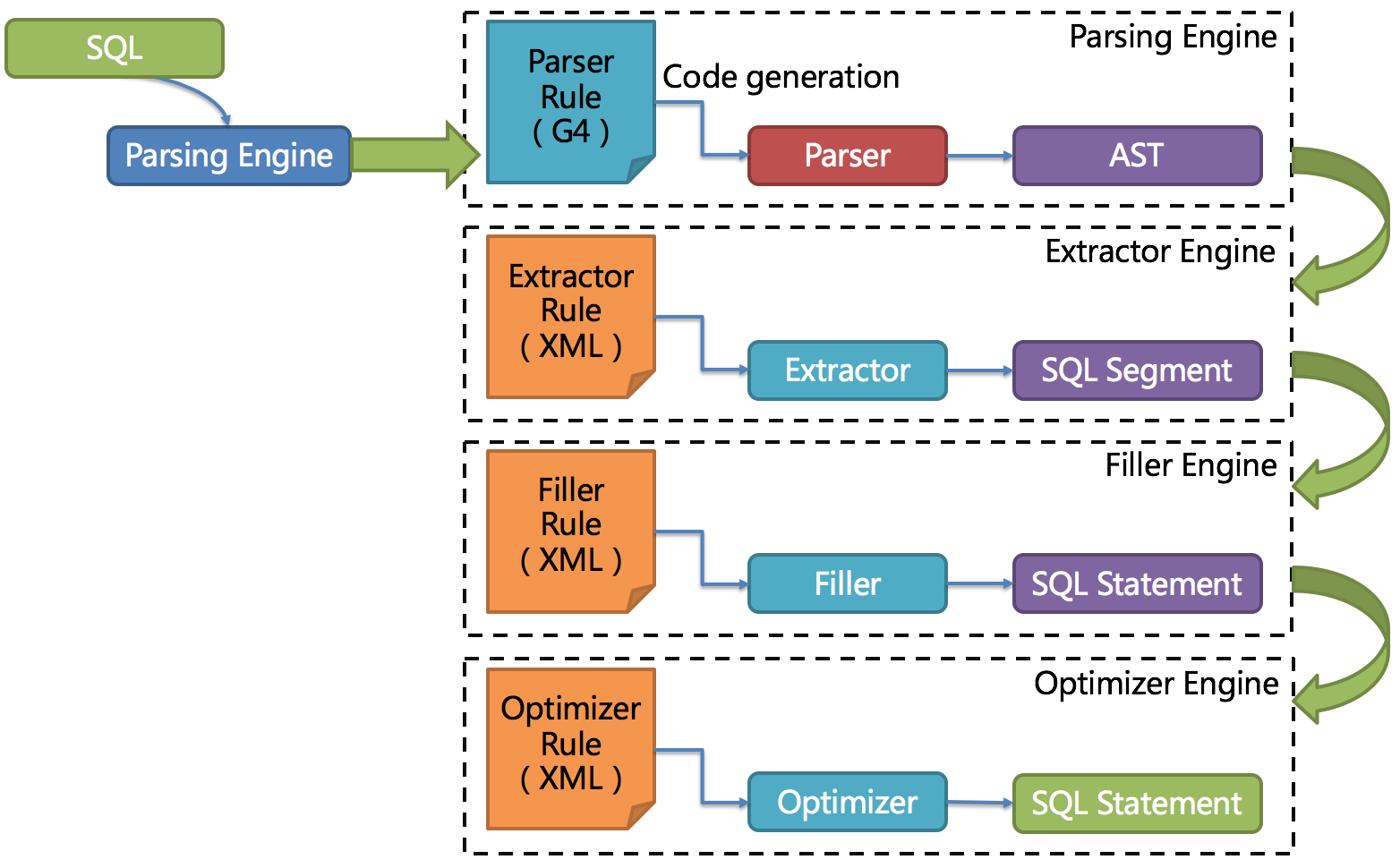
Parse Engine
Compared to other programming languages, SQL is relatively simple, but it is still a complete set of programming language, so there is no essential difference between parsing SQL grammar and parsing other languages (Java, C and Go, etc.).
Abstract Syntax Tree
The parsing process can be divided into lexical parsing and syntactic parsing. Lexical parser is used to divide SQL into indivisible atomic signs, i.e., Token. According to the dictionary provided by different database dialect, it is categorized into keyword, expression, literal value and operator. SQL is then converted into abstract syntax tree by syntactic parser.
For example, the following SQL:
SELECT id, name FROM t_user WHERE status = 'ACTIVE' AND age > 18
Its parsing AST (Abstract Syntax Tree) is this:
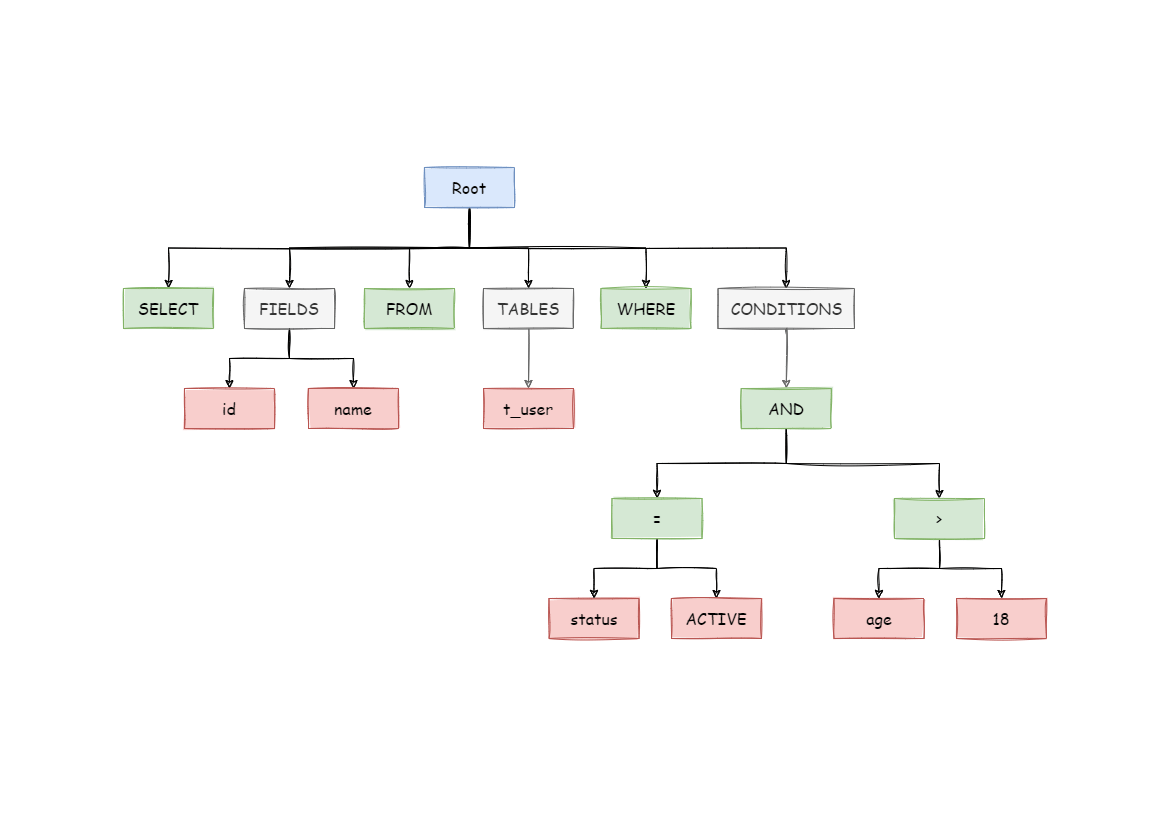
To better understand, the Token of keywords in abstract syntax tree is shown in green; that of variables is shown in red; what’s to be further divided is shown in grey.
At last, through traversing the abstract syntax tree, the context needed by sharding is extracted and the place that may need to be rewritten is also marked out. Parsing context for the use of sharding includes select items, table information, sharding conditions, auto-increment primary key information, Order By information, Group By information, and pagination information (Limit, Rownum and Top). One-time SQL parsing process is irreversible, each Token is parsed according to the original order of SQL in a high performance. Considering similarities and differences between SQL of all kinds of database dialect, SQL dialect dictionaries of different types of databases are provided in the parsing module.
SQL Parser
As the core of database sharding and table sharding, SQL parser takes the performance and compatibility as its most important index. ShardingSphere SQL parser has undergone the upgrade and iteration of 3 generations of products.
To pursue good performance and quick achievement, the first generation of SQL parser uses Druid before 1.4.x version. As tested in practice, its performance exceeds other parsers a lot.
The second generation of SQL parsing engine begins from 1.5.x version, ShardingSphere has adopted fully self-developed parsing engine ever since. Due to different purposes, ShardingSphere does not need to transform SQL into a totally abstract syntax tree or traverse twice through visitor. Using half parsing method, it only extracts the context required by data sharding, so the performance and compatibility of SQL parsing is further improved.
The third generation of SQL parsing engine begins from 3.0.x version. ShardingSphere tries to adopts ANTLR as the SQL parsing engine, and plans to replace the former parsing engine according to the order of DDL -> TCL -> DAL –> DCL -> DML –>DQL. It is still in the process of replacement and iteration. Hoping for a better compatibility with SQL, we use ANTLR in the parsing engine of ShardingSphere. Though complex expressions, recursions, sub-queries and other sentences are not focused by the sharding core of ShardingSphere, they can influence the friendliness to understand SQL. After being tested in actual cases, the performance of ANTLR is about 3-10 times slower than the self-developed parsing engine when parsing SQL. To compensate for this gap, ShardingSphere will put the SQL parsing tree of PreparedStatement in the cache. Therefore, PreparedStatement is recommended to be used as the pre-compile method to improve the performance.
The overall structure of the third generation of SQL parser is shown in the following picture.