Apache ShardingSphere Enterprise User Case - Energy Monster
Energy Monster’s application of ShardingSphere-JDBC
Energy Monster is a consumer tech company with the mission to energize everyday life. The company is the largest provider of mobile device charging services in Asia.
As the company’s business concurrency volume is getting larger, the amount of data generated (users, orders, activities, etc.) increases each day. The traditional relational database has proven to be inadequate in supporting millions or tens of millions of data volumes in a single database or table.
Performance has been unable to meet the benchmark requirements of business development. Under these circumstances, data sharding is an effective way to solve the problem.
Technology selection
Under the Database Plus concept, ShardingSphere is designed to build an ecosystem on top of heterogeneous databases. The goal is to provide globally scalable and enhanced computing capabilities while maximizing the original database computing capabilities.
The interaction between applications and databases becomes oriented towards the Database Plus standard, therefore minimizing the impact of database fragmentation on upper-layer services.
Within the ShardingSphere ecosystem, ShardingSphere-JDBC is positioned as a lightweight Java framework, providing additional services in Java’s JDBC layer.
It uses the client to directly connect to the database and provide services in the form of a jar package, without additional deployment and dependence. It can be understood as an enhanced version of the JDBC driver, which is fully compatible with JDBC and various ORM frameworks.
ShardingSphere-JDBC enables developers to focus only on the work outside the data layer by coordinating the data read and write under the data sharding, instead of using business code to manually select databases and tables.
Business case
UCS is Energy Monster’s user-centric service providing basic functionality for users on the Server side. In 2018, it was stripped from PHP Server and moved to the Java technology stack to implement microservitization.
It involves the design of new databases and tables and data cleaning and migration. The whole switchover process was expected to ensure the following functions:
-
Stability: smooth release in a short time without halting.
-
Accuracy: ensure accurate cleaning of tens of millions of data volumes.
-
Scalability: solve the performance problems caused by increasing data volume and ensure scalability.
Solutions to data cleansing and migration
- Initial data synchronization.
- The application’s server cuts off the entry (users).
- Data synchronization (updates and new users since the last time point).
- Data cleaning.
- User center release.
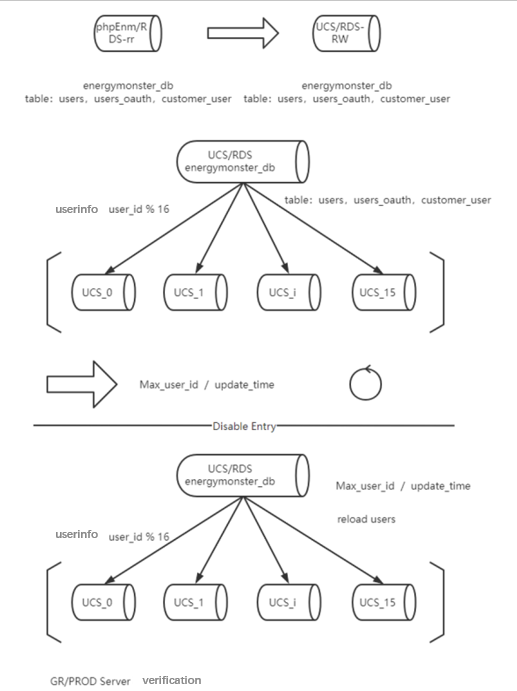
Data sharding strategy
The database adopts a database shards design, divided into 16 databases. The default shard key is user_id and the default sharding strategy user_id is mod 16, such as ${user_id % 16} for the user table. For SQL that does not carry shard keys, broadcast routing is used.
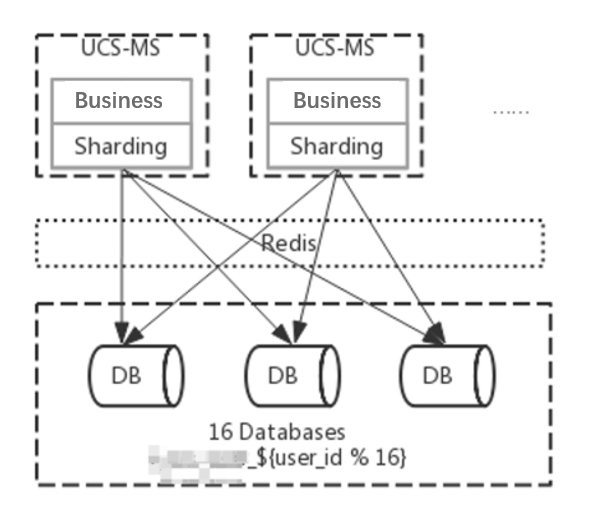
user_id is used as the shard key because user_id can cover most business scenarios, and other fields possibly can be empty. In the local test, the query of shard key strategy (openId,mobile) took 50ms to 200ms.
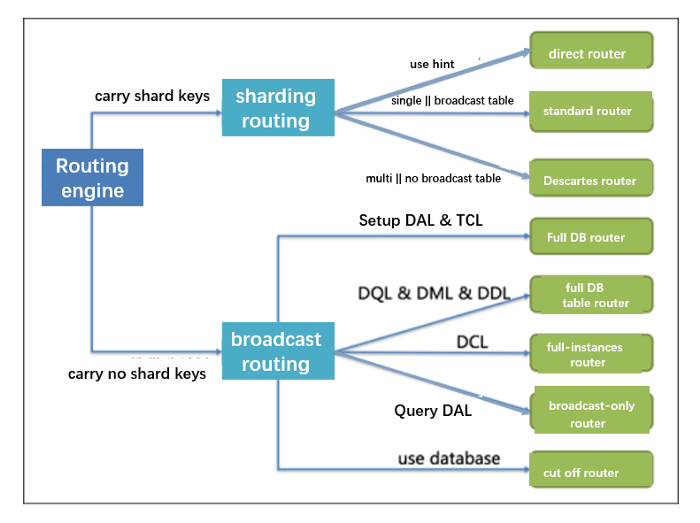
Using the sharding algorithm
There are currently three sharding algorithms available.
-
Standard sharding algorithm. It corresponds to
StandardShardingAlgorithm, used for scenarios that use a single key as the shard key, such as =, IN, BETWEEN AND, >, <, > =, < =. -
Complex sharding algorithm. It corresponds to
ComplexKeysShardingAlgorithm, used for scenarios that use multi-key as the shard key. The logic with multiple shard keys is complex and requires developers to handle it by themselves. -
Hint sharding algorithm. It corresponds to
HintShardingAlgorithm, used for scenarios where the Hint row is used for sharding.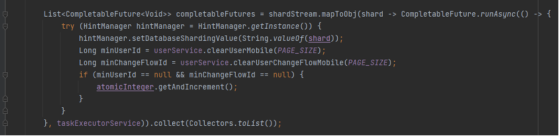
Upgrading ShardingSphere-JDBC
ShardingSphere-JDBC is used in multiple business scenarios, such as order, inventory, and finance. By 2021, the R&D groups or teams were using different versions of ShardingSphere-JDBC, ranging from 1.X to 4.X, which is difficult to achieve unified maintenance in the later stage.
Additionally, there are some potential bugs and missing functions in the earlier version. Based on requirements for unified management and availability, we implemented a project to unify the ShardingSphere-JDBC’s versions used by the company and upgrade them to a 4.1.1 stable version in April 2021.
The following problems were encountered during the upgrade:
1. It takes a long time to start the service after the upgrade.
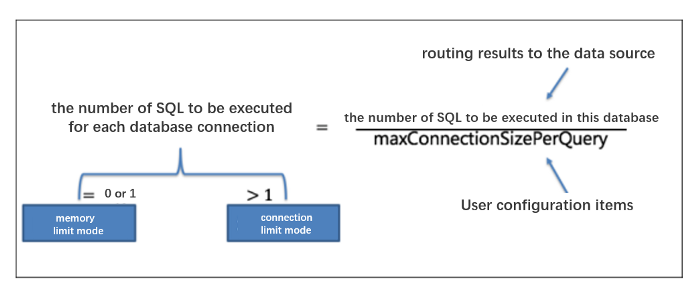
ShardingSphere-JDBC checks the metadata consistency of sub-tables when the service is started. The configuration item max.connections.size.per.quer (maximum number of connections that can be opened per query) is 1 by default. With a large number of tables, the loading process would be slow. You need to refer to the connection pool configuration to improve the loading speed.
2. There is no response when there is no shard key in the sub-table query.

Logical SQL query does not specify shard keys and it queries all the tables according to the whole database tables router in broadcasting routing.
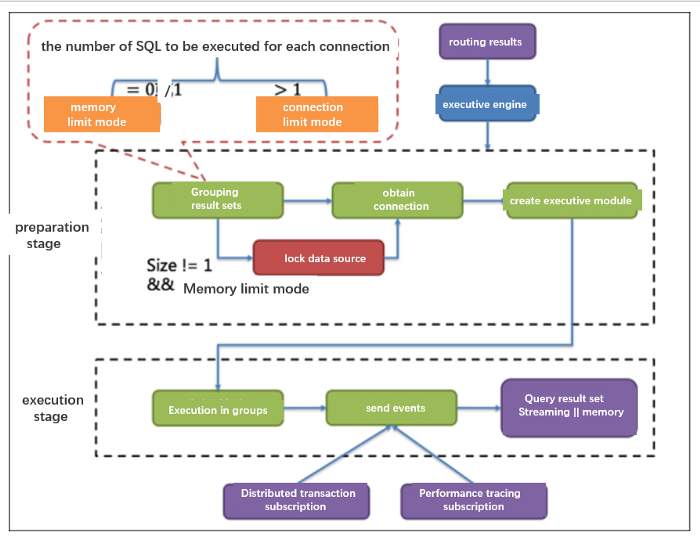
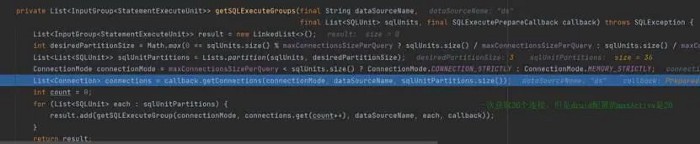
The configuration items have 108 pieces of real tables in a database. According to the configuration of maxConnectionsizeperquery=50, ShardingSphere-JDBC uses the connection limit mode, divides the query requests into three groups, and merges the results with in-memory. As a result, 36 database connections are required for one query. But the maxActive configured by the druid thread pool is set to 20, resulting in a deadlock.
Solutions:
- Combine
check.table.metadata.enabled=true(check the metadata consistency in sub-tables when started)and properly configuremaxConnectionSizePerQuery(maximum number of connections that can be opened by each query). maxConnectionSizePerQueryshould be less than the maximum number of active threads configured by the druid thread pool.
3. After upgrading from 1.X, an error message “Cannot update Sharding key” is displayed in SQL execution, and the actual shard key value is not updated.
To avoid data query failure caused by changing the shard key value, shard key detection is added to the SQL update in the 4.X version. The error can be rectified in the following ways:
- remove the shard key when updating.
- the shard key is added to the
wherestatement synchronously.
4. A start failure is caused when using druid-spring-boot-starter, which is incompatible with Sharding-datasource.
The druid data connection pool starter will load and create a default data source. This will cause conflicts when ShardingSphere-JDBC creates data sources.
5. inline strategy reports an error in range query.
The inline strategy doesn’t support range query by default and the standard strategy is advised. Add the following configuration if the inline strategy is needed for the range query.
spring.shardingsphere.props.allow.range.query.with.inline.sharding: true
Note: Here all the inline strategy range queries will query each sub-table in broadcasting.
6. The “Cannot find owner from table” error is reported.
SQL (simplified):
select id from (select id from x) as a group by a.id
The 4.X version supports limited sub-queries. This problem is caused by the name of the intermediate table. Remove the table alias of select or group order or other fields.
7. The table’s primary key conflicts with the primary key generated by the SNOWFLAKE algorithm.
ShardingSphere provides flexible ways to configure distributed primary key generation strategies. In the sharding rule configuration module, you can configure the primary key generation strategy for each table.
By default, the snowflake algorithm is used to generate long integer data of 64bit. The snowflake generator needs to be configured with:
spring.shardingsphere.sharding.tables.x.key-generator.props.worker.id = ${dcc.node.id}

The company uses the apollo configuration center to deliver the node id of the service instance. The service uses multi-data sources. If you use the YAML file to load sharding configuration, the workId cannot be automatically loaded into sharding configuration items.
Solutions:
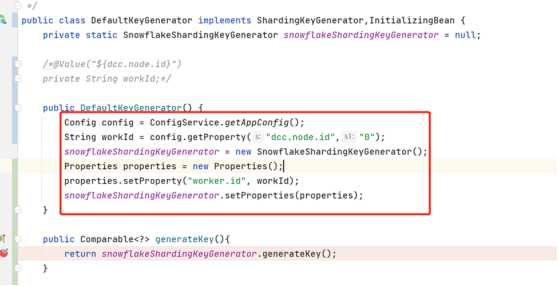
Use the custom generator type based on the built-in SnowflakeShardingKeyGenerator.
If the primary key is used as a shard key, configure max.vibration.offset based on the data sharding value to increase the vibration range.

8. The 3.X version reports an error when CASE WHEN statement is executed.
First, the 3.X and 4.X versions don’t support the case when statement.
The 3.X and 4.X versions have different logics when parsing the shard keys of case when’s update statement. The 4.X parserEngine.parse method will ignore the case when parsing parameters, resulting in inconsistency with the external parameter list and an error when 3.X executes the normal SQL.
The 3.X version works correctly because the first parameter of case when is intentionally set to the shard key when the SQL is written, and the case when statement comes first.
Solutions:
- It is suggested to rewrite SQL as the
case whenis not supported. - According to the shard key parsing logic in version 4.1.1,
case whenis placed at the end, and the shard key remains the first parameter ofcase when.
9. The logical table actualDataNodes is configured and no default value error is reported for the primary key.
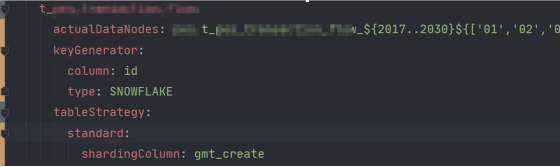

The check.table.metadata.enabled=true is not configured for service, and the metadata consistency of sub-tables is not checked by default.
The first table of actualDataNodes configured by services does not exist, resulting in an empty GenerateKeyContenxt.

Solutions:
- Configure
check.table.metadata.enabled=true. A non-existent table is detected when started and an error is reported. - Rewrite the
actualDataNodes inlineexpression to make sure that the first table exists.
10. In version 3.0, there is a deadlock under the high concurrency of the full database and table router.
ShardingSphere-JDBC uses local transactions by default. In local transactions, the database connection is obtained asynchronously. Under high concurrency, it is possible that all database connections cannot be obtained, resulting in a deadlock.



Conclusion
As a ShardingSphere core user, Energy Monster’s upgrade process also reflects some problems that community users may encounter in the application of ShardingSphere.
Currently, Apache ShardingSphere’s stable version has been updated to 5.1.2 and has been optimized in terms of its functions, performance, testing, documentation, and examples.
You can refer to Apache ShardingSphere’s official website for more information. If you have any questions or suggestions, you are also welcome to give feedback on Github. The community will actively respond and discuss.