Apache ShardingSphere Enterprise Applications: Zhuanzhuan’s Transaction System with 100s of Millions of Records
Background and Challenges
Zhuanzhuan is an internet platform that allows it users to sell their second-hand stuff — sort of an eBay of the East. Its business had been booming, and with it the ordering system started to face increasing performances challenges. The order database is the cornerstone of the system, and its performance should not be underestimated.
Challenges:
- During promotions and special discount periods the burden on databases is heaby with tens of thousands of single database queries per second (qps) taking up huge database resources, and causing a significant reduction in write performance.
- Increased data pressure, with a single database containing several large tables with hundreds of millions of data, which challenges the capacity limit of the server.
- Overwhelming data volume, and data backup and recovery take a long time, posing high risks of data loss in extreme cases.
Why ShardingSphere?
In the beginning, ZhuanZhuan’s team took adjustment measures to ease the database pressure. Exmaples include:
- Optimized major transactions, reduced transactions, and even eliminated transactions
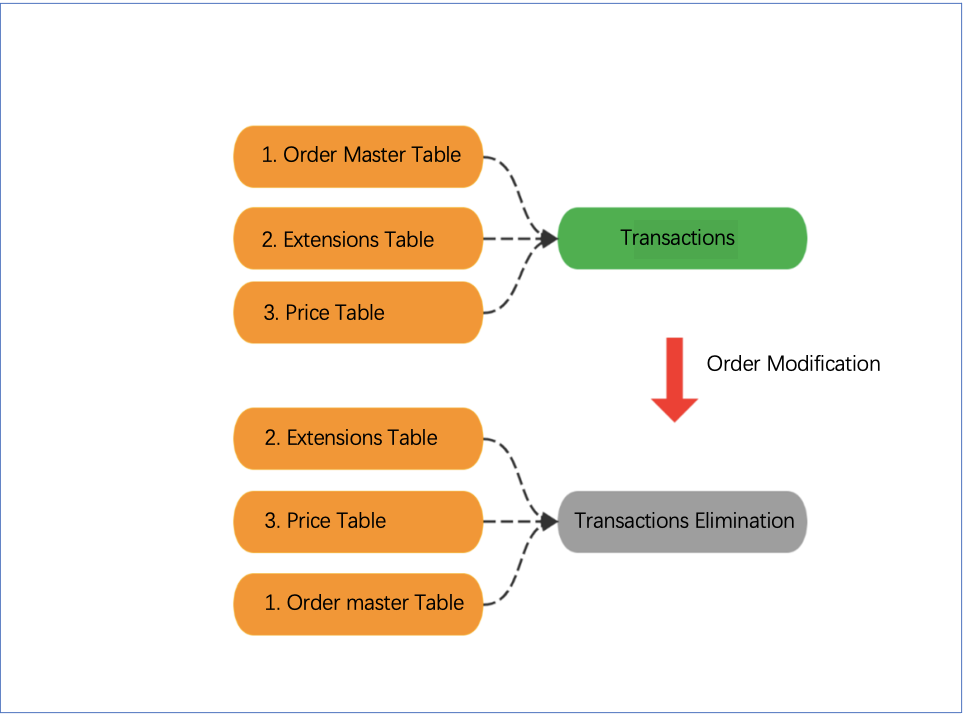
We adjusted the original transaction order by putting table generation, the core step at the end, and keeping the transaction only in the order primary database. When the operation of the main table was abnormal, dirty reads were allowed on other order-related tables.
- Order data cache

Data consistency was the trickiest part of the cache. As order data involved account settlements and commission, non-real-time and inconsistent data would cause serious accidents.
Strictly keeping cache data consistency would complex coding and reduce system concurrency. Therefore, we made some compromises on cache plans:
- Allowing direct query when cache failed.
- Adding version serial number, and querying the latest version’s data to ensure real-time data.
- Complex queries were conducted by Elasticsearch (ES) and primary and secondary separation, and for some large tables, we adopted hot and cold data separation.

Through these optimizations, database pressure was eased. However, it still seemed overwhelming under high concurrency scenarios, such as discount season.
To fundamentally solve the performance problem of order database, ZhuanZhuan decided to adopt data sharding (database and table splitting) on the order database so that we wouldn’t have to worry about order capacity in the future 3–5 years.
Zhuangzhuang chose ShardingSphere after comparing the efficiency, stability, learning cost and etc. of different data sharding components.
Advantages of ShardingSphere:
- It provides standardized data sharding, distributed transactions and database governance, and it’s applicable in a variety of situations such as Java isomorphism, heterogeneous language and cloud native.
- It has flexible sharding strategies, supporting multiple sharding methods.
- It’s easy to integrate with other components and has a low level of transaction intrusions.
- It has extensive documentation and an active community.
ShardingSphere initiated the Database Plus concept and adopts a plugin oriented architecture where all modules are independent of each other, allowing each to be used individually or flexibly combined.
It consists of three products, namely JDBC, Proxy and Sidecar (Planning), which supports both independent and hybrid deployment.
Below is a feature comparison of the three products:

By comparison, and considering the high order concurrency, we chose ShardingSphere-JDBC as our data sharding middleware.
ShardingSphere-JDBC is a lightweight Java framework, proving extra service at the JDBC layer. It directly connects to the database by the client-side, provides services by Jar package, and requires no extra deployment and reliance. It can be seen as an enhanced JDBC driver, fully compatible with JDBC and other Object-Relational Mapping(ORM) frameworks.

Key Points in Project Implementation
- Sharding Key
The current order ID is generated by timestamp+user identification code+machine code+incremental sequence. The user identification code is taken from bits 9 to 16 of the buyer ID, a true random number when the user ID is generated, and is thus suitable as a sharding key.
Choosing user identification code as the sharding key has some advantages:
- The data can be distributed as evenly as possible to each database and table.
- Specific sharding locations can be quickly located either by order ID or user ID.
- Data of the same buyer can be distributed to the same databases and tables, facilitating the integrated query of the buyer information.

The sharding strategy: we adopt 16 databases and 16 tables. User identification codes are used to split databases, and higher 4 bits are used to split tables.
- Data Migration between Old and New Databases The migration must be online, and downtime migration cannot be accepted, as there will be new data writes during the migration process.
The data should be intact, and the migration process should be insensible to the client-side. After the migration, data in the new database should be consistent with the ones in the old databases.
The migration should allow rollback, so that when a problem occurs during the migration process, it should be able to roll back to the source database without impacting system availability.
Data migration steps are as follows: dual writes-> migrate historical data-> verify-> old database offline.
Effects and Benefits
- It solves the problem of single database capacity limit.
- The data volume of a single database and table is greatly reduced after sharding. The data volume of a single table is reduced from nearly a hundred million level to several millions level, which greatly improves the overall performance.
- It reduces the risk of data losses due to oversized single databases and tables in extreme cases and eases the pressure of operation and maintenance. The following is a comparison of the number of interface calls of the order placement service and the time consumed by the interface during two promotion and discount periods:
Promotion before adopting ShardingSphere

Promotion after adopting ShardingSphere

Summary
ShardingSphere simplifies the development of data sharding with its well-designed architecture, highly flexible, pluggable and scalable capabilities, allowing R&D teams to focus only on the business itself, thus enabling flexible scaling of the data architecture.
Apache ShardingSphere Project Links: