How to Run SQL Trace with ShardingSphere-Agent

Apache ShardingSphere, a data service platform that follows the Database Plus concept for distributed database systems, offers a range of features, including data sharding, read/write splitting, data encryption, and shadow database. In production environment, especially in data-sharding scenarios, SQL tracing is critical for monitoring and analyzing slow queries and abnormal executions. Therefore, a thorough understanding of SQL rewriting and query execution is crucial.
What is ShardingSphere-Agent
ShardingSphere-Agent provides an observable framework for ShardingSphere. It is implemented based on Java Agent technology, using Byte Buddy to modify the target bytecode and weave them into data collection logic. Metrics, tracing and logging functions are integrated into the agent through plugins to obtain observable data of system status. Among them, the tracing plugin is used to obtain the tracing information of SQL parsing and SQL execution, which can help users analyze SQL trace when using Apache ShardingSphere-JDBC or Apache ShardingSphere-Proxy.
This post will take ShardingSphere-Proxy as an example to explain how to use ShardingSphere-Agent for SQL tracing.
Two Basic Concepts You Need to Know
Before starting with the article, here are two important concepts that need to be paid attention to first:
-
Span: the basic unit in a trace. A span is created for each call in the trace and ideentified by a unique ID. Spans can contain some customized information such as descriptive information, timestamps, key-value pairs, etc.
-
Trace: the collection of spans with a tree structure. In ShardingSphere-Proxy, a trace represents to the full execution process of a SQL statement.
When running a SQL statement in ShardingSphere-Proxy, it goes through parsing, routing, rewriting, execution, and merging. Currently, tracing has been implemented in two critical steps: parsing and execution — with execution oftentimes being the focus. In the execution stage, Proxy will connect to the physical database to execute the actual SQL. Therefore, the information obtained during this stage provides important evidence for troubleshooting issues and fully reflects the correspondence between logical SQL and actual SQL after rewriting.
In ShardingSphere-Proxy, a trace consists of three types of spans:
| Span | Description |
/ShardingSphere/rootInvoke/
|
This span indicates the complete execution of an SQL statement, and you can view the amount of time spent on executing an SQL |
/ShardingSphere/parseSQL/
|
This span indicates the parsing stage of the SQL execution. You can view the parsing time of an SQL and the SQL statements. (It is not available when a PreparedStatement is used.)
|
/ShardingSphere/executeSQL/
|
This span indicates the rewritten SQL is executed. And the time spent on executing is also available. (This span is not available if the SQL doesn’t need to be executed in the backend physical database). |
How to use ShardingSphere-Agent for SQL tracing
For the convenience of viewing the tracing data, Zipkin or Jaeger is usually used to collect and display the tracing data. Currently, ShardingSphere-Agent supports reporting trace data to both components. Next, let’s use the sharding scenario as an example to explain how to report data and analyze the SQL trace.
Configuring ShardingSphere-Proxy
- Download Proxy from the official website [1]
- Create
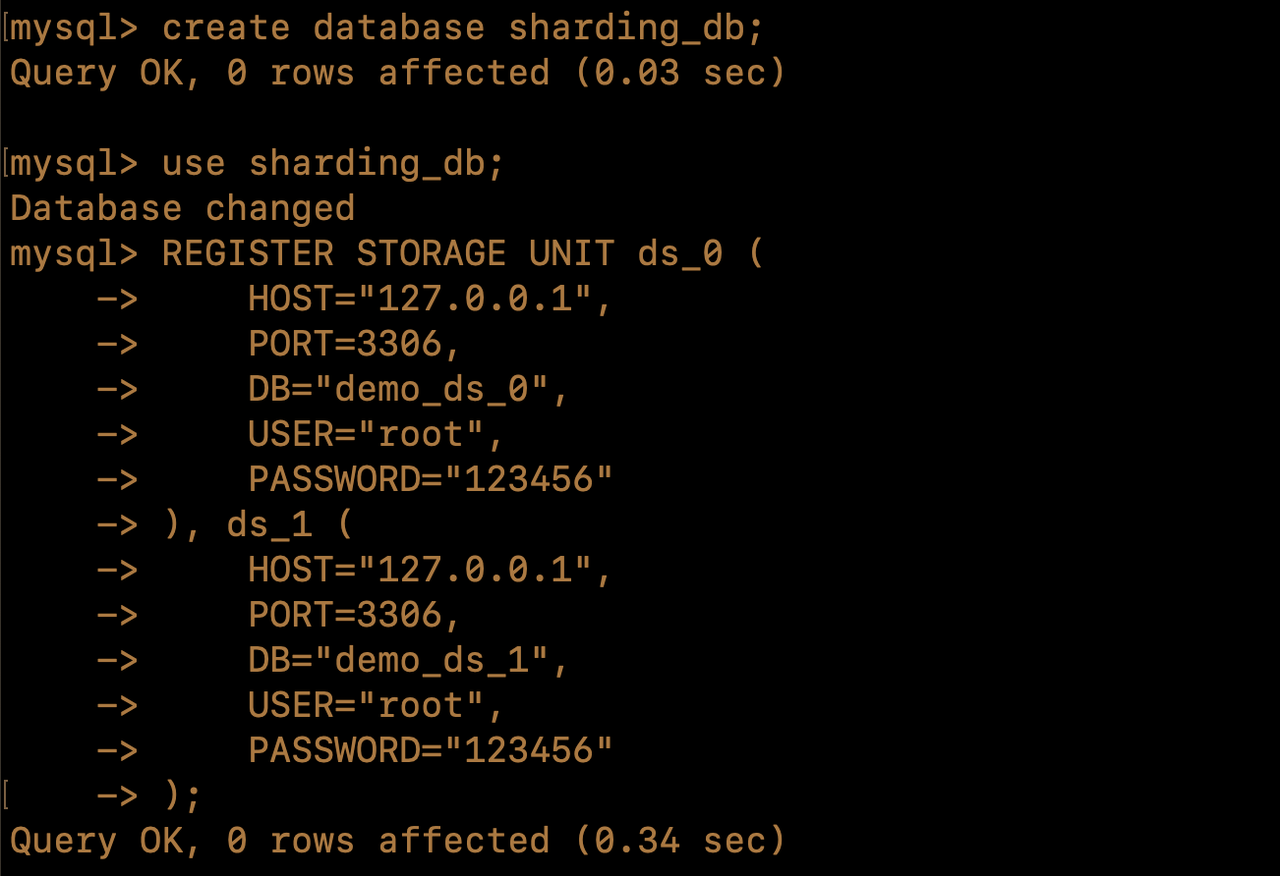
demo_ds_0anddemo_ds_1under the MySQL database as the storage unitds_0andds_1. - Start Proxy, and connect to Proxy using a MySQL client tool; create logical database
sharding_db, and register the storage units under this database using DistSQL (Distributed SQL). DistSQL is the specific SQL language for Apache ShardingSphere. It is used in exactly the same way as standard SQL, and is used to provide SQL-level operational capabilities for incremental functions. For details, please refer to the DistSQL official document [2]
- Use DistSQL to create sharding
rule t_order, setds_0andds_1as storage units, and set the number of shard to 4.

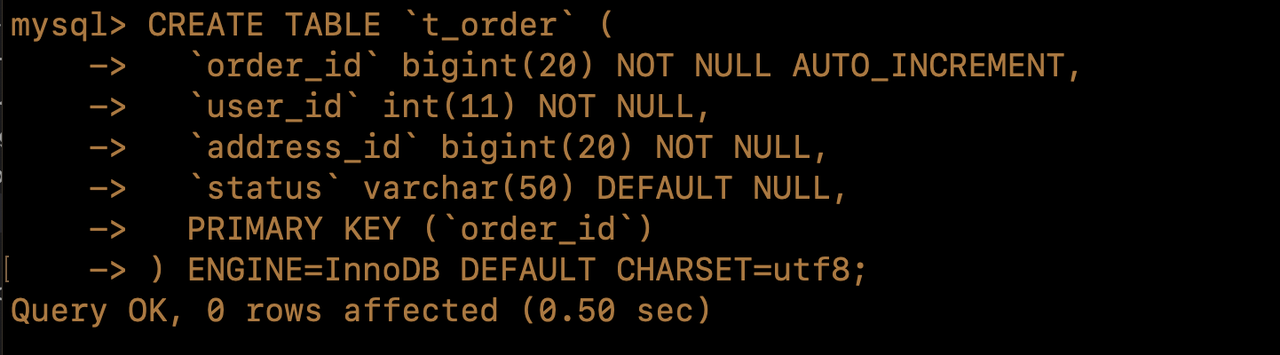
- Create table
t_order
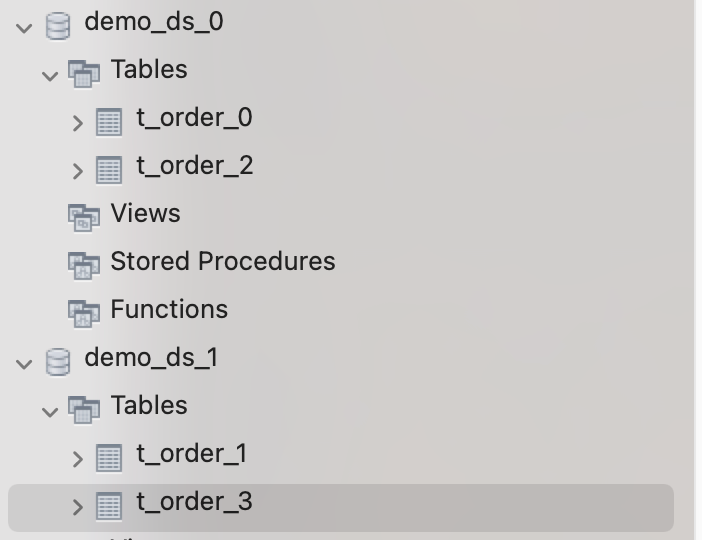
Finally, there will be tables t_order_0 and t_order_2 created in the physical database demo_ds_0, and t_order_1 and t_order_3 tables in the physical database demo_ds_1.
After ShardingSphere-Proxy is well configured, the next step is to introduce how to report SQL trace data to Zipkin and Jaeger through ShardingSphere-Agent.
Reporting to Zipkin
- Deploy Zipkin (please refer to the official website [3])
- Configure
agent.yamlto export data to Zipkin
plugins:
tracing:
OpenTelemetry:
props:
otel.service.name: "shardingsphere" # the service name configured
otel.traces.exporter: "zipkin" # Use zipkin exporter
otel.exporter.zipkin.endpoint: "http://localhost:9411/api/v2/spans" # the address where zipkin receives data
otel-traces-sampler: "always_on" # sampling setting
otel.metrics.exporter: "none" # close OpenTelemetry metric collection
- Restart Proxy and Agent after stopping Proxy (
--agentmeans enabling Agent)
./bin/stop.sh
./bin/start.sh --agent
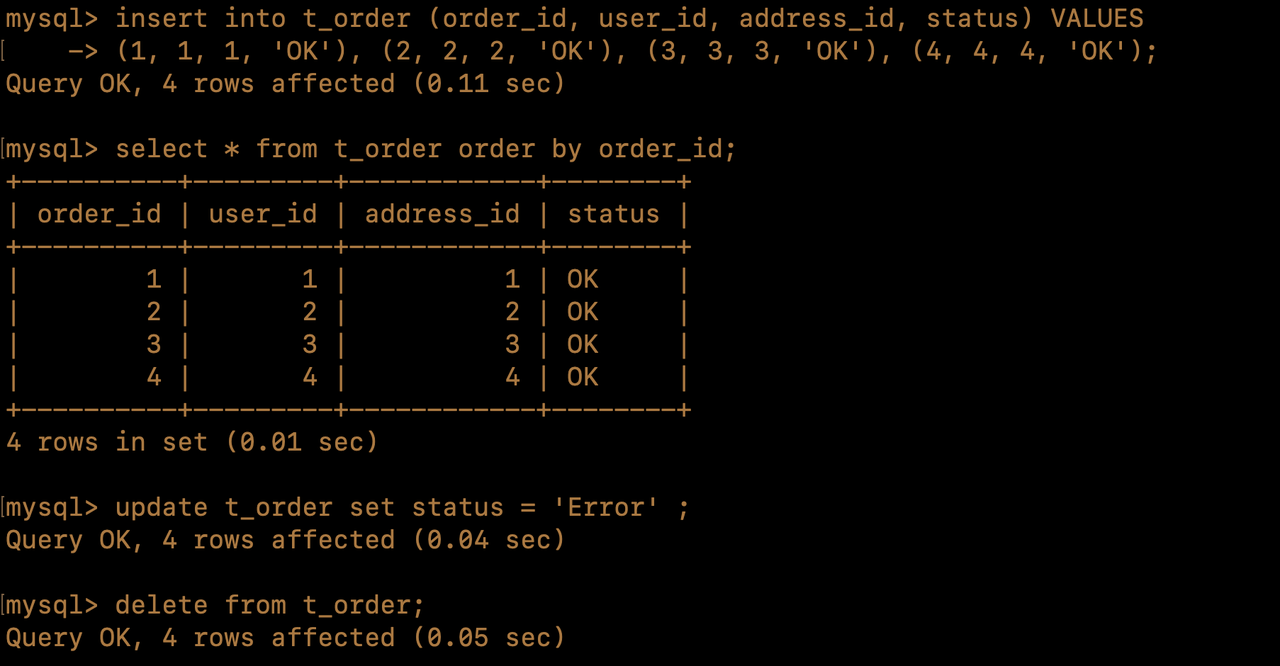
- Use a MySQL client tool to connect to the Proxy and execute the following queries —
insert,select,update, anddeletein sequence.
- Visit http://127.0.0.1:9411/zipkin/ (Zipkin UI), and you can see 4 pieces of trace data, which is exactly the same number of SQL queries.
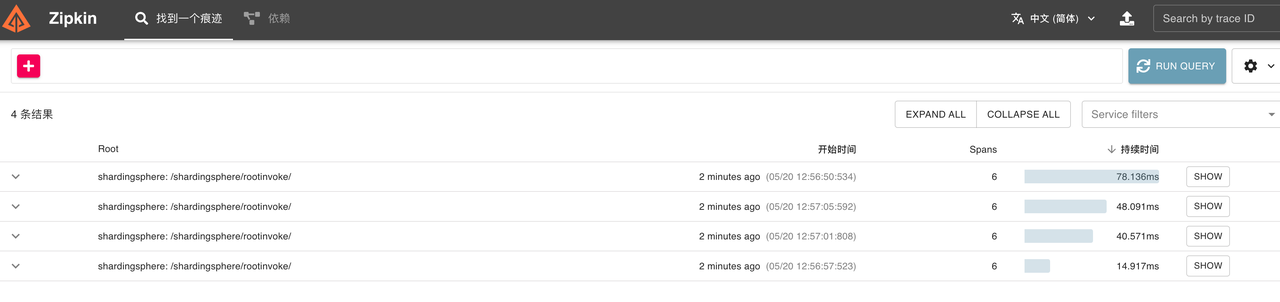
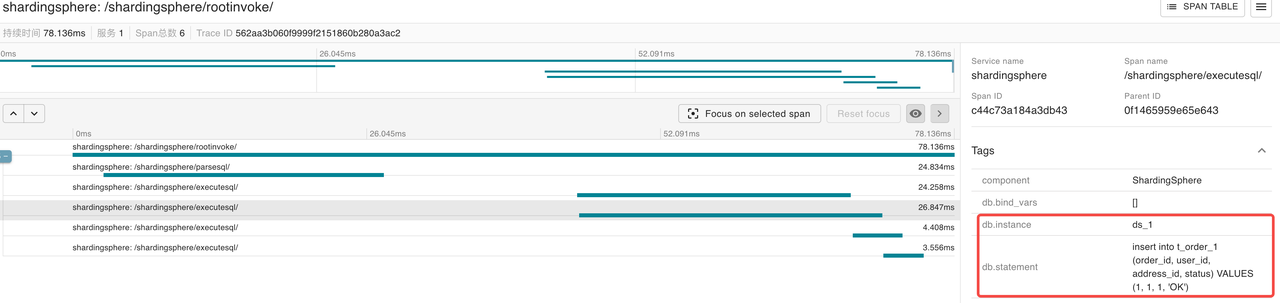
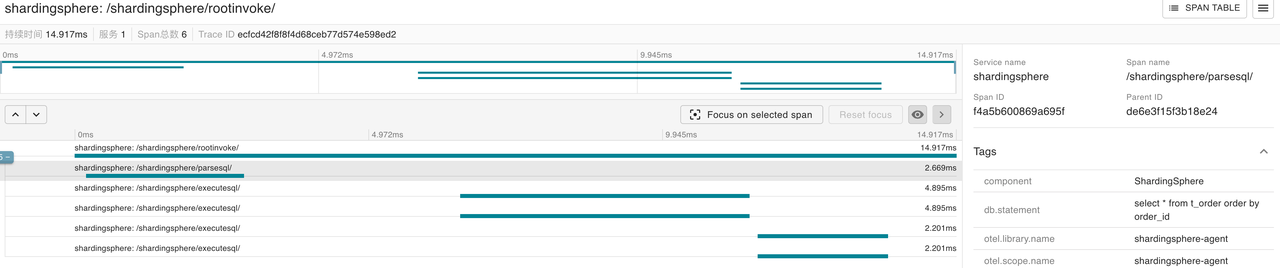
Let’s analyze the trace of the insert query. After finding the trace, you can see the execution details of this query. The Tags information in the /shardingsphere/parsesql/ span shows that the parsed SQL is consistent with the SQL executed on the client.
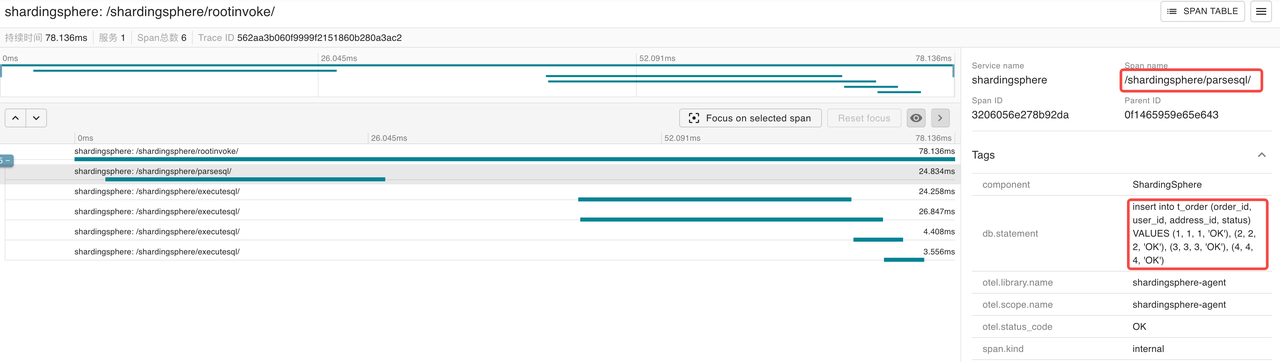
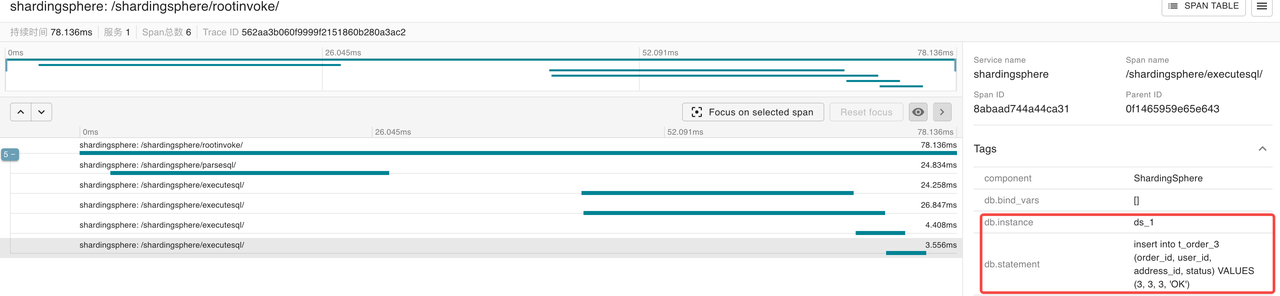
There are 4 /shardingsphere/executesql/ spans shown in the span table. After reviewing the details, it is found that the following two SQL statements were executed in the storage unit ds_0:
insert into t_order_0 (order_id, user_id, address_id, status) VALUES (4, 4, 4, 'OK')
insert into t_order_2 (order_id, user_id, address_id, status) VALUES (2, 2, 2, 'OK')
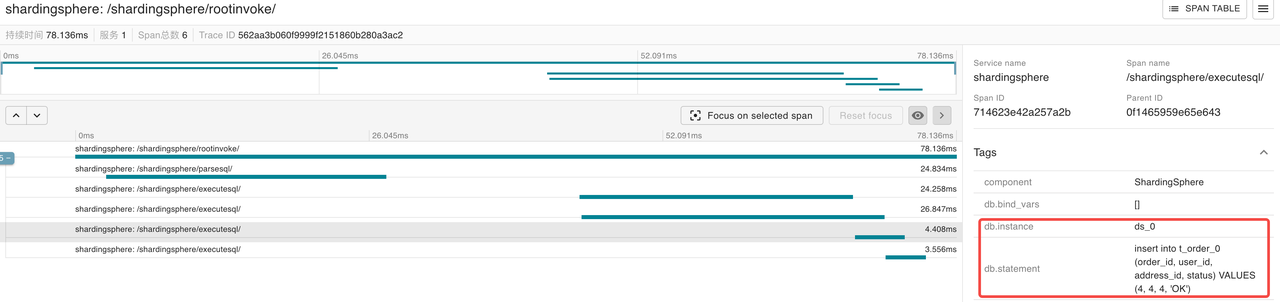
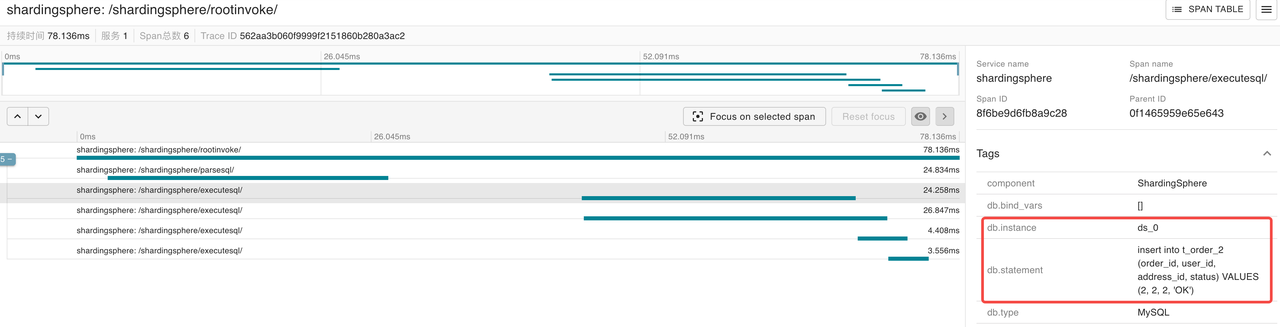
The following two SQL statements are executed in the storage unit ds_1
insert into t_order_1 (order_id, user_id, address_id, status) VALUES (1, 1, 1, 'OK')
insert into t_order_3 (order_id, user_id, address_id, status) VALUES (3, 3, 3, 'OK')
Then log in to the physical database to check the corresponding data (after executing the insert query)
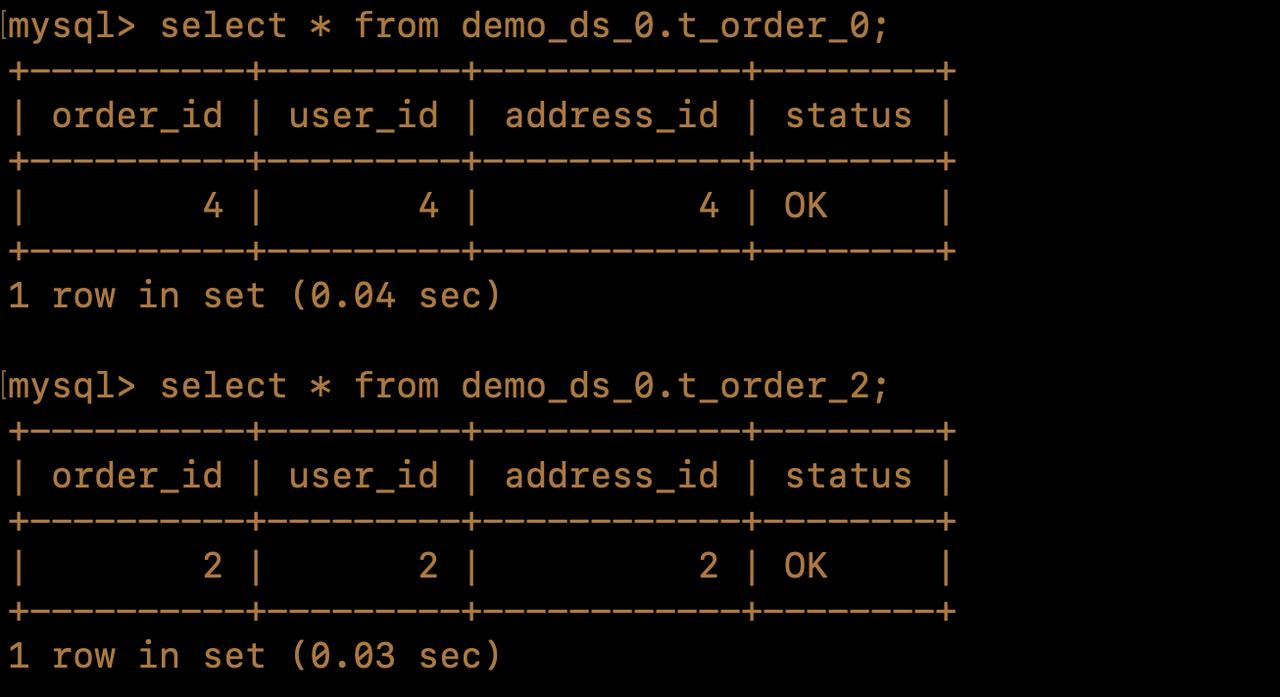
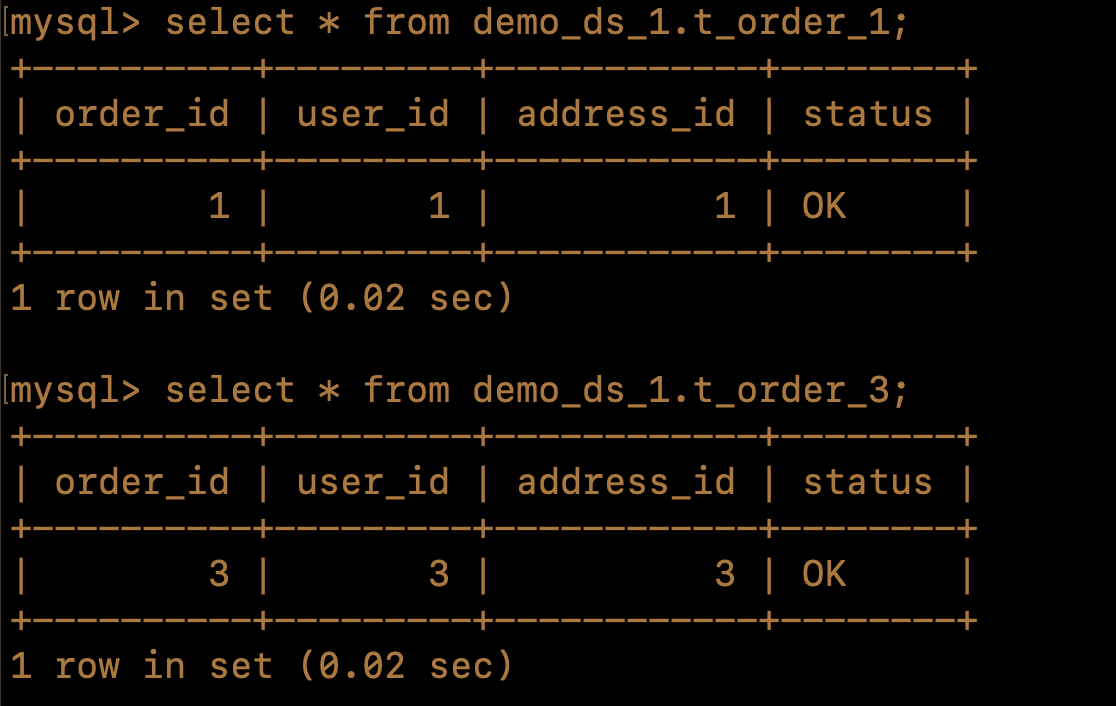
Due to the t_order table being partitioned into 4 shards and data with order_id 1 to 4 being inserted, one record will be inserted into each of the t_order_0, t_order_1, t_order_2, and t_order_3 tables. As a result, there will be 4 /shardingsphere/executesql spans. The displayed SQL trace is consistent with the actual execution results. So you can view the time spent on each step through the span and also know the specific execution of the SQL through the /shardingsphere/executesql/ span.
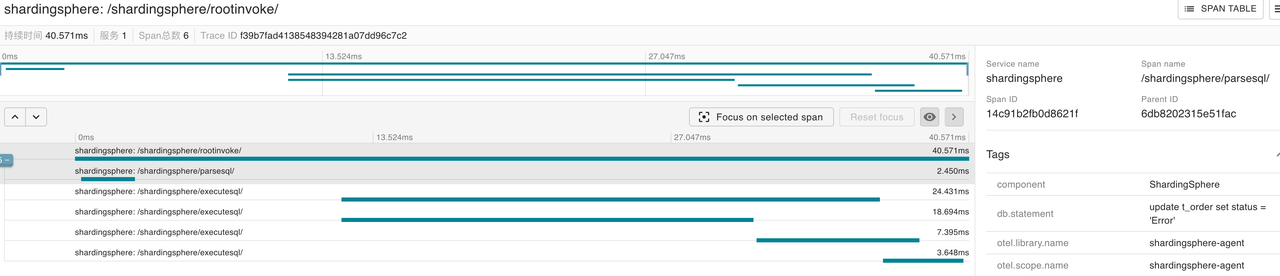
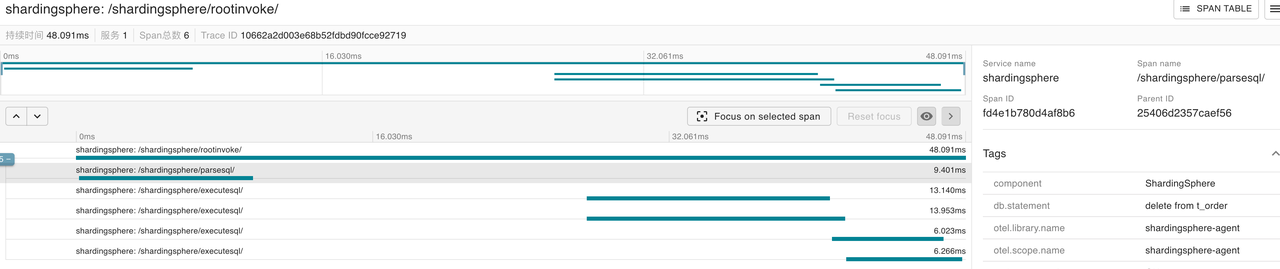
The following is the trace details of the select, update, and delete queries, which are also consistent with the actual situation.
Reporting to Jaeger
- Deploy Jaeger (please refer to the official website [4])
- Deploy Proxy
- Configure
agent.yaml
plugins:
tracing:
OpenTelemetry:
props:
otel.service.name: "shardingsphere" # the service name configured
otel.traces.exporter: "jaeger" # Use jaeger exporter
otel.exporter.otlp.traces.endpoint: "http://localhost:14250" # the address where jaeger receives data
otel.traces.sampler: "always_on" # sampling setting
otel.metrics.exporter: "none" # close OpenTelemetry metric collection
- Restart Proxy and Agent after stopping Proxy (
--agentmeans enabling Agent)
./bin/stop.sh
./bin/start.sh --agent
- Log into Proxy and execute SQL queries under the
sharding_dbdatabase (this SQL query is same as the ones executed in the Zipkin example) - From http://127.0.0.1:16686/ (Jaeger UI address), you will see 4 trace data, same as the number of executed SQL queries.
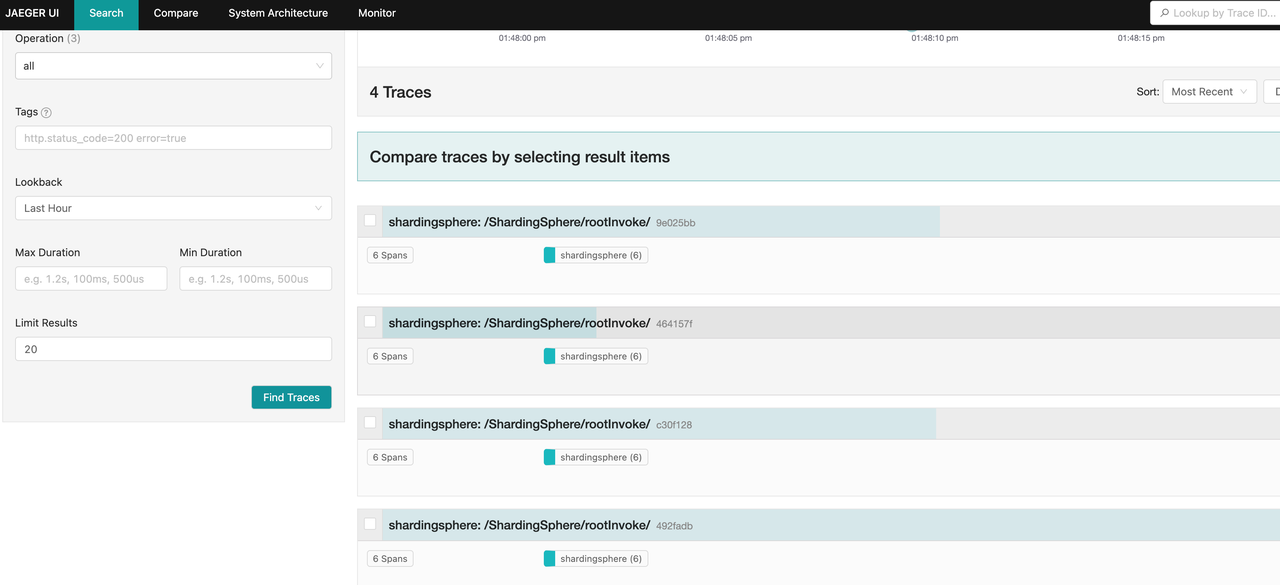
Since the executed SQL queries are the same as those in the Zipkin example, the trace data should also be the same. As an example, we will use the trace from the insert query.
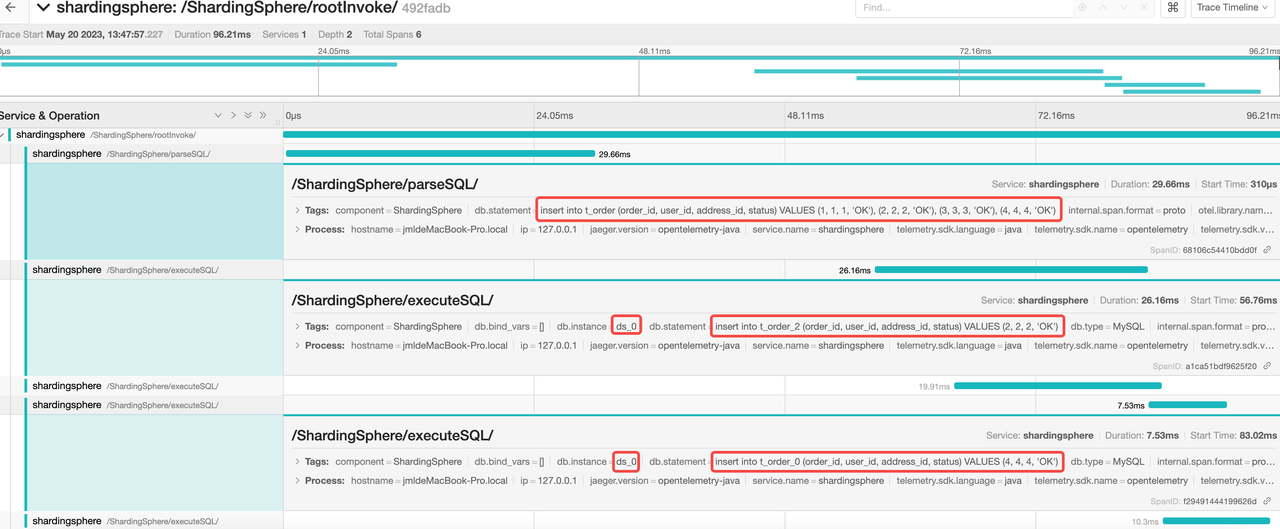
From the following picture, their are one parsed span and 4 executed span

Storage unit ds_0 has executed the following two SQL statements
insert into t_order_0 (order_id, user_id, address_id, status) VALUES (4, 4, 4, 'OK')
insert into t_order_2 (order_id, user_id, address_id, status) VALUES (2, 2, 2, 'OK')
Storage unit ds_1 has executed the following two SQL statements
insert into t_order_1 (order_id, user_id, address_id, status) VALUES (1, 1, 1, 'OK')
insert into t_order_3 (order_id, user_id, address_id, status) VALUES (3, 3, 3, 'OK')
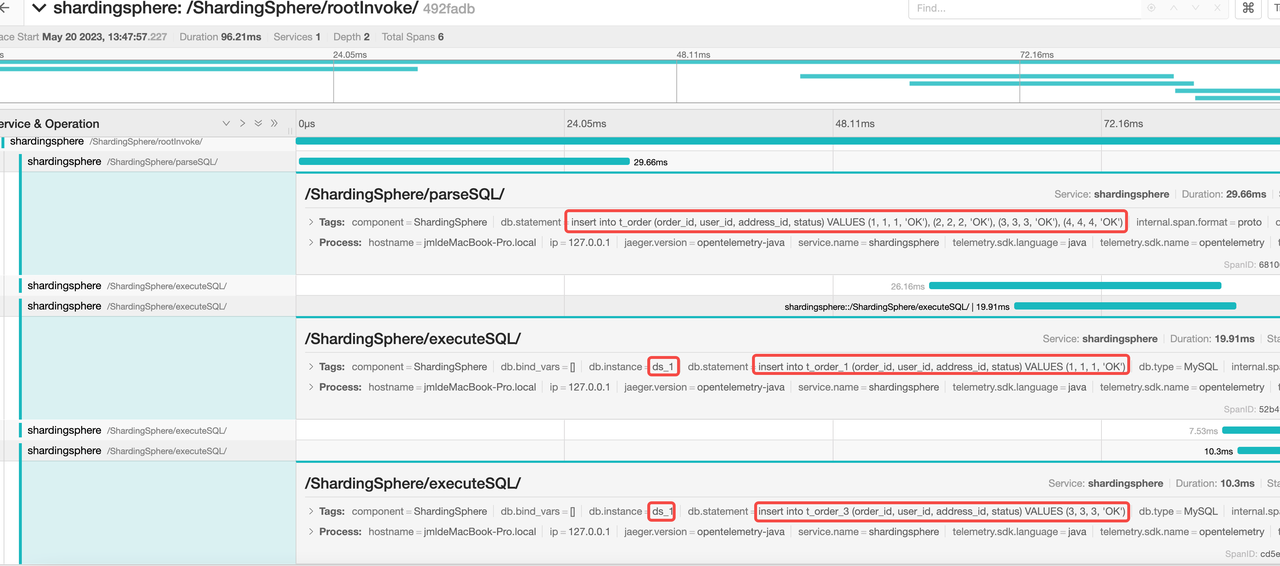
By analyzing the span number, the parsing result of SQL statement and the execution process, it is concluded that the whole SQL link is in line with the expectation
Use Sampling Rate
Sampling is very common when the amount of trace data in the production environment is very large. Shown as follows, set the sampling rate to 0.01 (sampling rate of 1%). OpenTelemetry Exporters is used for exporting data here, and please refer to the OpenTelemetry Exporters document for detailed parameters. [5]
plugins:
tracing:
OpenTelemetry:
props:
otel.service.name: "shardingsphere"
otel.metrics.exporter: "none"
otel.traces.exporter: "zipkin"
otel.exporter.zipkin.endpoint: "http://localhost:9411/api/v2/spans"
otel-traces-sampler: "traceidratio"
otel.traces.sampler.arg: "0.01"
Summary
SQL Tracking allows developers and DBAs to quickly diagnose and locate performance bottlenecks in applications. By collecting SQL tracing data through ShardingSphere-Agent and using visualization tools such as Zipkin and Jaeger, the time-consuming situation of each storage node can be analyzed, which helps to improve the stability and robustness of the application, and ultimately enhances the user experience.
Finally, you’re welcome to join ShardingSphere slack channel[6] to discuss your questions, suggestions or ideas about ShardingSphere and ShardingSphere-Agent.
Useful Links
[1] Download ShardingSphere-Proxy
[2] DistSQL document
[3] Zipkin official
[4] Jaeger official