Apache ShardingSphere 是一款开源的分布式数据库生态项目,由 JDBC 和 Proxy 两款产品组成。其核心采用微内核+可插拔架构,通过插件开放扩展功能。它提供多源异构数据库增强平台,进而围绕其上层构建生态。
Apache ShardingSphere 设计哲学为 Database Plus,旨在构建异构数据库上层的标准和生态。它关注如何充分合理地利用数据库的计算和存储能力,而并非实现一个全新的数据库。它站在数据库的上层视角,关注它们之间的协作多于数据库自身。

ShardingSphere-JDBC 定位为轻量级 Java 框架,在 Java 的 JDBC 层提供的额外服务。
![]()
![]()

ShardingSphere-Proxy 定位为透明化的数据库代理端,通过实现数据库二进制协议,对异构语言提供支持。
| 特性 | 定义 |
|---|---|
| 数据分片 | 数据分片,是应对海量数据存储与计算的有效手段。ShardingSphere 提供基于底层数据库之上,可计算与存储水平扩展的分布式数据库解决方案。 |
| 分布式事务 | 事务能力,是保障数据库完整、安全的关键技术,也是数据库的核心技术之一。ShardingSphere 提供在单机数据库之上的分布式事务能力,可实现跨底层数据源的数据安全。 |
| 读写分离 | 读写分离,是应对高压力业务访问的手段之一。ShardingSphere 基于对SQL语义理解及底层数据库拓扑感知能力,提供灵活、安全的读写分离能力,且可实现读访问的负载均衡。 |
| 数据迁移 | 数据迁移,是打通数据生态的关键能力。SharingSphere 提供基于数据全场景的迁移能力,可应对业务数据量激增的场景。 |
| 联邦查询 | 联邦查询,是面对复杂数据环境下利用数据的有效手段之一。ShardingSphere 提供跨数据源的复杂数据查询分析能力,简化并提升数据使用体验。 |
| 数据加密 | 数据加密,是保证数据安全的基本手段。ShardingSphere 提供一套完整的、透明化、安全的、低改造成本的数据加密解决方案。 |
| 影子库 | 在全链路压测场景下,ShardingSphere 通过影子库功能支持在复杂压测场景下数据隔离,压测获得测试结果可准确反应系统真实容量和性能水平。 |
驱动程序端历经长年打磨,效率接近原生 JDBC,性能极致。
代理端支持任何通过 MySQL/PostgreSQL 协议的应用访问,驱动程序端可对接任意实现 JDBC 规范的数据库。
面对数据库替换场景,ShardingSphere 可满足业务无需改造,实现平滑业务迁移。
在保留原技术栈不变前提下,对 DBA 学习、管理成本低,交互友好。
基于成熟数据库底座之上提供增量能力,兼顾安全性及稳定性。
具备计算、存储平滑在线扩展能力,可满足业务多变的需求。
通过多层次(内核、功能、生态)插件化能力,为用户提供可定制满足自身特殊需求的独有系统。
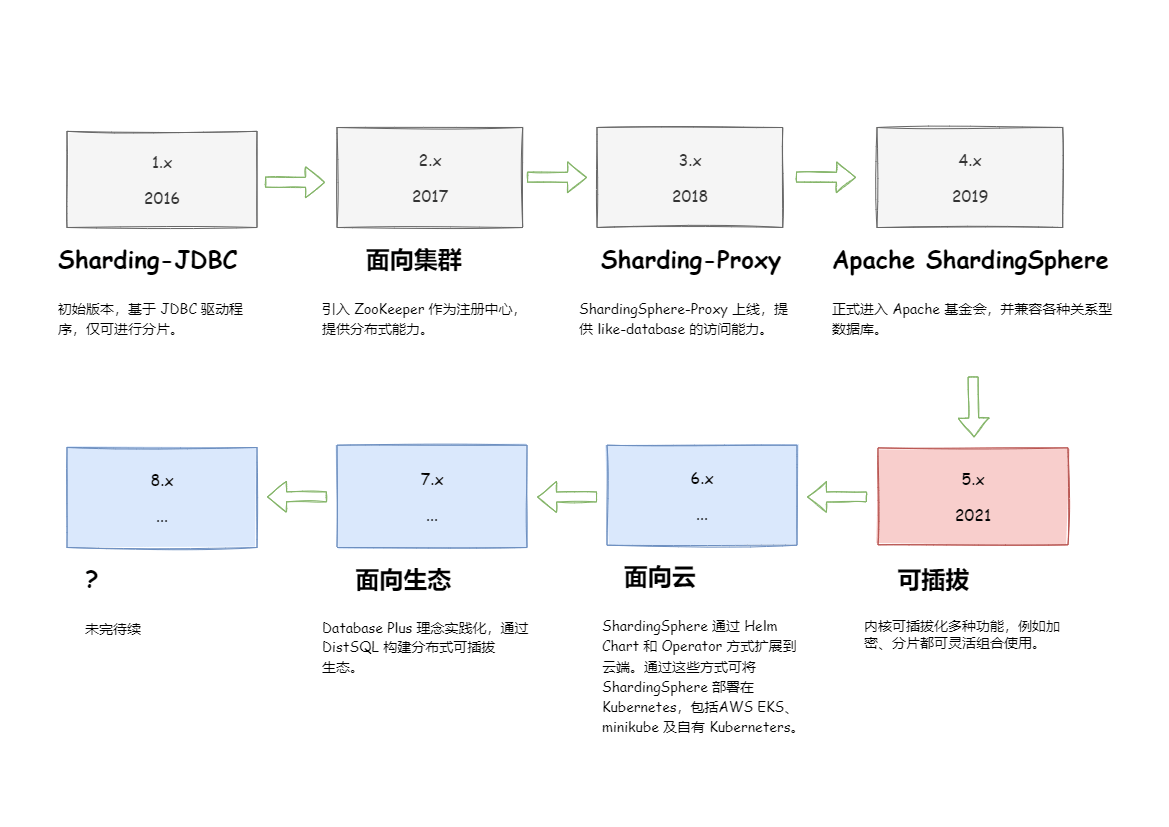
ShardingSphere 已于 2020 年 4 月 16 日成为 Apache 软件基金会的顶级项目。 欢迎通过邮件列表参与讨论。