Chaos Engineering: Efficient Way to Improve System Availability

Resilience is a crucial requirement for ShardingSphere-Proxy, an essential database infrastructure. Testing and verifying resilience can be efficiently achieved through the use of chaos engineering methodology. To support customized chaos engineering, the ShardingSphere-on-Cloud project is designing and implementing a new CustomResourceDefinition (CRD) called Chaos. This post provides a practical description of CRD’s concept and features, helping the community better understand its potential benefits.
What is chaos engineering
System availability is a critical metric for evaluating service reliability. Numerous methods can ensure high availability, including engineering resilience and techniques, and others. One such technique is chaos engineering, which involves introducing software faults into production systems to enhance availability.
According to Principles of Chaos (2019), the definition of chaos engineering is:
“Chaos Engineering is the discipline of experimenting on a system to build confidence in the system’s capability to withstand turbulent conditions in production.”
In other words, chaos engineering is a practice that aims to enhance system robustness by detecting potential weaknesses in software systems early, ultimately preventing major disruptions or failures.
Why is chaos engineering needed
The complexity of a system can be shown in a linear and nonlinear way as well as reflect how changes in the input of a system affect the output.
A linear system is typically predictable. There are many examples of linear systems in nature, such as simple mathematical functions and physical definitions.
In contrast, the output of a nonlinear system cannot be accurately calculated. In a large distributed program, components interact with each other, and we cannot determine if expected output can be achieved under various inputs.
Currently, most programs are increasingly complex. In common cloud environments, coordinating various components is becoming more challenging (such as Kubernetes, along with the services running on it, like Istio, Envoy, and other software infrastructure).

The complexity and rapid changes inherent to many systems often lead to developers having a narrow understanding of the overall picture. For example, developers behind a mall system may not familiar with the technical details of the infrastructure they adopted. With increased complexity, any single person’s understanding on the model built by the system may become less accurate. Hence, gaining a complete comprehension of a complex system is not realistic.
Chaos is inherent and describes an unknown state in complex systems. Chaos engineering is used to discover chaos in complex systems, learn the behavior of the system, and develop the ability to respond to failures and restore the system to a steady state.
The guidelines and practical ways of chaos engineering
Formulate a hypothesis about steady-state
Every experiment begins with a hypothesis, often taking the form of “even in XYZ circumstances, the system remains in a steady state.” This principle emphasizes the establishment of hypotheses based on defining steady states. Therefore, we should define various indicators of the system’s normal state based on long-term monitoring of the production environment and focus on measurable outputs, rather than internal properties of the system.
When identifying a steady state, it’s often essential to consider the global outputs of the system, such as running logs, performance logs, alerts, and program behavior, and abstract them into steady-state conditions. Having introduced experimental variables (faults), these steady-state conditions should change as expected.
When the system is in the steady state we defined, we should consider that the system can provide services normally to the outside world. In addition, monitoring the steady state is also important so that the system can recover to the steady state in a short period of time.
Introducing diverse real-world events
We ought to introduce events that are real and what we care about such as trying to reproduce faults that occurred in the production environment, such as cache avalanche, service degradation, etc.
Behaviors that would lead to the same fault symptoms should not be introduced, such as occupying all the memory, CPU, or disk of a service instance or ‘killing’ the instance, which system responds to bad requests. Testing should focus on the system’s behavior after a fault occurs, rather than on how to trigger the fault.
Experiments in the production environment
When conducting experiments, we can learn about the relevant behaviors of the system and establish confidence in the system. If we conduct experiments in a test environment, we can only establish confidence in that specific test environment. If there are differences between the production environment and the test environment, we cannot establish confidence in the production environment.
This is because a complex system is a whole, environmental differences between testing and production environments can render testing environment experiments meaningless, causing a “Bullwhip-effect”. However, conducting experiments in the production environment may affect users of the system and cause losses. We need to make trade-offs in the formal environment and let the experimental tools mature in the quasi-production environment before routing the experiments to a small portion of traffic in the production environment.
Automate experiments
When testing massive experiment sets are required, automating the process is more efficient than manually setting experiment environments, introducing faults, and gathering results. Automated experiments save time, run continuously, and can cover a larger number of experiment sets.
When repeat experiments are required, hypotheses are not always true, and they can be expired following iterated software, so periodic conducting regression experiments are needed.
Minimize the blast radius
Safe experiment methods can reduce the risk to the production environment, such as using traffic shadowing or selecting a suitable time period. An indicator in a small variable group is more significant compared to a small control group.
Chaos maturity model
Chaos maturity model provided a model map, based on different positions to measure different types of chaos engineering in practice.
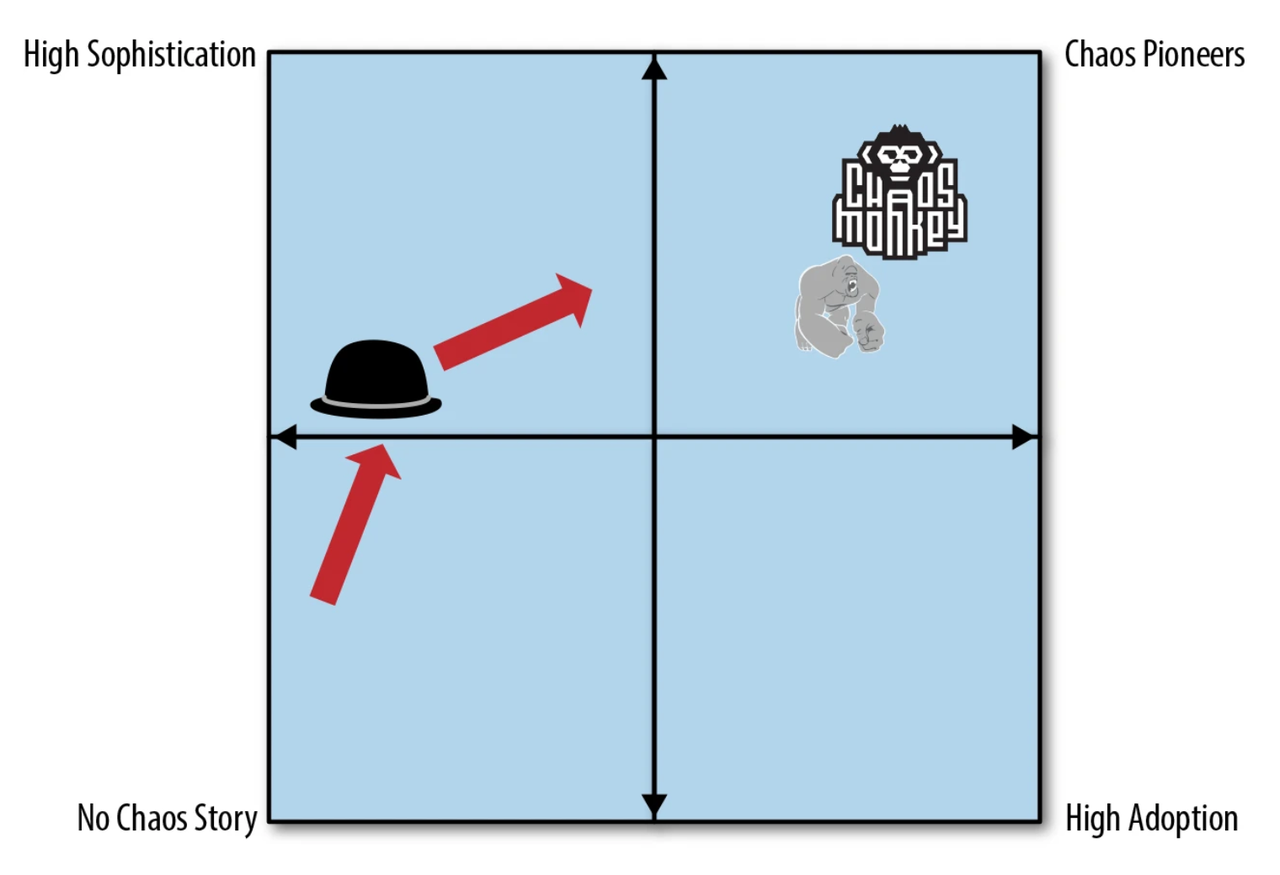
There are two axes on the map, adoption on the X-axis and sophistication on the Y-axis, which can be explored separately:
Adoption
As chaos engineering becomes mature, chaos engineering software needs to achieve a specific level that robustness validation alone can significantly affect the compliance process. However, initial adoption of chaos engineering generally starts from scratch.
Sophistication
Sophistication has some different metrica: provide consultation services and provide a set of tools. Due to the software infrastructure’s diversity, no tool can abstract sophisticated chaos engineering experiment instances in all environments and apply it in reality. Thus, chaos engineering practices were contributed from massive labor inputs, then customized solutions were gradually developed.
Another way to understand sophistication engineering is to consider the system levels and introducing system experiment variables. Experiments typically start at the infrastructure level with killing pods or virtual machines at the initial. During the initial stages of chaos experiments, the common approach is to use methods such as killing pods or virtual machines. As the tools become more sophisticated, chaos injection logic may be introduced into the target system, impacting the requests between services.
Additionally, when experimental variables affect business logic, we can observe more complex experiments. For instance, returning feasible but unexpected request responses to a service can lead to different results by programs. The experiments in the system will be conducted from the infrastructure layer to the application layer, and then to the business logic layer. Moreover, low-granularity experiments such as those that tend to trigger potential faults in the business logic layer are to be prioritized.
Continuous verification
“Continuous verification (CV) is a discipline of proactive experimentation, implemented as tooling that verifies system behaviors.” — Casy Rosenthal
Continuous validation development tools are a prime example of complexity in the chaos maturity model. CV, like CI/CD, addresses the need for increasingly complex operational systems. Due to resource constraints, system developers cannot afford to verify internal plans, and must instead focus on validating the system’s output meets desired expectations. That’s why CV is better than verification and also this is a successful sign of managing complex systems.
There are at least three types of continuous verification: feature testing, data artifacts, and correctness.
Feature Testing: based on the various performance indicators (concurrency, latency deviation, execution speed, etc.), and through observation of actual production traffic, the report and recognition of this test will be established.
Data artifacts: databases and storage applications have various requirements for the characters of writing and retrieving data, such as transaction consistency, idempotence, incorrect data isolation levels, etc.
Correctness: not all correct forms are manifested as a certain state or ideal attribute. In some cases, the interaction between different components must be taken by interface contracts or agreements. When an interface request returns a seemingly correct result that is beyond its judgement logic, unexpected errors may occur. The reason for such issues is that different levels of code are consistent at the logical level but inconsistent between layers.
Open-source chaos engineering platform
Litmus Chaos
Litmus Chaos is a chaos engineering platform that provides cross-cloud services. It’s a CNCF open-source project that many organizations have used. Litmus Chaos’s mission is to help Kubernetes SRE and developers to find weaknesses in non-Kubernetes platforms and applications that run on Kubernetes.
Chaos Mesh
Chaos Mesh is a chaos engineering platform open-sourced by PingCAP. It has a strong capability to orchestrate failure scenarios and provide comprehensive failure simulation types, which allow users to simulate the faults that might occur in production and testing environments and helps them identify potential failures. Chaos Mesh provides comprehensive visual tools to help beginner programmers conveniently run and monitor their own chaos scenarios. Chaos Mesh was developed based on Kubernetes CRD, mainly including three components:
- Chaos Dashboard: a visible platform of Chaos Mesh, provides a user-friendly WebUI, allowing users to design, monitor for Chaos, and manage RABC permits.
- Chaos Controller Manager: core logical components of Chaos Mesh, able to schedule users’ designed Chaos CR. The component includes many CRD Controllers, such as PodChaos Controller, WorkerFlow Controller, etc.
- Chaos Daemon: the main execution component of Chaos Mesh. Chaos Daemon runs as DeamonSet, and holds Privileged access by default (opt-in). Generally, this component interferes with network equipment, file systems, and kernels by invasion to target Pod Namespace.
Chaos Blade
Chaos Blade is a chaos engineering project designed and open-sourced by Alibaba in 2019, which includes the chaos engineering experiment tool Chaos Blade and platform Chaosblade-box. It helps enterprises solve high availability issues during cloud-native processes through chaos engineering.
Chaosblade supports three big platforms, four computing language applications, involves over 200 experimental scenarios, and over 3000 parameters, allowing for fine control of the experimental scope.
ChaosBlade-Box supports the management of experimental tools, and in addition to managing Chaos Blade, it also supports the aggregation of experimental tools from other platforms such as Litmuschaos.
Conclusion
To introduce chaos engineering into a certain system, we can refer to the chaos maturity model and start with simple inputs. In the case of our community, we can agree upon a date for developers of various components in the system to perform a fault test together, record the results to enhance the sense of participation and importance of chaos engineering for contributors. We’ll then observe system behavior, define steady states, and design reasonable chaos experiment plans. These experiments can be conducted in pre-production or production environments to discover and learn new behaviors of the system and enhance the community’s ability to handle faults. Afterwards, we can design automated experiments and use regression testing to ensure the correctness of experimental hypotheses. By the way, Chaos is coming soon to the 0.3.0 version, stay tuned!