Revealing Sharding-Proxy —— Database Middleware Oriented DBA
Lecturer introduction
Yonglun Zhang: Senior software engineer of operation and maintenance department at JD Finance
He has been working on software development for years engaged in traditional Industry. Afterwards he was involved in Internet and started his web crawler career at JD Finance, sigh at the huge amount of Internet data since then. It’s great honor to join ShardingSphere this year and be able to do what he is interested in, he hopes to improve himself and contribute to the community.
Hello everyone, I’m so glad to show you Sharding-Proxy, which is the second product of ShardingSphere.
It was first released with ShardingSphere 3.0.0.M1 last month. I hope you can have visualize of overall view for Sharding-Proxy through several optimizing practices. With regard to topics of MySQL protocol, IO, Netty, etc. I’ll share related themes next time.
01 Sharding-Proxy Introduction
1. Sharding-Proxy Overview
ShardingSphere-Proxy defines itself as a transparent database proxy, providing a database server that encapsulates database binary protocol to support heterogeneous languages. Friendlier to DBA, the MySQL version provided now can use any kind of terminal (such as MySQL Command Client, MySQL Workbench, etc.) that is compatible of MySQL protocol to operate data.
-
Totally transparent to applications, it can be used directly as MySQL.
-
Applicable to any kind of terminal that is compatible with MySQL and PostgreSQL protocol.
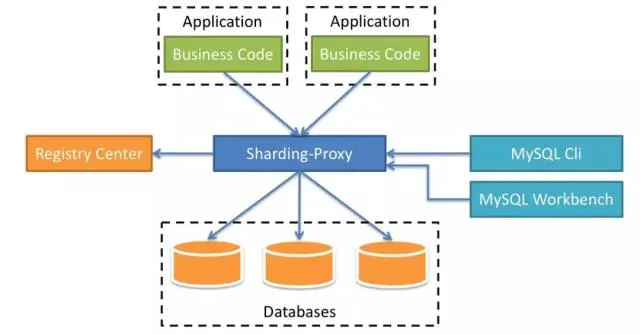
Comparison with Sharding-JDBC & Sharding-Sidecar:

They can work individually and cooperate each other, which achieve same purpose through different architecture and point of penetration. Its core functions based on same implementation, such as data sharding, replica query and base transaction.
For instance, Sharding-JDBC highly supports many kinds of ORM framework for Java development technology stack scenarios. It’s quite convenient to import data sharding ability to your system. DBA retrieves and manages data by deploying a Sharding-Proxy instance.
2. Sharding-Proxy Architecture
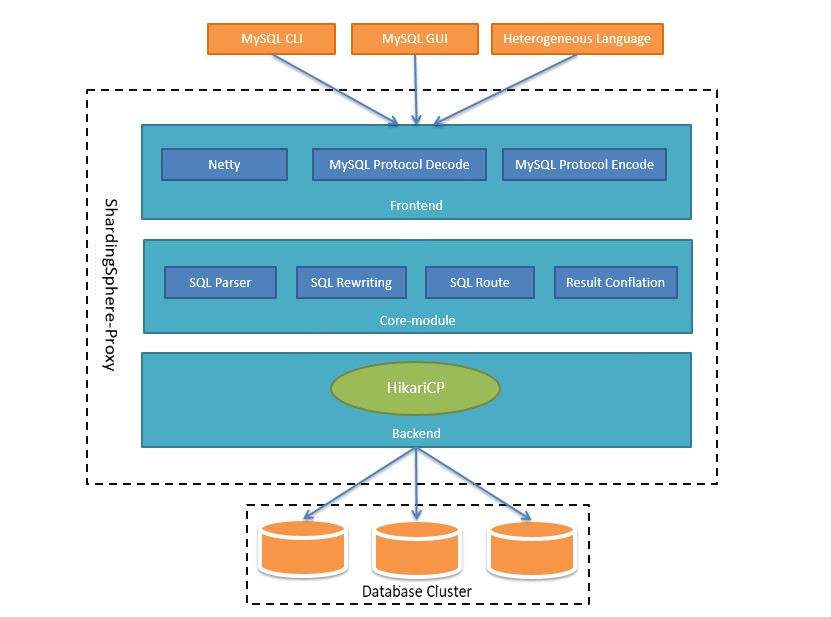
The whole architecture can be divided into three components: Frontend, Core-module and Backend:
-
Frontend: It’s responsible for communication with client, based on NIO client/server framework. It adopts to NIO on Windows and Mac, adaptive to Epoll automatically on Linux, and completes to the encoding/decoding of MySQL protocol in the process of communication.
-
Core-module: After getting decoded command of MySQL, it starts to parse/rewrite/route/conflate SQL through Sharding-Core.
-
Backend: it’s interacted with real database by Hikari pool of BIO. Its performance declines on condition of one primary more replicas or large scale to database cluster in the way of BIO, so we will provide way of NIO to connect real database in the future.
The throughput of proxy will be greatly improved, which can effectively cope with large-scale database cluster in this way.
02 PreparedStatement Achievement
1. PreparedStatement Achievement
My first assignment at Sharding-Sphere is to achieve PreparedStatement of Proxy. It’s said to be a flawless functionality that is precompile SQL to improve query speed and prevent SQL injection attacks. It sounds great that one precompiled and more queries reduces SQL compilation cost and lifts efficiency, but it turns out to be very slow to execute SQL, even it is slower than the original statement.
Neglect Proxy, let’s see how MySQL protocol works when running PreparedStatement by wireshark.
Code sample as below:
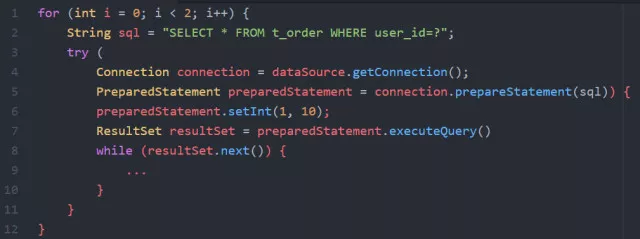
It’s clear that perform query twice by PreparedStatement and set parameter user_id=10 each time. Through analysis of caught packets, protocol messages between JDBC and MySQL are as follows:
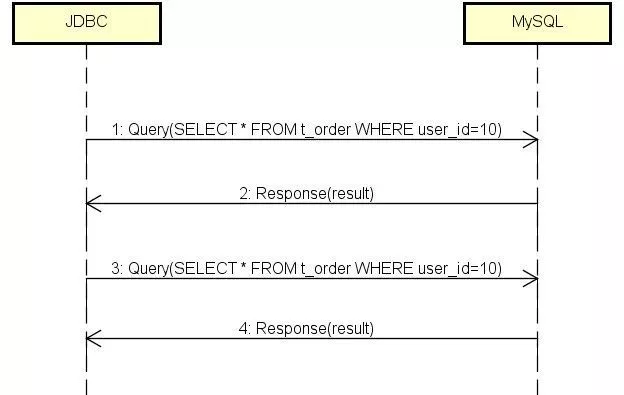
JDBC executes query two times towards MySQL and MySQL returns results with the same times. We don’t expect first message for PreparedStatement because of no question mark. It implies no effect to prepare, doesn’t work for MySQL at least.
For the issue I think everyone makes sense without setting useServerPrepStmts=true to JDBC url. MySQL do prepare through the parameter. It’s pointless if you don’t set it although JDBC wants to perform preparation, because it is insensible to MySQL. Let’s set the parameter in the url next:
jdbc:mysql://127.0.0.1:3306/demo_ds?useServerPrepStmts=true
Here is the new interaction:
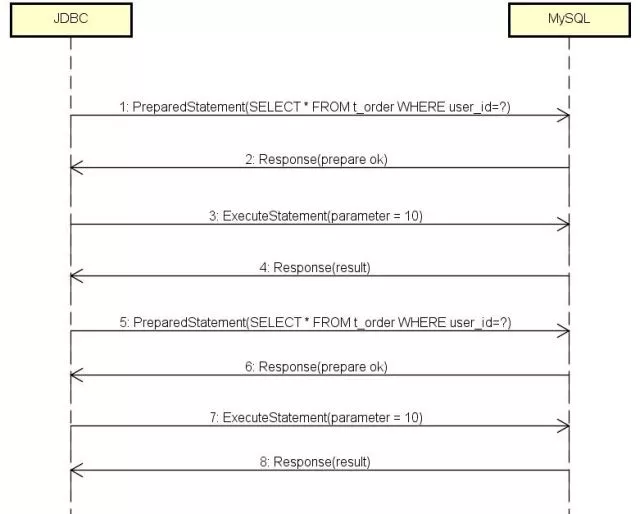
It’s a correct procedure at the first sight: for the first message, it’s PreparedStatement which has question mark within SELECT; for the second message, MySQL points out to get ready for JDBC; for the third message, JDBC sets user_id=10; for the fourth message, MySQL returns query result; for the fifth message, why does JDBC send PreparedStatement once more?
Each query should transfer its value of parameter through ExecuteStatement in expectation, then it takes effect of one precompiled and more preformation.
If “precompiled” every time, there is no difference with normal query in addition to cost of two passing message: Response(prepareok) and ExecuteStatement(parameter=10). Here is the performance issue.
It should be something wrong if precompiled doesn’t work. I read source code of JDBC in order to work it out, and find an important setting - cachePrepStmts. What will happen to set it:
jdbc:mysql://127.0.0.1:3306/demo_ds?
useServerPrepStmts=true&cachePrepStmts=true
We get the expected message flow. The speed is much faster than normal query after test.

At the beginning of fifth message, it’s enough to transfers value of parameter for each query. We reach the goal of one precompiled and more preformation in the final, MySQL efficiency improves a lot. Due to shorter length of message, network IO efficiency is much better.
That is how “cachePrepStmts=true” works: JDBC cache needs prepared SQL. Here is an example of “SELECT*FROMt_orderWHEREuser_id=?”, after running once, it skips PreparedStatement next time and make use of ExecuteStatement to set param value.
when making it clear, you will know how to optimize Proxy. Proxy is using Hikari as database connecting pool. In time of initialization, it will set two parameters above.
config.addDataSourceProperty("useServerPrepStmts","true");
config.addDataSourceProperty("cachePrepStmts","true");
This guarantees the performance between Proxy and MySQL services. So how is the performance between Proxy AND Client guaranteed.
Proxy does not forward this message to MySQL when it receives the Client’s PreparedStatement because the fragmentation key in SQL is a question mark and Proxy does not know which real database to route to. Proxy simply catches the SQL upon receiving this message, storing it in a Statementld to the inside of the SQL map, the database is not actually requested until the ExecuteStatement is received.
This logic wad fine before optimization because each query is a new PreparedStatement process, and ExecuteStatement tells the client the parameter type and the parameter value.
With the addition of two parameters, the content of the message changes, and when ExecuteStatement send it a second time, the message body only has the parameter value but not the parameter type, and Proxy can’t retrieve the value correctly without knowing the type. So the optimization that Proxy needs to do is to cache the argument types at the beginning of the PreparedStatement.
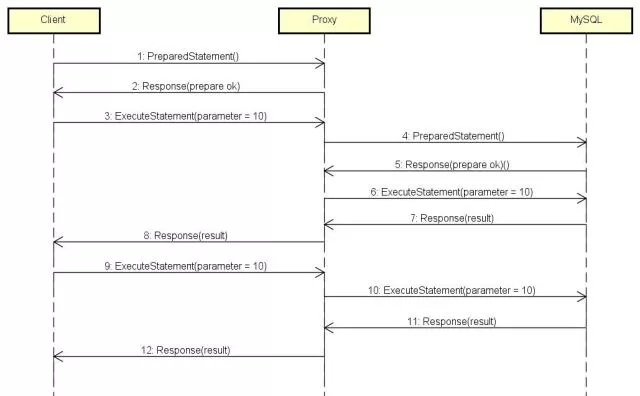
The image above shows interaction between Client and Proxy-MySQL when finishing optimization. From step 9, efficient query occurs.
2. Configuration optimization of Hikari
During initialization, Proxy will configure a Hikari pool for each physical database. According to sharding rule, SQL is route to real database, and get results through Hikari connection, Proxy conflates result and return it to client in the end. What’s the size of database pool? As opinions vary, I’ll give the final conclusion today.
Out of expectation, you will find it’s not question about maximum in the opposite of minimum! Will you feel surprise that serial is faster than parallel when triggering a task?
Even single core cpu supports hundreds of threads at the same time, we know it’s a “time” trick of operating system. In fact, a cpu only performs a thread a time and it triggers next thread when operating system switches context, so it goes back and forth.
Basic principle of CPU calculation is that it is always much faster to execute tasks A and B sequentially than to run them at the same time. In case count of threads is greater than CPU cores, it will be slower, but not faster. A test to Oracle confirms the opition.
Reference Link:
http://www.dailymotion.com/video/x2s8uec
Pool size is decreased from 2048 to 96, TPS is up to 20702 from 16163, average of response is decreased from 110ms to 3ms.
It’s not easy to make counts of connection equal with CPU, we have to take IO of network/disk into consideration. When IO occurs and thread is blocked, operation system will assign free CPU to other threads. If thread is always blocked at I/O, we could set a little more of connection than CPU, then perform more tasks within the same time, but what should value be? PostgreSQL does a benchmark test:
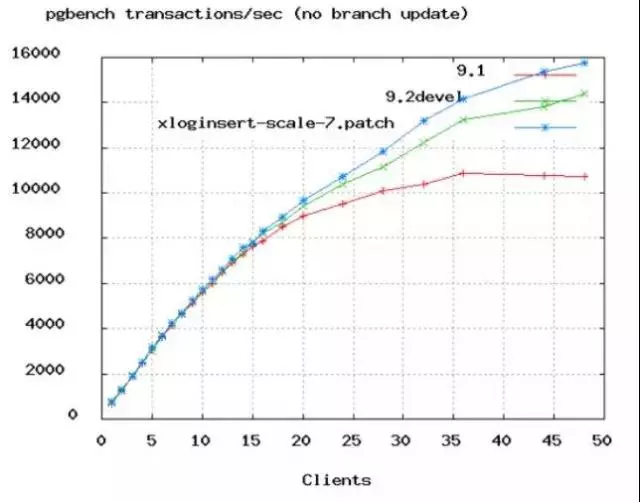
Increased speed of TPS starts to be slow from 50. According to the result, PostgreSQL gives the following formula:
connections=((core_count*2)+effective_spindle_count)
connection count = ((cores*2) + count disk). 60 connections are enough at a 32 core machine. so there is no need to set hundreds of connections for Proxy, it’s not only wastes resources, but also slows down the speed.
3. Optimization of resultset conflation
Proxy communicates with real database by JDBC at present, asynchronous access mode of Netty+MySQLProtocol will be released soon. They will coexist, which way to choose depends on client.
JDBC’s resultset in Proxy can cause great memory pressure. Proxy frontend links to m clients and its backend links to n physical databases though, when backend transfers data to client in the front, these data will store into Proxy memory. If those data stays long time, there will be no memory left and service will be unavailable in the end. Resultset memory efficiency can be optimized in two ways: one way is to reduce data residence time in proxy; the other is current limiting.
Let’s see how it behaves before optimization. 5 clients link to Proxy, each one queries 150000 data. result is as follows:

Memory of Proxy increases all the time, although GC is triggered. The reason is that ResultSet will be blocked next() until all the querying datas storing into memory. It’s default way for ResultSet to retrieve data.
Is there any way to consume data immediately when ResultSet getting an item? Here is description in the Connector/J document:
If you are working with ResultSets that have a large number of rows or large values and cannot allocate heap space in your JVM for the memory required, you can tell the driver to stream the results back one row at a time.
Link reference:
https://dev.mysql.com/doc/connector-j/5.1/en/connector-j-reference-implementation-notes.html
To activate the ability, you only need to set a parameter when creating the statement instance:
stmt.setFetchSize(Integer.MIN_VALUE);
You make it. Proxy consumes data at once by next() after querying the instruction, these data will be clean up at next GC. During resultset conflation, we also need to merge data in time, there is need to merge after retrieving them all, Sharding-Core provides the interface. Here is the optimized result, figure1 below:

Data in the memory stays shorter, GC recycles data each time, memory efficiency improves a lot. It seems we are crowned with success, but issues are deep in, follow with me to figure them out. The expected situation where the speed of data consumption from Client is faster than the one from Proxy at figure2.

What happens for Proxy to consumes data slower or not to work? From my test, memory usage increases linearly, stronger than figure1, Proxy is KO finally when it runs out of memory.
Let’s analyze the reason, and then I’ll introduce second optimization: Current limiting
Main settings about cache as follows::
-
SO_RCVBUF/SO_SNDBUF is for TCP cache;
-
ChannelOutboundBuffer is for Netty writing cache.
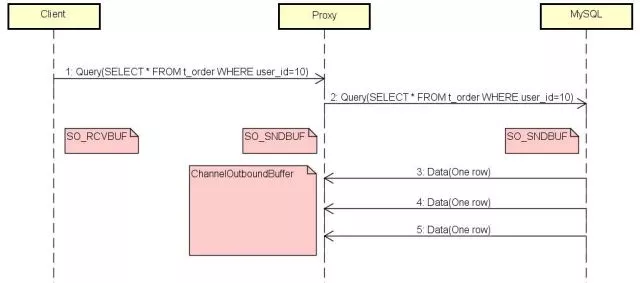
When Client is blocked, its SO_RCVBUF runs out instantly, then it notifies Proxy not to send data any more by slide window, SO_SNDBUF of Proxy is filled by Netty immediately at the same time.
ChannelOutboundBuffer of Netty swallows all the data from MySQL when SO_SNDBUF is up to top value, because it is unbounded by default.
SO_RCVBUF of Proxy has free memory due to Netty consumption, it causes MySQL sending data all the time, Netty always fills data into ChannelOutboundBuffer where to lead to serious results - no memory left.
When making it clear, our purpose is that Proxy will not accept MySQL data if Client is blocked.
Netty controls writing cache through WRITE_BUFFER_WATER_MARK parameter:
-
when Buffer size is up to high watermark, Netty will not produce data any more, unless it’s under low watermark;
-
Proxy implies MySQL not to send data if SO_RCVBUF is filled with after ChannelOutboundBuffer run out.
So the key of the issue is its value for ChannelOutboundBuffer high watermark. On the condition Proxy consumes its memory based on high watermark of ChannelOutboundBuffer.
4. Proxy Modes
There will be two agent modes configuration in the upcoming version of sharding-sphere 3.0.0.m2:
-
MEMORY_STRICTLY: Proxy keeps all connections of database routed to, it’s a good way to make use of ResultSet flow to conserve memory.
-
CONNECTION_STRICTLY: Agent releases connections when getting all of data from ResultSet, then its memory increases more than before.
Let’s make it simple, set MEMORY_STRICTLY mode if you want less consumption of memory; set CONNECTION_STRICTLY mode if you want less consumption of connections.
We have analyzed MEMORY_STRICTLY principle before, it also has side effect that ResultSet flow needs to keep database connection, after creating real connection where to route to all of physical tables, it could merge data instantly and return results to client.
Suppose that a database is set to max_user_connections=80, and it is routed to 100 tables resulting in being impossible to create 100 connections in the same time and no merging result to return.
In order to resolve the problem above, CONNECTION_STRICTLY comes out, it doesn’t make use of ResultSet flow which causes memory increasing. CONNECTION_STRICTLY doesn’t need to keep in touch with database, it will release connection after retrieving all the data in ResultSet.
We use the same setting max_user_connections=80 as example, the database is routed to 100 tables. Proxy create 80 connections for querying data at first, the other 20 connections will be cached into pool. These 20 connections will be created successfully one after another within querying completion before.
If you feel confused, please keep it in mind CONNECTION_STRICTLY is a scenario that max_user_connections are less than maximums of tables routed to.
03 Summary
Sharding-Sphere has been continuous improvement and development since 2016. A growing number of companies and individuals uses it, and they provide many successful cases for us. We will move forward to improve current features, achieve soft transaction, data governance and so on in succession. If someone has good ideas or wants to do proposals, welcome to join Sharding-Sphere open source project.
Q&A
Q1: What’s Sidecar?
A1: Sharding-Sidecar is the third product of Sharding-Sphere, it’s on the way. It’s in form of DaemonSet to agent all the databases targeted at cloud native database proxy.
Q2: Is it correct that “please keep it in mind CONNECTION_STRICTLY is a scenario that max_user_connections is less than maximums of tables routed to”?
A2: CONNECTION_STRICTLY is for decreasing connections. It’s small for max_user_connections, so we use CONNECTION_STRICTLY mode.
Q3: Within the “stmt.setFetchSize(custom_size)” scenario, it’s similar with ORM frameworks like Mybatis to query an amount of data into memory, these data are stored into list in general to handle them. They still occupy memory.
A3: It’s client memory in this situation, it is no influence of Proxy.
Q4: If we have lots of data in memory, is it only one way to use native JDBC to query/handle data every time without putting them into memory?
A4: Client takes control of Mybatis, it has nothing to do with Proxy.
Link of Live playback
https://m.qlchat.com/topic/details?topicId=2000001395952730&minimal=1
Do you want to know more about Sharding-Sphere?
Come to “2018 DAMSChina Data Asset Management Summit”
Attend the analysis of lecturer Zhang Liang who is responsible for database development of JD Finance