A Practical Guide to Apache ShardingSphere’s HINT
Background
Apache ShardingSphere has gradually introduced various features based on practical user requirements, such as data sharding and read/write splitting.
The data sharding feature contains many practical sharding strategies such as Standard Sharding Strategy and Complex Sharding Strategy, and users can easily configure the corresponding sharding algorithms.
When it comes to Read/Write Splitting, Apache ShardingSphere provides users with two types called Static and Dynamic, and abundant load balancing algorithms.
Sharding and Read/Write Splitting functions of ShardingSphere are already very useful, but scenarios are ever-changing.
Take a multi-tenant case as an example: a user expects to shard data according to the tenant to which the login account belongs, but the tenant information does not exist in every business SQL. In this case, the algorithm for extracting sharding fields from SQL is not feasible.
Additionally, in most read/write splitting scenarios, users want to route queries to the secondary database for execution, but in some scenarios with a requirement for real-time operations, users want to route SQL to the primary database for execution. Currently, read/write splitting cannot meet business requirements.
Considering the above-mentioned pain points, Apache ShardingSphere created the Hint function to allow users to utilize different logic rather than SQL to implement forced routing or sharding.
Currently, ShardingSphere provides users with two Hint methods. One is a manual programming method with Java API and uses HintManager for forced routing and sharding. This method is very friendly to applications programmed with JDBC because developers don’t need to write too much code and can easily implement SQL-independent sharding or forced routing functions.
Based on distributed SQL (DistSQL, ShardingSphere designed SQL HINT and DistSQL HINT to provide users with sharding and forced routing functions that can be implemented without coding. The method is more friendly to database administrators (DBAs).
Next, let’s take a close look at the two methods.
Manual Programming Based on HintManager
ShardingSphere can implement the functions of forced route and sharding via the HintManager objects. With HintManager, users can complete data sharding without SQL. It also allows users to shard data or force routing more flexibly, greatly expanding user scenarios.
At the moment, with the help of HintManager, users can utilize ShardingSphere’s built-in or custom Hint algorithms to implement the sharding function, and can set specified data source or force primary database to do read/write splitting to implement the forced routing function.
I’d like to explain its basic implementation principle first to help you gain a better understanding of HintManager.
- The Implementation of HintManager
The code snippet below can help you quickly understand the principle of
HintManager.
@NoArgsConstructor(access = AccessLevel.PRIVATE)
public final class HintManager implements AutoCloseable {
private static final ThreadLocal<HintManager> HINT_MANAGER_HOLDER = new ThreadLocal<>();
}
As shown above, ShardingSphere implements the function of HintManager with ThreadLocal: as long as they are in the same thread, user’s sharding settings are preserved. Therefore, the user only needs to call relevant HintManager functions before executing SQL statements, and then ShardingSphere can obtain the sharding or mandatory routing conditions set by the user in the current thread so as to perform sharding or routing operations.
Next, let’s learn how to use it.
- How to Use HitManager
- Use
HINTfor Sharding To use theHint Sharding Algorithm, users are required to implement the interfaceorg.apache.shardingsphere.sharding.api.sharding.hint.HintShardingAlgorithm. When Apache ShardingSphere performs routing, it will obtain shard values fromHintManagerfor routing operations.
The configuration is as follows:
rules:
- !SHARDING
tables:
t_order:
actualDataNodes: demo_ds_${0..1}.t_order_${0..1}
databaseStrategy:
hint:
algorithmClassName: xxx.xxx.xxx.HintXXXAlgorithm
tableStrategy:
hint:
algorithmClassName: xxx.xxx.xxx.HintXXXAlgorithm
defaultTableStrategy:
none:
defaultKeyGenerateStrategy:
type: SNOWFLAKE
column: order_id
props:
sql-show: true
Get the HintManager instance:
HintManager hintManager = HintManager.getInstance();
Add shard key:
- Use
hintManager.addDatabaseShardingValueto add data source shard key hintManager.addTableShardingValueis used to add table shard key
Note: In the case of database sharding without table sharding, when using HINT to force routing to a database shard, you can use hintManager.setDatabaseShardingValue to add Shard.
Delete shard key:
Shard Key is stored in ThreadLocal so you need to call hintManager.close() at the end of the operation to clear the content in ThreadLocal
The complete code snippet example is as follows:
String sql = "SELECT * FROM t_order";
try (HintManager hintManager = HintManager.getInstance();
Connection conn = dataSource.getConnection();
PreparedStatement preparedStatement = conn.prepareStatement(sql)) {
hintManager.addDatabaseShardingValue("t_order", 1);
hintManager.addTableShardingValue("t_order", 2);
try (ResultSet rs = preparedStatement.executeQuery()) {
while (rs.next()) {
// ...
}
}
}
String sql = "SELECT * FROM t_order";
try (HintManager hintManager = HintManager.getInstance();
Connection conn = dataSource.getConnection();
PreparedStatement preparedStatement = conn.prepareStatement(sql)) {
hintManager.setDatabaseShardingValue(3);
try (ResultSet rs = preparedStatement.executeQuery()) {
while (rs.next()) {
// ...
}
}
}
- Use
HINTtoForce Primary Database Route
Obtain HintManager
It is the same as HINT-based Data Sharding described above.
Set Primary Database Route
Use hintManager.setWriteRouteOnly to complete setting.
Clear Shard Key Value
It is the same as HINT-based Data Sharding described above.
The complete code snippet example is as follows:
String sql = "SELECT * FROM t_order";
try (HintManager hintManager = HintManager.getInstance();
Connection conn = dataSource.getConnection();
PreparedStatement preparedStatement = conn.prepareStatement(sql)) {
hintManager.setWriteRouteOnly();
try (ResultSet rs = preparedStatement.executeQuery()) {
while (rs.next()) {
// ...
}
}
}
- Use
HINTto Implement Route to Specified Database
Obtain HintManager
It is the same as HINT-based Data Sharding described above.
Set Route to Specified Database
Use hintManager.setWriteRouteOnly to set database name.
The complete code snippet example is as follows:
String sql = "SELECT * FROM t_order";
try (HintManager hintManager = HintManager.getInstance();
Connection conn = dataSource.getConnection();
PreparedStatement preparedStatement = conn.prepareStatement(sql)) {
hintManager.setDataSourceName("ds_0");
try (ResultSet rs = preparedStatement.executeQuery()) {
while (rs.next()) {
// ...
}
}
}
Delete Forced Route Value
It is the same as HINT-based Data Sharding described above.
After understanding the manual programming method based on HintManager, let’s take a look at another HINT solution provided by ShardingSphere based on distributed SQL.
DistSQL Based HINT
DistSQL HINT provided by Apache ShardingSphere is composed of two functions: one is called SQL HINT that is based on SQL annotations, and the other is the function that acts on HintManager through DistSQL implementation.
SQL HINT
SQL HINT is a HINT method to implement forced routing by adding annotations to SQL statements, reducing the cost of code modification for users. This means that it is not subjected to the limitations of Java API, and is available in both ShardingSphere-JDBC and ShardingSphere-Proxy.
Take the following SQL statement as an example. Even if the user configures the relevant sharding algorithm for t_order, the SQL statement will be directly executed on the database ds_0 and the execution result will be returned.
/* ShardingSphere hint: dataSourceName=ds_0 */
SELECT * FROM t_order;
By means of annotations, we can easily send the SQL statement directly to the specified database for execution with no need for considering other sharding logic.
Taking the multi-tenant scenario as an example. Users do not need to configure complex database sharding logic or modify business logic any more, but only need to add the specified database to the annotation.
Next, I’d like to explain the implementation principle of SQL HINT.
- The Implementation of SQL HINT
If you’ve heard of Apache ShardingSphere before, you must be familiar with its SQL Parser engine. The first step to implementing SQL HINT is to extract SQL annotations.
With Access Channel in ANTLR4, SQL annotation can be sent to a specific hidden channel separately. ShardingSphere also uses this function to extract annotations in the hidden channel while generating the parsing result.
The specific implementation is shown in the following code snippet:
- Feed SQL comments into the hidden channel:
lexer grammar Comments;
import Symbol;
BLOCK_COMMENT: '/*' .*? '*/' -> channel(HIDDEN);
INLINE_COMMENT: (('-- ' | '#') ~[\r\n]* ('\r'? '\n' | EOF) | '--' ('\r'? '\n' | EOF)) -> channel(HIDDEN);
- Access the syntax tree and add the extraction of the annotation
public <T> T visit(final ParseContext parseContext) {
ParseTreeVisitor<T> visitor = SQLVisitorFactory.newInstance(databaseType, visitorType, SQLVisitorRule.valueOf(parseContext.getParseTree().getClass()), props);
T result = parseContext.getParseTree().accept(visitor);
appendSQLComments(parseContext, result);
return result;
}
private <T> void appendSQLComments(final ParseContext parseContext, final T visitResult) {
if (!parseContext.getHiddenTokens().isEmpty() && visitResult instanceof AbstractSQLStatement) {
Collection<CommentSegment> commentSegments = parseContext.getHiddenTokens().stream().map(each -> new CommentSegment(each.getText(), each.getStartIndex(), each.getStopIndex()))
.collect(Collectors.toList());
((AbstractSQLStatement) visitResult).getCommentSegments().addAll(commentSegments);
}
}
After extracting the SQL annotation information, we need to perform related mandatory routing based on the information. For routing, it is normal to use Apache ShardingSphere’s Router engine.
We have made some modifications for HINT on the Router engine.
public RouteContext route(final LogicSQL logicSQL, final ShardingSphereMetaData metaData) {
RouteContext result = new RouteContext();
Optional<String> dataSourceName = findDataSourceByHint(logicSQL.getSqlStatementContext(), metaData.getResource().getDataSources());
if (dataSourceName.isPresent()) {
result.getRouteUnits().add(new RouteUnit(new RouteMapper(dataSourceName.get(), dataSourceName.get()), Collections.emptyList()));
return result;
}
for (Entry<ShardingSphereRule, SQLRouter> entry : routers.entrySet()) {
if (result.getRouteUnits().isEmpty()) {
result = entry.getValue().createRouteContext(logicSQL, metaData, entry.getKey(), props);
} else {
entry.getValue().decorateRouteContext(result, logicSQL, metaData, entry.getKey(), props);
}
}
if (result.getRouteUnits().isEmpty() && 1 == metaData.getResource().getDataSources().size()) {
String singleDataSourceName = metaData.getResource().getDataSources().keySet().iterator().next();
result.getRouteUnits().add(new RouteUnit(new RouteMapper(singleDataSourceName, singleDataSourceName), Collections.emptyList()));
}
return result;
}
ShardingSphere first finds SQL annotations that meet the definition, and after verification, it will directly return the routing result specified by the user, thus implementing the forced routing function.
Next, I’d like to showcase how to use SQL HINT.
- How to Use SQL HINT
SQL HINTis easy to use with ShardingSphere-JDBC and ShardingSphere-Proxy.
Step 1: Add SQL comments. Currently SQL HINT supports specifying data source routing and primary database routing.
- Data source-specified Routing: currently only supports routing to one data source. The comment format only supports
/* */for the time being and starts withShardingSphere hint: with the attribute namedataSourceName.
/* ShardingSphere hint: dataSourceName=ds_0 */
SELECT * FROM t_order;
- Primary Database Routing: The comment format only supports /* */ for the time being. The content needs to start
ShardingSphere hint: and the attribute name iswriteRouteOnly.
/* ShardingSphere hint: writeRouteOnly=true */
SELECT * FROM t_order;
DistSQL HINT
DistSQL also provides HINT functions, enabling users to implement sharding and forced routing through ShardingSphere-Proxy.
- The Implementation Principle of DistSQL HINT
Let’s take a look at the implementation principle of DistSQL Hint first.
The implementation principle of DistSQL HINT is very simple: it is the HINT function implemented by operating HintManager.
Taking the read/write splitting HINT as an example. When a user executes the following SQL with ShardingSphere-Proxy, ShardingSphere actually performs the operations (as shown below) to the SQL statement:
- Forced Primary Database Read-write
set readwrite_splitting hint source = write
@RequiredArgsConstructor
public final class SetReadwriteSplittingHintExecutor extends AbstractHintUpdateExecutor<SetReadwriteSplittingHintStatement> {
private final SetReadwriteSplittingHintStatement sqlStatement;
@Override
public ResponseHeader execute() {
HintSourceType sourceType = HintSourceType.typeOf(sqlStatement.getSource());
switch (sourceType) {
case AUTO:
HintManagerHolder.get().setReadwriteSplittingAuto();
break;
case WRITE:
HintManagerHolder.get().setWriteRouteOnly();
break;
default:
break;
}
return new UpdateResponseHeader(new EmptyStatement());
}
}
@NoArgsConstructor(access = AccessLevel.PRIVATE)
public final class HintManagerHolder {
private static final ThreadLocal<HintManager> HINT_MANAGER_HOLDER = new ThreadLocal<>();
/**
* Get an instance for {@code HintManager} from {@code ThreadLocal},if not exist,then create new one.
*
* @return hint manager
*/
public static HintManager get() {
if (null == HINT_MANAGER_HOLDER.get()) {
HINT_MANAGER_HOLDER.set(HintManager.getInstance());
}
return HINT_MANAGER_HOLDER.get();
}
/**
* remove {@code HintManager} from {@code ThreadLocal}.
*/
public static void remove() {
HINT_MANAGER_HOLDER.remove();
}
}
After the user executes the SQL statement, the DistSQL parser engine will first identify that the SQL statement is with read/write splitting Hint, and will extract the fields that the user wants to automatically route or force to the write database.
After that, it will use SetReadwriteSplittingHintExecutor to execute the SQL statement, so as to set the correct operation in HintManager, implementing the function of forced primary database routing.
- How to Use DistSQL HINT
Below are the relevant statements of DistSQL HINT.
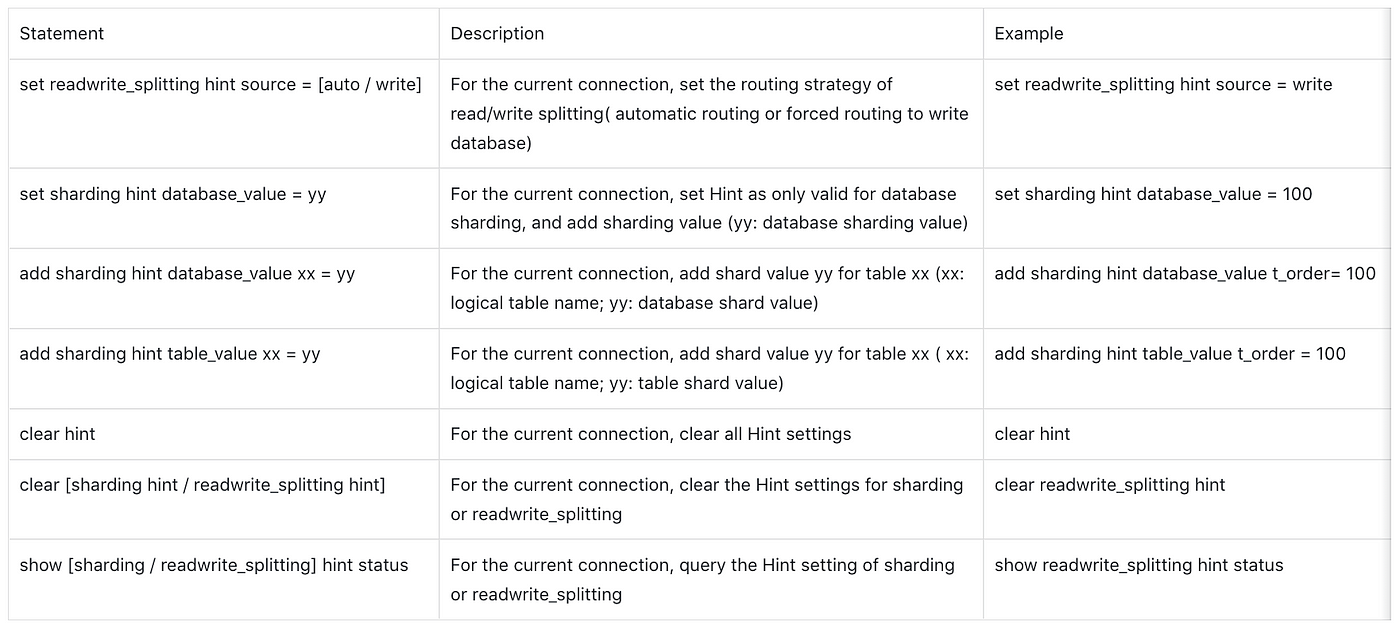
This blog introduced the two methods and basic principles of HINT in detail. Once you develop a basic understanding of HINT, you’ll be able to better select the most appropriate method.
Apache ShardingSphere Project Links:
Author
Chuxin CHEN
SphereEx Middleware Engineer & Apache ShardingSphere Committer
Currently, Chen mainly develops the kernel module of Apache ShardingSphere.