How South Korea’s Yogiyo Improved Scalability and Performance with Apache ShardingSphere
Yogiyo is South Korea’s leading mobile and online food delivery platform that seeks to offer customers powerful and convenient food ordering services. Formerly a subsidiary of Delivery Hero, Yogiyo was acquired by GS Retail, one of Korea’s top ten listed companies, for $684 million at the end of 2021.

Hello! My name is Byungchul Kim, and I work as a backend developer at Yogiyo R&D Centre on Orderyo, an ordering service. In this post, I want to share our experience implementing Apache ShardingSphere for Yogiyo’s order service and explain how it helped us to solve technical debt and meet new requirements.
Order Service DB Structure
Let me start by showing you the structure of Yogiyo’s order service. When order creation, cancellation, or update traffic occurs, the Orderyo application code distributes the write load to four shard clusters based on the customer_id. This way, the application only needs the customer_id to find the shard cluster it needs to access and perform the operation.
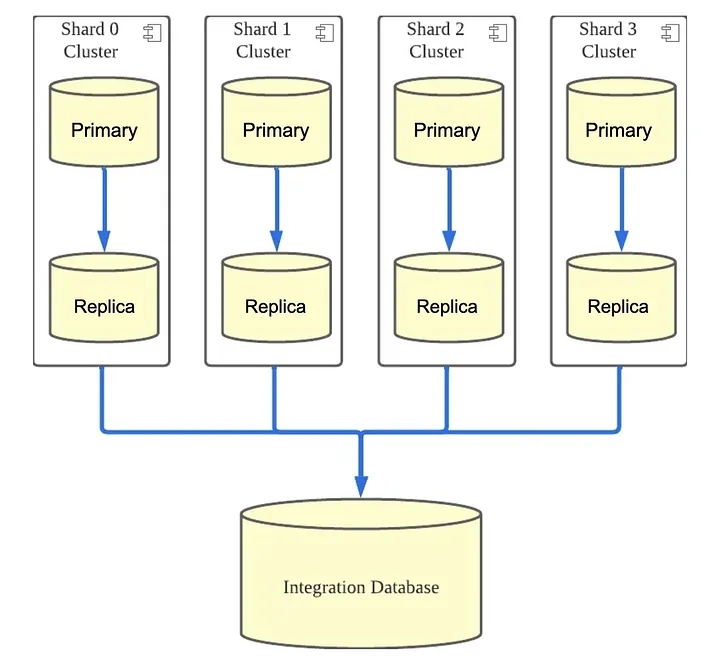
Introducing sharding to the order service has improved the overall response time of customer_id-based order functions, eliminated many bottlenecks at the database end by distributing the DB load, and allowed us to scale the DB appropriately for future traffic growth. However, we also realized a technical debt during the past year of implementing and running database sharding for Yogiyo’s order service. The structure of the DB did not reflect the integrated lookup requirements.
Most of the traffic from the order service functions has a customer_id, so we use a shard DB. In addition, we have the source data of the order, so there is a requirement for an integrated query without sharding key in the operation-oriented and boss-oriented functions. To support operational queries, we collected data by replicating from shard DBs to a single DB, which we called the Integration DB.
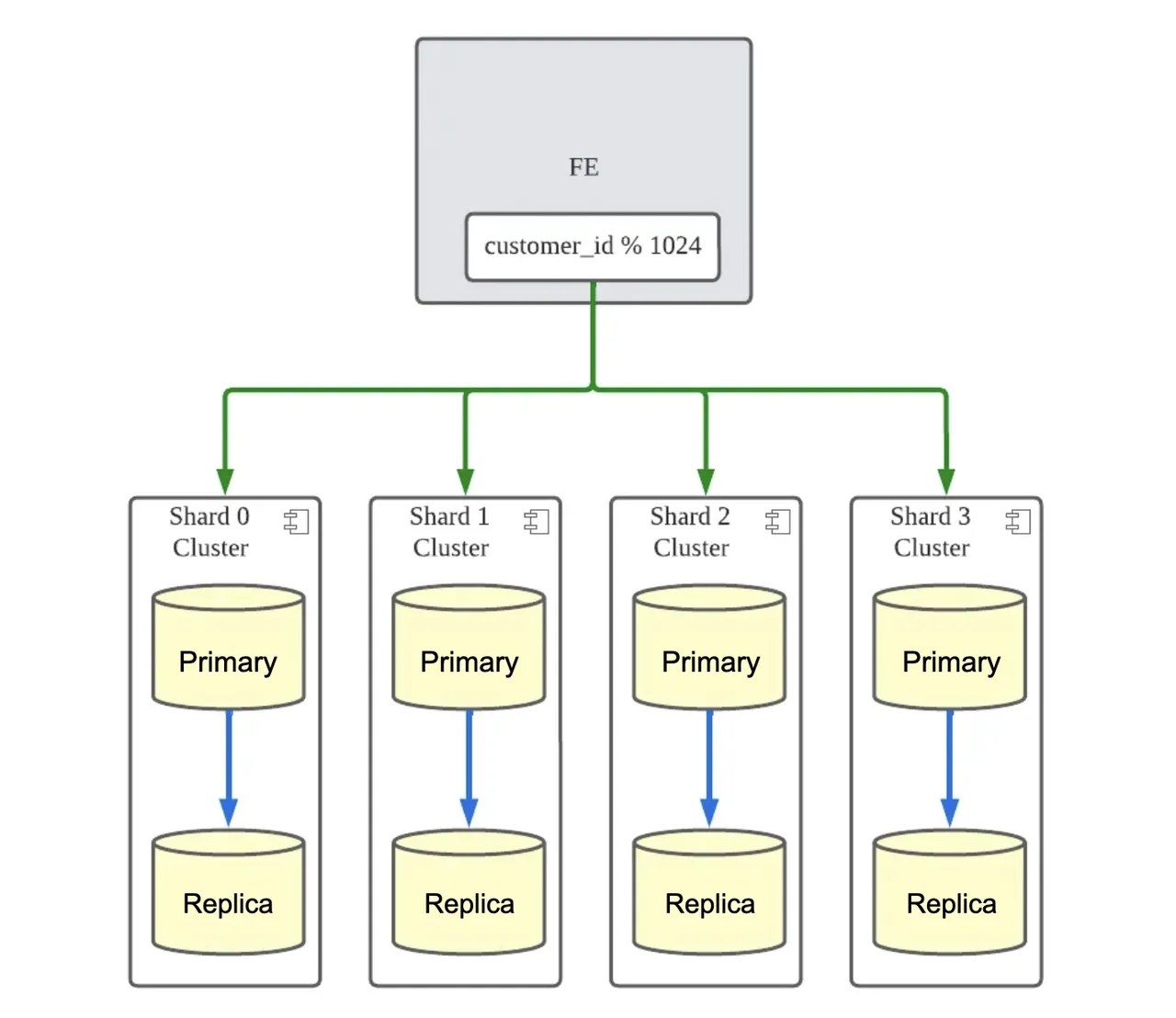
In this structure, as the throughput of the shards increases, the load is placed on the single Integration DB, making it a bottleneck. This means that horizontal DB scaling, one of the advantages of sharding, is not available.
In our tests, the threshold for horizontal scaling was well above our current traffic, but with new requirements, this became an issue that needed to be addressed.
Previously, we only needed to support production-oriented queries, but the new requirement was to support production-oriented functional queries, which are much more traffic-heavy and DB-intensive than traditional production queries.
How ShardingSphere-Proxy was adopted
To solve this problem, we decided to use Apache ShardingSphere. It is a project that aims to build a distributed database ecosystem and allows RDBs to be sharded and run as a distributed database environment. We chose to adopt ShardingSphere-Proxy, a database proxy server provided by the Apache ShardingSphere project, to move the queries that used Integration DB to the database proxy server.
One of the reasons I chose Apache ShardingSphere was that it was easy to deploy ShardingSphere-Proxy, and it did not require any changes to the existing DB structure.
After following the tutorial in my local environment, I validated it on a staging server for a period of time and roadtested it to see if there was any performance impact before moving it into production.
Setting up the local environment
To implement ShardingSphere, we first set up the same environment as the service currently running locally. We set up the following Mysqld settings to increase the p.k. of each table with 1024 in common and different offsets for the shard DB. This way, the tables can have unique p.k. even if they are split into shards.
Configuration for Shard 0
[mysqld]
server_id=20
auto_increment_increment = 1024
auto_increment_offset = 1
Configuration for Shard 1
[mysqld]
server_id=21
auto_increment_increment = 1024
auto_increment_offset = 2
We then set the two DBs as DataSources and set the rule for sharding DB on the ShardingSphere proxy server so that it can find the logical database, ds, based on the id, which is the primary key of the table. We excluded the tables that are created by default in the Django framework with broadcastTables so that they do not need to be sharded.
######################################################################################################
#
# Here you can configure the rules for the proxy.
# This example is the configuration of the sharding rule.
#
# If you want to use sharding, please refer to this file.
# If you want to use primary-replica, please refer to the config-master_slave.yaml.
#
######################################################################################################
databaseName: orderyo
dataSources:
ds_0:
url: jdbc:mysql://sharding-sphere-mysql-shard-0:3306/orderyo?serverTimezone=Asia/Seoul&useSSL=false&characterEncoding=UTF-8
username: root
password: root
connectionTimeoutMilliseconds: 30000
idleTimeoutMilliseconds: 60000
maxLifetimeMilliseconds: 1800000
maxPoolSize: 50
ds_1:
url: jdbc:mysql://sharding-sphere-mysql-shard-1:3306/orderyo?serverTimezone=Asia/Seoul&useSSL=false&characterEncoding=UTF-8
username: root
password: root
connectionTimeoutMilliseconds: 30000
idleTimeoutMilliseconds: 60000
maxLifetimeMilliseconds: 1800000
maxPoolSize: 50
rules:
- !SHARDING
tables:
order_order:
actualDataNodes: ds_${0..1}.order_order
order_orderitem:
actualDataNodes: ds_${0..1}.order_orderitem
order_orderitemoption:
actualDataNodes: ds_${0..1}.order_orderitemoption
broadcastTables:
- django_admin_log,django_content_type,django_migrations,django_session
defaultShardingColumn: id
defaultDatabaseStrategy:
standard:
shardingColumn: id
shardingAlgorithmName: database-inline
defaultTableStrategy:
none:
shardingAlgorithms:
database-inline:
type: INLINE
props:
algorithm-expression: ds_${id % 1024 - 1}
Apply a staging environment
We then applied a staging environment to verify functionality and performance, using Django’s DBWrapper to send out a query to Integration DB and then send the same query to the ShardingSphere-Proxy server to compare the results and response time.
class IntegrationDatabaseWrapper:
def __call__(self, execute, sql, params, many, context):
db_alias = context["connection"].alias
if db_alias != settings.INTEGRATION_DB_READ_ONLY_NAME:
return execute(sql, params, many, context)
try:
integration_start = time.monotonic()
integration_result = execute(sql, params, many, context)
integration_execution_time = time.monotonic() - integration_start
except Exception as e:
raise e
else:
return integration_result
finally:
if config.INTEGRATION_DB_MODE == DatabaseMode.DUAL:
self._call_proxy_db(sql, params, integration_result, integration_execution_time)
def _call_proxy_db(self, sql, params, integration_result, integration_execution_time):
from django.db import connections
proxy_start = time.monotonic()
shardingsphere_cursor = connections[settings.SHARDINGSHPERE_PROXY_DB_READ_ONLY_NAME].cursor()
shardingsphere_result = shardingsphere_cursor.execute(sql, params)
shardingsphere_cursor.close()
proxy_execution_time = time.monotonic() - proxy_start
logger.info(....)
integration_db_wrapper = IntegrationDatabaseWrapper()
with connections[settings.INTEGRATION_DB_READ_ONLY_NAME].execute_wrapper(integration_db_wrapper):
do_queries()
During our testing on staging, we faced two issues: queries not functioning properly after a DB schema change, and discrepancies in query results.
After a more thorough examination of the open source code and documentation, I discovered that reflecting changes in table information on the ShardingSphere-Proxy server was necessary for fields that require data processing, like datetime order_by, when a DB schema change occurs.
To resolve this, we modified the deployment process to include automatic execution of the command in question whenever a schema change occurs.
REFRESH TABLE METADATA;
We identified that a query was returning different results due to a rather complex subquery, which wasn’t supported by the ShardingSphere project. To address this, we resolved the issue by removing the subquery and optimizing the query instead.
Load testing
After confirming the functional replacement in our local and staging environments, it was necessary to ensure that it would perform well when rolled out to production.
To achieve this, we enlisted our internal infrastructure and automation teams to conduct performance tests in the same environment as production. These tests involved comparing our existing Integration DB with the limitations imposed by the ShardingSphere-Proxy structure, and we utilized the testing tool locust to facilitate the process.
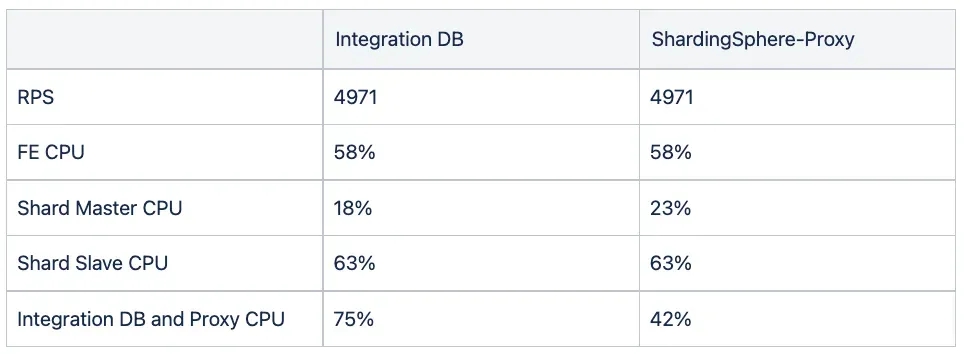
The performance tests revealed significant differences between the two structures within the same user pool.
Firstly, the Integration DB also requires resources to manage replication, which ultimately becomes a bottleneck as job creation load increases. This is evident in the high CPU metric of both the Integration DB and Proxy, which reach up to 75%. It’s clear that we will have scalability issues moving forward with this setup.
On the other hand, the ShardingSphere-Proxy structure distributes query distribution to the Primary, leading to an overall increase in the load on the Shard Replica. However, in production, we distribute queries to the shard replicas, which means that theoretically there is no limit to the scalability of the DB.
Wrap up
Yogiyo’s ordering service is one of the most DB-intensive services. Despite our proactive sharding efforts for horizontal scaling, we discovered that the environment we created to meet the needs of integration queries did not leverage sharding effectively.
After careful consideration, we decided to implement Apache ShardingSphere, an open-source solution that would revive the benefits of sharding and enable distributed processing, resulting in performance improvements of up to four times.
I hope this article helps those facing challenges with implementing an efficient sharding structure due to specific requirements. If I have the opportunity, I will write another article on the issues and performance enhancements related to using ShardingSphere.

To conclude, I would like to express my gratitude to my team, as well as the infrastructure and performance testing teams, for their invaluable support during the implementation of ShardingSphere.
Additionally, I would like to mention that we are currently seeking developers to join the Yogiyo ordering service.
We are specifically looking for candidates with experience in handling high volumes of traffic and technical challenges associated with it. If you are interested in joining our team, please do not hesitate to contact us. Thank you.