ShardingSphere 数据分片的原理如下图所示,按照是否需要进行查询优化,可以分为 Simple Push Down 下推流程和 SQL Federation 执行引擎流程。 Simple Push Down 下推流程由 SQL 解析 => SQL 绑定 => SQL 路由 => SQL 改写 => SQL 执行 => 结果归并 组成,主要用于处理标准分片场景下的 SQL 执行。
SQL Federation 执行引擎流程由 SQL 解析 => SQL 绑定 => 逻辑优化 => 物理优化 => 数据拉取 => 算子执行 组成,SQL Federation 执行引擎内部进行逻辑优化和物理优化,在优化执行阶段依赖 Standard 内核流程,对优化后的逻辑 SQL 进行路由、改写、执行和归并。
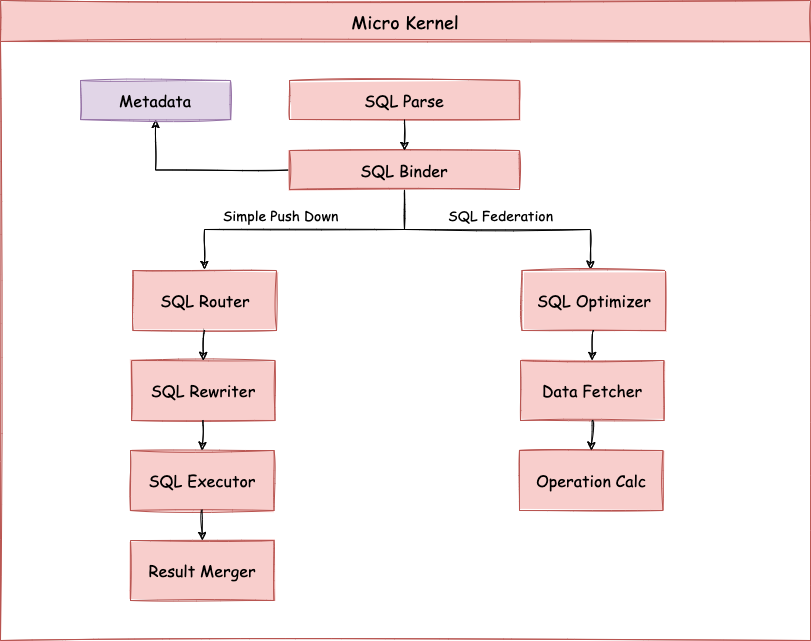
分为词法解析和语法解析。 先通过词法解析器将 SQL 拆分为一个个不可再分的单词。再使用语法解析器对 SQL 进行理解,并最终提炼出解析上下文。 解析上下文包括表、选择项、排序项、分组项、聚合函数、分页信息、查询条件以及可能需要修改的占位符的标记。
根据解析上下文匹配用户配置的分片策略,并生成路由路径。目前支持分片路由和广播路由。
将 SQL 改写为在真实数据库中可以正确执行的语句。SQL 改写分为正确性改写和优化改写。
通过多线程执行器异步执行。
将多个执行结果集归并以便于通过统一的 JDBC 接口输出。结果归并包括流式归并、内存归并和使用装饰者模式的追加归并这几种方式。
由 Federation 执行引擎(开发中)提供支持,对关联查询、子查询等复杂查询进行优化,同时支持跨多个数据库实例的分布式查询,内部使用关系代数优化查询计划,通过最优计划查询出结果。