How does Apache ShardingSphere implement distributed transactions?
With increasing amounts of data and increasing traffic load, business systems are facing significant challenges, and a strong demand for the scalability of database systems has emerged. Problems in online scaling of traditional standalone databases such as Oracle, MySQL, SQL Server, and PostgreSQL is now more evident than ever. In such cases, the distributed database that can scale out was conceived to solve these scaling challenges. All of this means that distributed transactions are a problem that must be tackled.
In this context, ShardingSphere provides a distributed database computing enhancement engine that can support distributed transactions with an ecosystem that is easily expandable thanks to a plugin oriented architecture.
Transaction processing
Transaction properties Three properties define transactions: atomicity, durability, consistency, and isolation.
Atomicity
In a distributed scenario, the operations of a transaction may be distributed on multiple physical nodes, ensuring that all operations on multiple nodes succeed or fail.
Durability
The operation of a transaction committed is valid even if the power is cut off.
Consistency
Tip: Here “Consistency” is different from the C in CAP theorem. The C in CAP refers to the data consistency between multiple copies, but here it refers to an abstract concept between different levels.
From a user’s persperctive, data transfers from one state to another and both states are confined to a certain degree. For example:
Bank account A has 500$ and account B has 500$, totalling 1,000$. After A and B perform the transfer operation in a transaction, their total amount is still 1,000$.
Isolation
When transactions are executed concurrently, data correctness is ensured. For example, two transactions modify the same data at the same time to ensure that the two transactions are executed in a certain order to keep the data correct.
Challenges Compared to standalone transactions, distributed transactions face the following challenges:
- Atomicity. For standalone transactions, using undo log and redo log guarantees full commit or full roll-back. However, distributed transactions involve multiple physical nodes, each of which is different. Some node logs can be written successfully, while others fail.
- Network instability. Communication is stable for a standalone machine and any operation can be answered whether successful or not. However, in a distributed scenario, the network is unstable, and an operation may not be answered. Thus, how to ensure the availability of distributed transactions (clearing and recovery of abnormal transactions etc.) is a problem.
- Concurrency control. With the advent of MVCC, linearizable operation has become a rigid demand. Globally increasing transaction numbers can easily be done in a standalone database, but not in a distributed scenario.
Solutions Atomic commit
The mainstream solution to atomicity and network instability problems is 2PC (two-phase commit protocol), which defines two roles, that is TM (Transaction Manager) and RM (Resource Manager).
In distributed scenarios, the operations of a transaction can be distributed in multiple nodes. And the transaction includes two phases.
Phase One: RM locks related resources and performs specific operations and then returns success or failure to TM.
Phase Two: according to the results returned by RM in the first phase, TM will execute the final commit operations (transaction state change, lock state deletion, etc.) if all the operations are successful, and roll back if any fails.
Note: There are, of course, some things that need to be optimized, such as converting transactions that do not involve multiple nodes to one-phase commit etc.
Note: The two-phase commit protocol only addresses the commit issue. Either the commit succeeds or fails. There is no intermediate state of partial success.It’s not necessarily related to the transaction isolation level.
Concurrency control
Concurrency control is a strategy ensuring that concurrent transactions are executed at a certain isolation level. Since the advent of Multiversion Concurrency Control (MVCC), mainstream databases have largely abandoned the previous two-phase locking model.
Concurrency control essentially controls the concurrency of data read and write. The concurrency control stratigies determine the isolation level, and concurrency control addresses the following two problems:
- Determining the granularity of concurrency. For example, MySQL has row locks (lock granularity is one row) and table locks (lock granularity is one table) and so on.
- Three concurrency scenarios: a. Read concurrency. No special processing is required because no data changes are involved. b. Write concurrency. Do not write concurrently., otherwise data corruption will occur. c. Read/write concurrency. Performance optimization is mainly completed in this scenario. There are a variety of concurrency control mechanisms, among which Multiversion Concurrency Control is the most popular one.
MVCC Model Two mainstream implementation modes:
-
Based on transaction ID and ReadView The transaction ID is obtained for each transaction to identify the sequence in which the transaction is started. Snapshots are obtained through the active list to store multiple versions of data with the transaction ID, to achieve the effect of concurrency control. MySQL and Postgres-XL both take this approach.
-
Based on timestamp By introducing timestamp, the visibility can be determined by adding timestamp-related attributes to data and comparing commits (commit timestamp) and Snapshot timestamp of data, to achieve the linearized concurrency control. That’s what Spanner did.
The above two modes are dependent on the generation of global transaction numbers. The common generation mechanisms include TrueTime (used by Spanner), HLC (CockroachDB uses HLC with errors), and TSO (Timestamp Oracle).
ShardingSphere’s transaction design
ShardingSphere’s transaction feature is built on the local transaction of the storage DB, providing three transaction modes: LOCAL, XA and BASE. You’d only need to use the native transaction mode (begin/commit/roll-back) to use the three modes and make appropriate trade-offs between consistency and performance.
LOCAL
LOCAL mode is directly built on the local transaction of thestorage DB. It has the highest performance, although there’s a problem with atomicity. If you can tolerate this problem, it’s a good choice.
XA
In XA mode, the XA protocol is based on a set of interaction protocols defined by 2PC. It defines the xa start/prepare/end/commit/rollback interface. The commonly-used implementations have Narayana, Atomics, and ShardingSphere integrate the XA implementation of Narayana and Atomics.
- The app connects to the Proxy, and the Proxy creates a session object bound to the connection.
- The app executes
begin. Proxy creates a logical transaction through Narayana TM, and binds it to the current session. - The app executes specific SQL. Session establishes a connection to storage DB, and connection can be registered to transaction through
Transaction.enlistResource ()interface. Then executeXA START {XID}to start the transaction and execute the SQL overwritten by routing. - The app runs the
commitcommand, executesxa preparefor each connection registered in the transaction database, updates the transaction status toprepared, and performsxa commitfor each connection. If the system returns ok, updates the transaction status toCommitted, and the transaction is committed successfully. If theprepareprocess fails, you can run therollbackcommand to roll back the data. If not, a background process will clear the data. - The app runs the
rollbackcommand, and the connection registered in the transaction that connects the storage DB executesxa rollbackrespectively.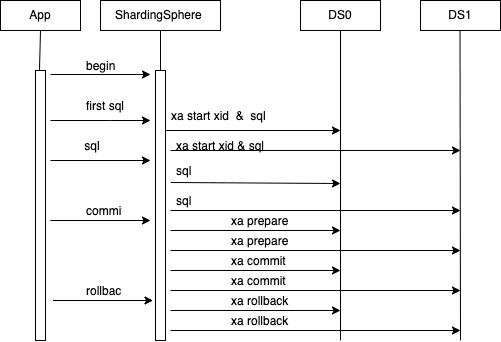
BASE
BASE (Basically Available, Soft State, Eventually Consistent) mode. BASE transaction is the result of balance between C and A in CAP theorem. The AT mode of Seata is an implementation of BASE transaction, and ShardingSphere integrates the AT implementation of Seata.
- The app connects to the Proxy, and the Proxy creates a session object bound to the connection.
- The app executes
begin. Proxy creates a logical transaction through Seata TM, binds it to the current session and registers it with Seata Server. - The app executes logical SQL. Session establishes a connection to the storage DB. Each connection is a
ConnectionProxyinstance of Seata. And then parse theactual sqloverwritten by routing and execute interceptions. For example, if it is a modification operation, executebeginto obtain the local lock, execute anSQLquery, executecommitto release the local lock, and report the branch transaction results to Seata Server. - After the app runs the
commitcommand, the Seata TM in Proxy notifies the Seata Server and directly returns to the app. The Seata Server asynchronously interacts with the Proxy to delete transaction logs. - The app runs the
rollbackcommand. After the Seata TM in the Proxy notifies the Seata Server, the Proxy directly returns to the app. The Seata Server asynchronously interacts with the Proxy, performs compensation operations, and deletes transaction logs.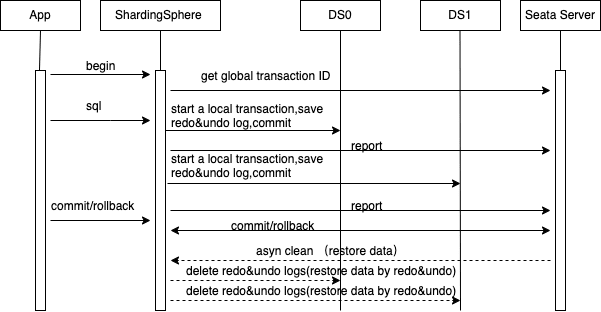
Examples
Installation package preparation Take an XA with good supporting capability integrated with Narayana implementation as an example. Due to the Narayana License issue, it cannot be packaged directly into the installation package, and additional dependencies need to be added.
Download the installation package from the official website, decompress it to the directory ${ShardingSphere} , and add the following jar packages to the directory ${ShardingSphere}/lib.
(Download:https://mvnrepository.com/)
jta-5.12.4.Final.jar
arjuna-5.12.4.Final.jar
common-5.12.4.Final.jar
jboss-connector-api_1.7_spec-1.0.0.Final.jar | ------------------------------------------------------------------------------------------------------------------------------------
jboss-logging-3.2.1.Final.jar | ------------------------------------------------------------------------------------------------------------------------------------
jboss-transaction-api_1.2_spec-1.0.0.Alpha3.jar | ------------------------------------------------------------------------------------------------------------------------------------
jboss-transaction-spi-7.6.0.Final.jar
mysql-connector-java-5.1.47.jar | ------------------------------------------------------------------------------------------------------------------------------------
narayana-jts-integration-5.12.4.Final.jar
shardingsphere-transaction-xa-narayana-5.1.1-SNAPSHOT.jar
MySQL instance preparation Prepare two MySQL instances: 127.0.0.1:3306 and 127.0.0.1:3307. Create user root with password 12345678 for each MySQL instance. Create a test library for each MySQL instance.
ShardingSphere-Proxy configuration
Modify the transaction configuration of server.yaml
rules:
- !AUTHORITY
users:
- root@%:root
- sharding@:sharding
provider:
type: ALL_PRIVILEGES_PERMITTED
- !TRANSACTION
defaultType: XA
providerType: Narayana
Modify conf/conf-sharding.yaml
dataSources:
ds_0:
url: jdbc:mysql://127.0.0.1:3306/test?serverTimezone=UTC&allowPublicKeyRetrieval=true&useSSL=false
username: root
password: 12345678
connectionTimeoutMilliseconds: 30000
idleTimeoutMilliseconds: 60000
maxLifetimeMilliseconds: 1800000
maxPoolSize: 50
minPoolSize: 1
ds_1:
url: jdbc:mysql://127.0.0.1:3307/test?serverTimezone=UTC&allowPublicKeyRetrieval=true&useSSL=false
username: root
password: 12345678
connectionTimeoutMilliseconds: 30000
idleTimeoutMilliseconds: 60000
maxLifetimeMilliseconds: 1800000
maxPoolSize: 50
minPoolSize: 1
rules:
- !SHARDING
tables:
account:
actualDataNodes: ds_${0..1}.account${0..1}
tableStrategy:
standard:
shardingColumn: id
shardingAlgorithmName: account_inline
keyGenerateStrategy:
column: id
keyGeneratorName: snowflake
defaultDatabaseStrategy:
standard:
shardingColumn: id
shardingAlgorithmName: database_inline
defaultTableStrategy:
none:
shardingAlgorithms:
database_inline:
type: INLINE
props:
algorithm-expression: ds_${id % 2}
account_inline:
type: INLINE
props:
algorithm-expression: account${id % 2}
keyGenerators:
snowflake:
type: SNOWFLAKE
props:
worker-id: 123
Start ShardingSphere-Proxy Start the Proxy by running the following command:
cd ${ShardingSphere}
./bin/start.sh
Use ShardingSphere-Proxy Use MySQL Client to connect shardingSphere-Proxy for testing, refer to the following command.
mysql -h127.0.0.1 -P3307 -uroot -proot
mysql> use sharding_db;
Database changed
mysql> create table account(id int, balance float ,transaction_id int);
Query OK, 0 rows affected (0.12 sec)
mysql> select * from account;
Empty set (0.02 sec)
mysql> begin;
Query OK, 0 rows affected (0.09 sec)
mysql> insert into account(id, balance, transaction_id) values(1,1,1),(2,2,2);
Query OK, 2 rows affected (0.53 sec)
mysql> select * from account;
+------+---------+----------------+
| id | balance | transaction_id |
+------+---------+----------------+
| 2 | 2.0 | 2 |
| 1 | 1.0 | 1 |
+------+---------+----------------+
2 rows in set (0.03 sec)
mysql> commit;
Query OK, 0 rows affected (0.05 sec)
mysql> select * from account;
+------+---------+----------------+
| id | balance | transaction_id |
+------+---------+----------------+
| 2 | 2.0 | 2 |
| 1 | 1.0 | 1 |
+------+---------+----------------+
2 rows in set (0.02 sec)
Future plan
Currently, ShardingSphere’s distributed transaction integrates the 2PC implementation scheme of the 3rd party to guarantee atomicity. Isolation depends on the isolation guarantee of the storage DB, providing available transaction functions.
The future implementation of MVCC based on global Timestamp and combined with 2PC, will provide better support for transaction isolation semantics.
Apache ShardingSphere Project Links: ShardingSphere Github
Author
Lu Jingshang
Apache ShardingSphere Committer & Infrastructure R&D Engineer at SphereEx. Enthusiastic about open source and database technology. Focus on developing Apache ShardingSphere transaction module.