如何观测集群的运行状态,使运维人员可以快速掌握当前系统现状,并进行进一步的维护工作,是分布式系统的全新挑战。 登录到具体服务器的点对点运维方式,无法适用于面向大量分布式服务器的场景。 通过对可系统观察性数据的遥测是分布式系统推荐的运维方式。 Tracing(链路跟踪)、 Metrics(指标监控)和 Logging (日志)是系统运行状况的可观察性数据重要的获取手段。
APM(应用性能监控) 是通过对系统可观察性数据进行采集、存储和分析,进行系统的性能监控与诊断,主要功能包括性能指标监控、调用链分析,应用拓扑图等。
Apache ShardingSphere 并不负责如何采集、存储以及展示应用性能监控的相关数据,而是为应用监控系统提供必要的指标数据。 换句话说,Apache ShardingSphere 仅负责产生具有价值的数据,并通过标准协议或插件化的方式递交给相关系统。
Tracing 用于获取 SQL 解析与 SQL 执行的链路跟踪信息。Apache ShardingSphere 默认提供了对 SkyWalking,Zipkin,Jaeger 和 OpenTelemetry 的支持,也支持用户通过插件化的方式开发自定义的 Tracing 组件。
使用 Zipkin 和 Jaeger 通过在agent配置文件中开启对应的插件,并配置好 Zipkin 或者 Jaeger 服务器信息即可。
使用 OpenTelemetry OpenTelemetry 在 2019 年由 OpenTracing 和 OpenCencus 合并而来。 使用这种方式,只需要在 agent 配置文件中,根据 OpenTelemetry SDK 自动配置说明 ,填写合适的配置即可。
使用 SkyWalking 需要在 agent 配置中配置启用对应插件,并且需要同时配置使用 SkyWalking 的 apm-toolkit 工具。
使用 SkyWalking 的内置自动探针 Apache ShardingSphere 团队与 Apache SkyWalking 团队共同合作,在 SkyWalking 中实现了 Apache ShardingSphere 自动探针,可以将相关的应用性能数据自动发送到 SkyWalking 中。注意这种方式的自动探针不能与 Apache ShardingSphere 插件探针同时使用。
Metrics 则用于收集和展示整个集群的统计指标。Apache ShardingSphere 默认提供了对 Prometheus 的支持。
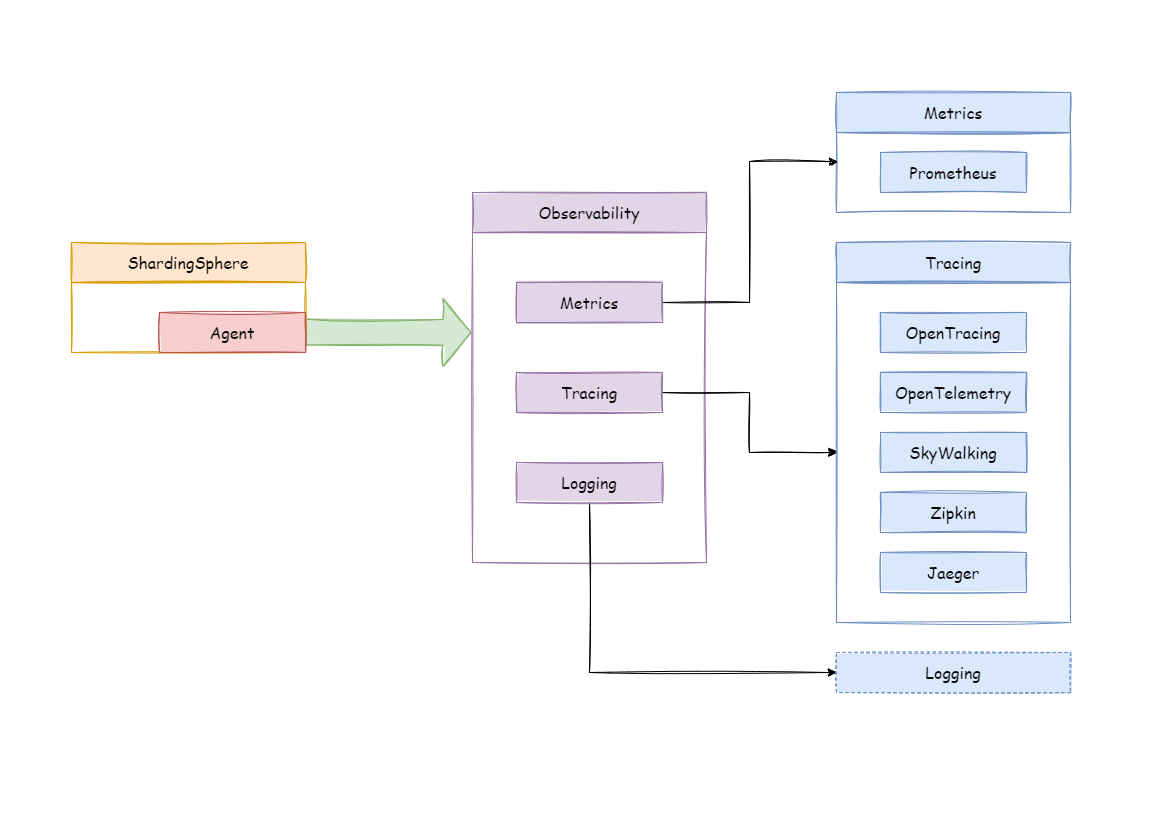
Tracing 和 Metrics 需要通过埋点来收集系统信息。 大量的埋点使项目核心代码支离破碎,难于维护,且不易定制化统计指标。
提供尽量多的性能和统计指标,并隔离核心代码和埋点代码,是 Apache ShardingSphere 可观察性模块的设计目标。
ShardingSphere 通过 Agent 模块为应用提供可观察性的能力,可适用于以下场景:
将系统静态信息(如应用版本)和动态信息(如线程数、SQL 处理信息)等 Metrics 指标,使用标准接口方式暴露给第三方应用(如 Prometheus),管理员能够通过可视化的方式监控系统实时状态。
在 ShardingSphere 中,一条 SQL 语句要经历解析、路由、改写、执行、结果归并等流程才能最终执行完成,并输出响应。如果 SQL 语句复杂,整体执行耗时过长,如何知道哪一步存在优化空间呢?
通过 Agent + Tracing,管理员可以了解 SQL 执行过程中每一步的耗时情况,轻松定位性能风险,从而能够有针对性的制定 SQL 优化方案。
在分布式应用 + 数据分片的场景下,SQL 语句是哪个节点发出的,最终在哪些数据源执行?这是一个非常棘手的问题。如果 SQL 执行过程中发生异常,如何定位发生异常的节点呢?
Agent + Tracing,能够帮助用户解决以上问题。
通过对 SQL 执行过程的完整链路追踪,用户可以得到 “SQL 从哪里来,发到哪里去” 这样的完整信息,还能够通过生成的拓扑图来直观的观察 SQL 路由情况,运筹帷幄,同时获得快速定位问题根源的能力。