAME="MOD",PROPERTIES("sharding-count"=4))
Demo
In addition to the above changes, there are other minor tweaks.
When using CREATE SHARDING TABLE RULE statement to create an automatic sharding rule, we have to reference storage resources via RESOURCES(ds_0, ds_1) mode. From now on, it is changed to STORAGE_UNITS(ds_0, ds_1).
Next, below is a demo of how to use the new DistSQL with a sharding scenario as an example.
- Create a logical database
CREATE DATABASE sharding_db;
USE sharding_db;
- Register storage resources
REGISTER STORAGE UNIT ds_0 (
HOST="127.0.0.1",
PORT=3306,
DB="ds_0",
USER="root",
PASSWORD="root"
),ds_1 (
HOST="127.0.0.1",
PORT=3306,
DB="ds_1",
USER="root",
PASSWORD="root"
);
- Create sharding rules
CREATE SHARDING TABLE RULE t_order(
STORAGE_UNITS(ds_0,ds_1),
SHARDING_COLUMN=order_id,
TYPE(NAME=MOD,PROPERTIES("sharding-count"=4)),
KEY_GENERATE_STRATEGY(COLUMN=order_id,TYPE(NAME=SNOWFLAKE))
);
- Create a sharding table
CREATE TABLE t_order (
`order_id` int NOT NULL,
`user_id` int NOT NULL,
`status` varchar(45) DEFAULT NULL,
PRIMARY KEY (`order_id`)
);
- Data read and write
INSERT INTO t_order (order_id, user_id, status) VALUES
(1,1,'OK'),
(2,2,'OK'),
(3,3,'OK');
SELECT * FROM t_order;
- Delete the table
DROP TABLE IF EXISTS t_order;
- Delete sharding rules
DROP SHARDING TABLE RULE t_order;
- Remove the storage node
UNREGISTER STORAGE UNIT ds_0, ds_1;
- Delete the logical database
DROP DATABASE sharding_db;
Conclusion
That’s all about the refactoring of DistSQL. Please refer to the official document [1] for more information about the DistSQL syntax.
If you have any questions or suggestions about Apache ShardingSphere, you are welcome to submit a GitHub issue [2] for discussion.
Reference
[1] DistSQL Syntax
[2] GitHub Issue