面对日益增加的系统访问量,数据库的吞吐量面临着巨大瓶颈。 对于同一时刻有大量并发读操作和较少写操作类型的应用系统来说,将数据库拆分为主库和从库,主库负责处理事务性的增删改操作,从库负责处理查询操作,能够有效的避免由数据更新导致的行锁,使得整个系统的查询性能得到极大的改善。
通过一主多从的配置方式,可以将查询请求均匀的分散到多个数据副本,能够进一步的提升系统的处理能力。 使用多主多从的方式,不但能够提升系统的吞吐量,还能够提升系统的可用性,可以达到在任何一个数据库宕机,甚至磁盘物理损坏的情况下仍然不影响系统的正常运行。
与将数据根据分片键打散至各个数据节点的水平分片不同,读写分离则是根据 SQL 语义的分析,将读操作和写操作分别路由至主库与从库。
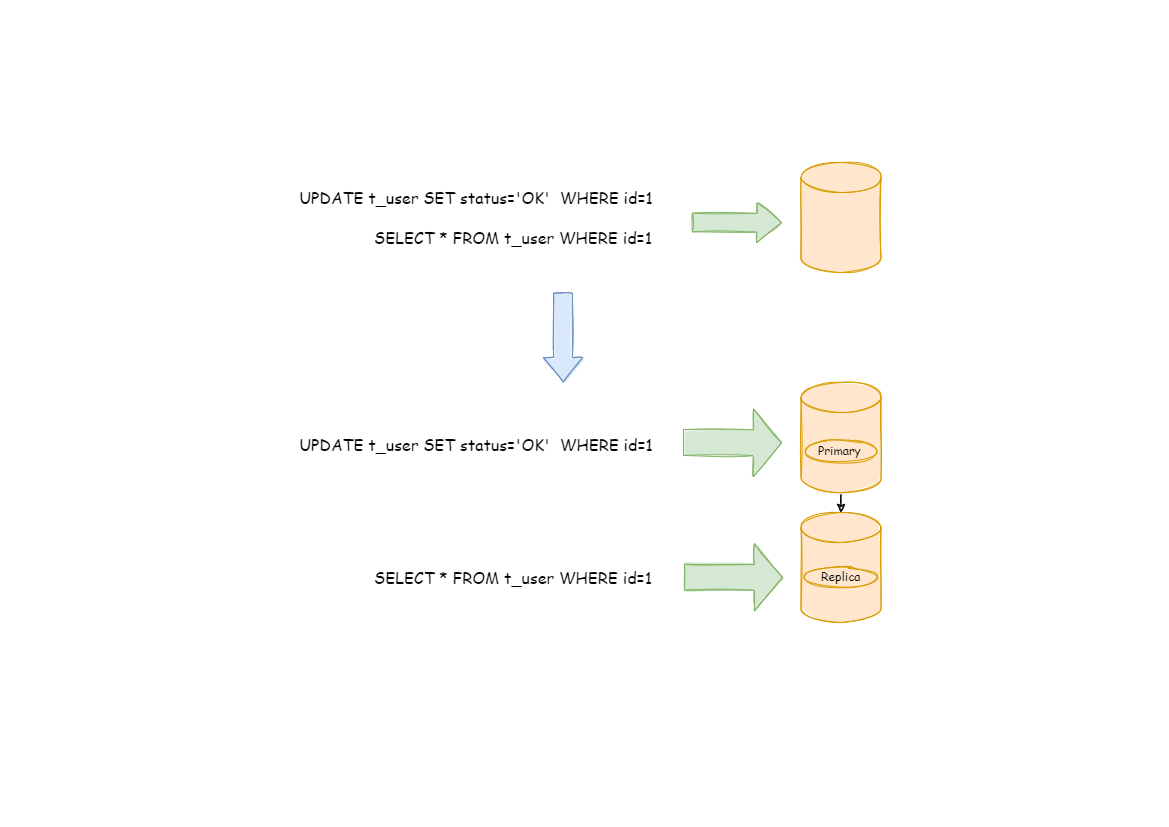
读写分离的数据节点中的数据内容是一致的,而水平分片的每个数据节点的数据内容却并不相同。将水平分片和读写分离联合使用,能够更加有效的提升系统性能。
读写分离虽然可以提升系统的吞吐量和可用性,但同时也带来了数据不一致的问题。 这包括多个主库之间的数据一致性,以及主库与从库之间的数据一致性的问题。 并且,读写分离也带来了与数据分片同样的问题,它同样会使得应用开发和运维人员对数据库的操作和运维变得更加复杂。 下图展现了将数据分片与读写分离一同使用时,应用程序与数据库集群之间的复杂拓扑关系。
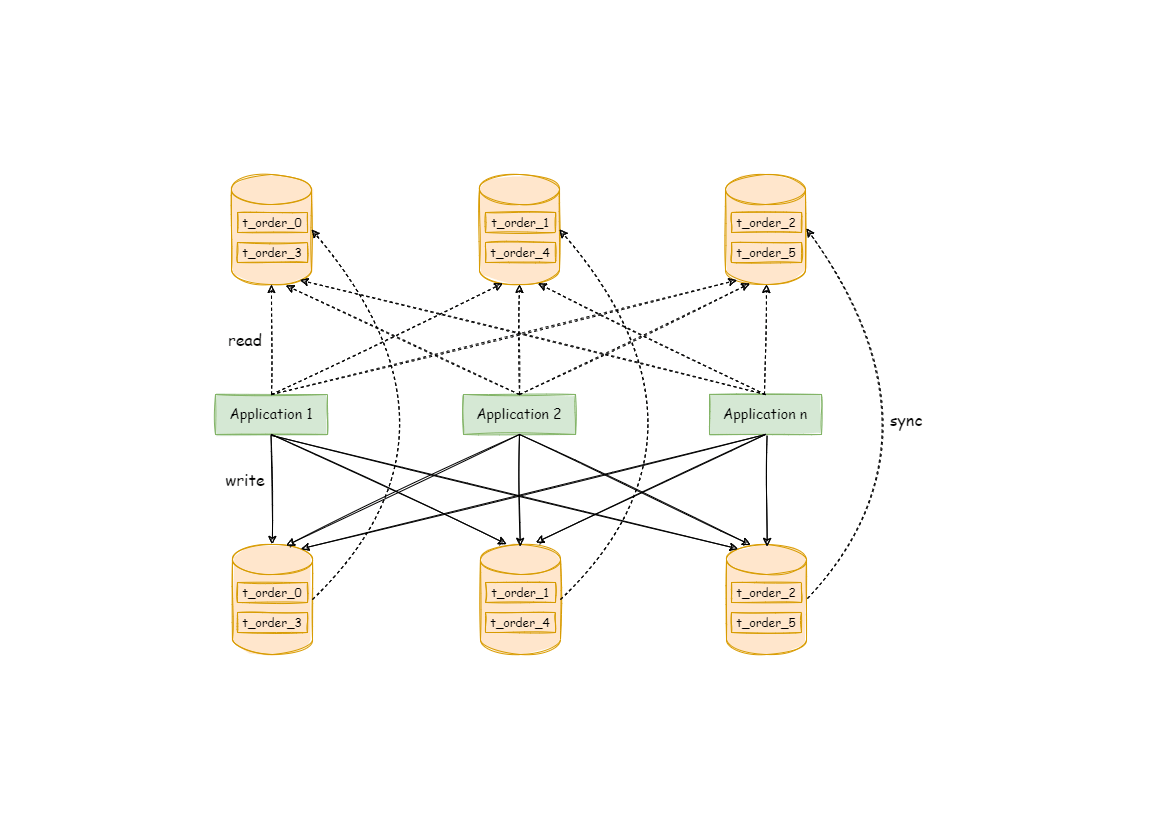
透明化读写分离所带来的影响,让使用方尽量像使用一个数据库一样使用主从数据库集群,是 Apache ShardingSphere 读写分离模块的主要设计目标。
许多系统通过采用主从数据库架构的配置来提高整个系统的吞吐量,但是主从的配置也给业务的使用带来了一定的复杂性。接入 ShardingSphere,可以利用读写分离功能管理主从数据库,实现透明化的读写分离功能,让用户像使用一个数据库一样使用主从架构的数据库。