解析引擎
相对于其他编程语言,SQL 是比较简单的。 不过,它依然是一门完善的编程语言,因此对 SQL 的语法进行解析,与解析其他编程语言(如:Java 语言、C 语言、Go 语言等)并无本质区别。
抽象语法树
解析过程分为词法解析和语法解析。 词法解析器用于将 SQL 拆解为不可再分的原子符号,称为 Token。并根据不同数据库方言所提供的字典,将其归类为关键字,表达式,字面量和操作符。 再使用语法解析器将词法解析器的输出转换为抽象语法树。
例如,以下 SQL:
SELECT id, name FROM t_user WHERE status = 'ACTIVE' AND age > 18
解析之后的为抽象语法树见下图。
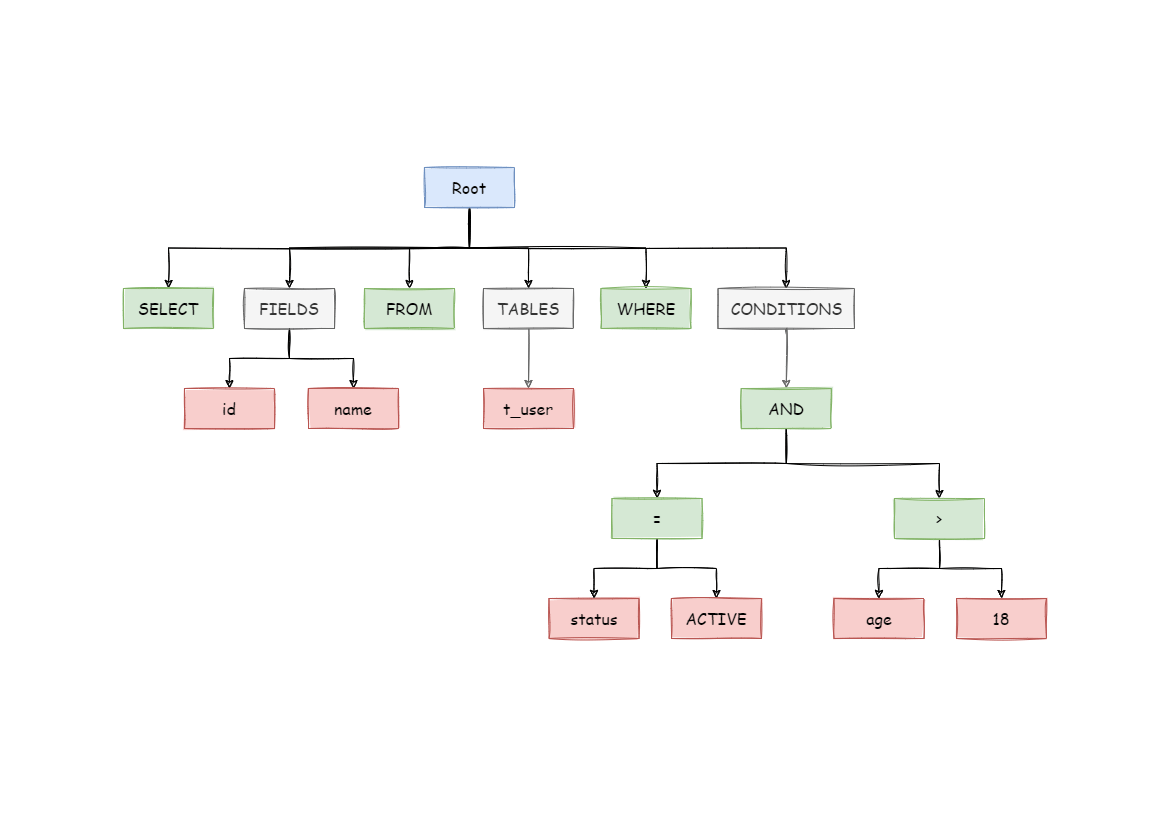
为了便于理解,抽象语法树中的关键字的 Token 用绿色表示,变量的 Token 用红色表示,灰色表示需要进一步拆分。
最后,通过 visitor 对抽象语法树遍历构造域模型,通过域模型(SQLStatement)去提炼分片所需的上下文,并标记有可能需要改写的位置。
供分片使用的解析上下文包含查询选择项(Select Items)、表信息(Table)、分片条件(Sharding Condition)、自增主键信息(Auto increment Primary Key)、排序信息(Order By)、分组信息(Group By)以及分页信息(Limit、Rownum、Top)。
SQL 的一次解析过程是不可逆的,一个个 Token 按 SQL 原本的顺序依次进行解析,性能很高。
考虑到各种数据库 SQL 方言的异同,在解析模块提供了各类数据库的 SQL 方言字典。
SQL 解析引擎
历史
SQL 解析作为分库分表类产品的核心,其性能和兼容性是最重要的衡量指标。 ShardingSphere 的 SQL 解析器经历了 3 代产品的更新迭代。
第一代 SQL 解析器为了追求性能与快速实现,在 1.4.x 之前的版本使用 Druid 作为 SQL 解析器。经实际测试,它的性能远超其它解析器。
第二代 SQL 解析器从 1.5.x 版本开始,ShardingSphere 采用完全自研的 SQL 解析引擎。
由于目的不同,ShardingSphere 并不需要将 SQL 转为一颗完全的抽象语法树,也无需通过访问器模式进行二次遍历。它采用对 SQL 半理解的方式,仅提炼数据分片需要关注的上下文,因此 SQL 解析的性能和兼容性得到了进一步的提高。
第三代 SQL 解析器从 3.0.x 版本开始,尝试使用 ANTLR 作为 SQL 解析引擎的生成器,并采用 Visit 的方式从 AST 中获取 SQL Statement。从 5.0.x 版本开始,解析引擎的架构已完成重构调整,
同时通过将第一次解析得到的 AST 放入缓存,方便下次直接获取相同 SQL的解析结果,来提高解析效率。 因此我们建议用户采用 PreparedStatement 这种 SQL 预编译的方式来提升性能。
功能点
- 提供独立的 SQL 解析功能
- 可以非常方便的对语法规则进行扩充和修改(使用了
ANTLR) - 支持多种方言的 SQL 解析
| 数据库 | 支持状态 |
|---|---|
| MySQL | 支持,完善 |
| PostgreSQL | 支持,完善 |
| SQLServer | 支持 |
| Oracle | 支持 |
| SQL92 | 支持 |
| openGauss | 支持 |
- 提供 SQL 格式化功能(开发中)
- 提供 SQL 模板化功能(开发中)
API使用
引入Maven依赖
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>shardingsphere-sql-parser-engine</artifactId>
<version>${project.version}</version>
</dependency>
<!-- 根据需要引入指定方言的解析模块(以 MySQL 为例),可以添加所有支持的方言,也可以只添加使用到的 -->
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>shardingsphere-sql-parser-mysql</artifactId>
<version>${project.version}</version>
</dependency>
例子
- 获取语法树
/**
* databaseType type:String 可能值 MySQL, Oracle,PostgreSQL,SQL92,SQLServer, openGauss
* sql type:String 解析的 SQL
* useCache type:boolean 是否使用缓存
* @return parse context
*/
ParseContext parseContext = new SQLParserEngine(databaseType).parse(sql, useCache);
- 获取SQLStatement
/**
* databaseType type:String 可能指 MySQL,Oracle,PostgreSQL,SQL92,SQLServer, openGauss
* useCache type:boolean 是否使用缓存
* @return SQLStatement
*/
ParseContext parseContext = new SQLParserEngine(databaseType).parse(sql, useCache);
SQLVisitorEngine sqlVisitorEngine = new SQLVisitorEngine(databaseType, "STATEMENT");
SQLStatement sqlStatement = sqlVisitorEngine.visit(parseContext);
- SQL格式化
/**
* databaseType type:String 可能指 MySQL
* useCache type:boolean 是否使用缓存
* @return String
*/
ParseContext parseContext = new SQLParserEngine(databaseType).parse(sql, useCache);
SQLVisitorEngine sqlVisitorEngine = new SQLVisitorEngine(databaseType, "FORMAT", new Properties());
String formatedSql = sqlVisitorEngine.visit(parseContext);
例子:
| sql | formatedSql |
|---|---|
| select a+1 as b, name n from table1 join table2 where id=1 and name='lu’; | SELECT a + 1 AS b, name n FROM table1 JOIN table2 WHERE id = 1 and name = ‘lu’; |
| select id, name, age, sex, ss, yy from table1 where id=1; | SELECT id , name , age , sex , ss , yy FROM table1 WHERE id = 1; |
| select id, name, age, count(*) as n, (select id, name, age, sex from table2 where id=2) as sid, yyyy from table1 where id=1; | SELECT id , name , age , COUNT(*) AS n, ( SELECT id , name , age , sex FROM table2 WHERE id = 2 ) AS sid, yyyy FROM table1 WHERE id = 1; |
| select id, name, age, sex, ss, yy from table1 where id=1 and name=1 and a=1 and b=2 and c=4 and d=3; | SELECT id , name , age , sex , ss , yy FROM table1 WHERE id = 1 and name = 1 and a = 1 and b = 2 and c = 4 and d = 3; |
| ALTER TABLE t_order ADD column4 DATE, ADD column5 DATETIME, engine ss max_rows 10,min_rows 2, ADD column6 TIMESTAMP, ADD column7 TIME; |
ALTER TABLE t_order ADD column4 DATE, ADD column5 DATETIME, ENGINE ss MAX_ROWS 10, MIN_ROWS 2, ADD column6 TIMESTAMP, ADD column7 TIME |
CREATE TABLE IF NOT EXISTS runoob_tbl(runoob_id INT UNSIGNED AUTO_INCREMENT,runoob_title VARCHAR(100) NOT NULL,runoob_author VARCHAR(40) NOT NULL,runoob_test NATIONAL CHAR(40),submission_date DATE,PRIMARY KEY (runoob_id))ENGINE=InnoDB DEFAULT CHARSET=utf8; |
CREATE TABLE IF NOT EXISTS runoob_tbl (runoob_id INT UNSIGNED AUTO_INCREMENT,runoob_title VARCHAR(100) NOT NULL,runoob_author VARCHAR(40) NOT NULL,runoob_test NATIONAL CHAR(40),submission_date DATE,PRIMARY KEY ( runoob_id)) ENGINE = InnoDB DEFAULT CHARSET = utf8; |
| INSERT INTO t_order_item(order_id, user_id, status, creation_date) values (1, 1, ‘insert’, ‘2017-08-08’), (2, 2, ‘insert’, ‘2017-08-08’) ON DUPLICATE KEY UPDATE status = ‘init’; |
INSERT INTO t_order_item (order_id , user_id , status , creation_date) VALUES (1, 1, ‘insert’, ‘2017-08-08’), (2, 2, ‘insert’, ‘2017-08-08’) ON DUPLICATE KEY UPDATE status = ‘init’; |
| INSERT INTO t_order SET order_id = 1, user_id = 1, status = convert(to_base64(aes_encrypt(1, ‘key’)) USING utf8) ON DUPLICATE KEY UPDATE status = VALUES(status); |
INSERT INTO t_order SET order_id = 1, user_id = 1, status = CONVERT(to_base64(aes_encrypt(1 , ‘key’)) USING utf8) ON DUPLICATE KEY UPDATE status = VALUES(status); |
| INSERT INTO t_order (order_id, user_id, status) SELECT order_id, user_id, status FROM t_order WHERE order_id = 1; | INSERT INTO t_order (order_id , user_id , status) SELECT order_id , user_id , status FROM t_order WHERE order_id = 1; |