AutoTable: Your Butler-Like Sharding Configuration Tool
Summary
In the previous article “An Introduction to DistSQL” written by Haoran Meng, the Apache ShardingSphere Committer shared the motivating reasons behind the design of DistSQL, explained its syntax system, and impressively showcased how you can use one SQL to create a sharding table.
We believe that you should be now more familair with the new capabilities Apache ShardingSphere can bring you.
Following the article’s publication, we received many messages from our readers and users. They wanted to know the details of using DistSQL to configure sharding rules, and whether they can still use DistSQL to quickly create and configure a sharding table with configs like YAML or Namespace. Today, we’d like to introduce your new sharding configuration butler AutoTable to you.
Background
Sharding is the core feature of Apache ShardingSphere. We guess, your old sharding workflow (without data migration) probably looks like the one below:
Figure 1: Sharding Workflow
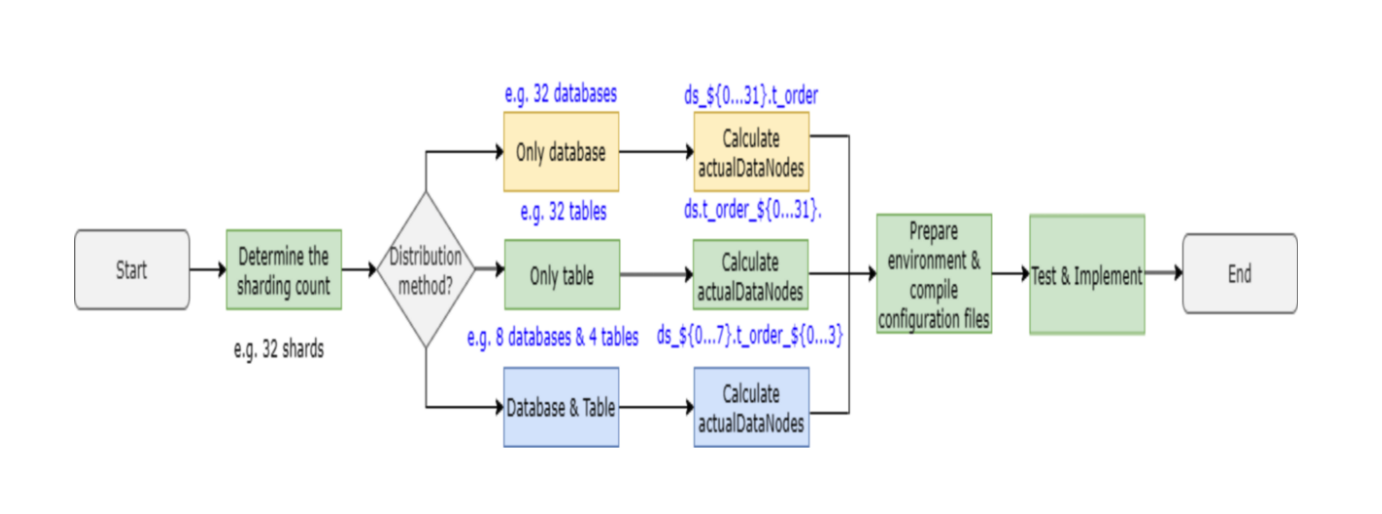
In such workflow, you have to clearly know your sharding strategies, and the actual table names and their datasources. Then, you base your sharding rules on such information.
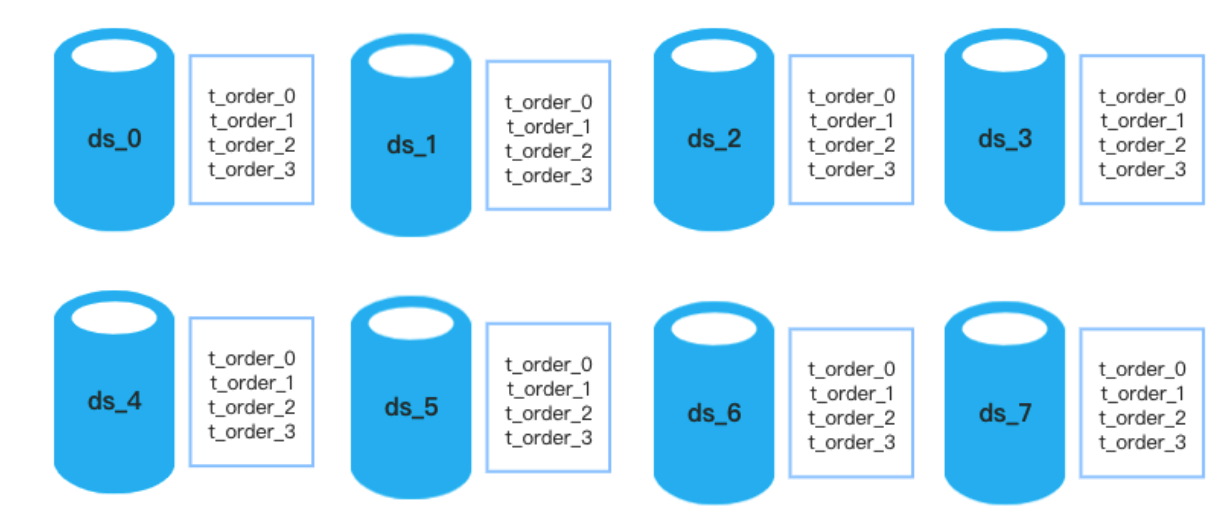
One of the table distribution results may be 8 sharding databases each containing 4 tables.
Figure 2: 8 Databases * 4 Tables Distribution
Problem
Only when you are 100% sure about the table distribution you can code the correct actualDataNodes rules. Otherwise, you may write the wrong one. The correct sharding rule in this case looks like this:
tables:
t_order:
actualDataNodes: ds_${0..7}.t_order_${0..3}
databaseStrategy:
standard:
shardingColumn: order_id
shardingAlgorithmName: database_inline
tableStrategy:
standard:
shardingColumn: order_id
shardingAlgorithmName: table_inline
shardingAlgorithms:
database_inline:
type: INLINE
props:
algorithm-expression: ds_${order_id % 8}
table_inline:
type: INLINE
props:
algorithm-expression: t_order_${order_id % 4}
ShardingSphere actually has very user-friendly configuration rules. However, users may still have difficulties, such as:
-
Failure to understand sharding strategies or rules;
-
Inconsistency between sharding rules and actual table distribution;
-
Wrong configuration expressions.
We always pay attention to user issues. For example, we have noticed one of our users found the following issue:
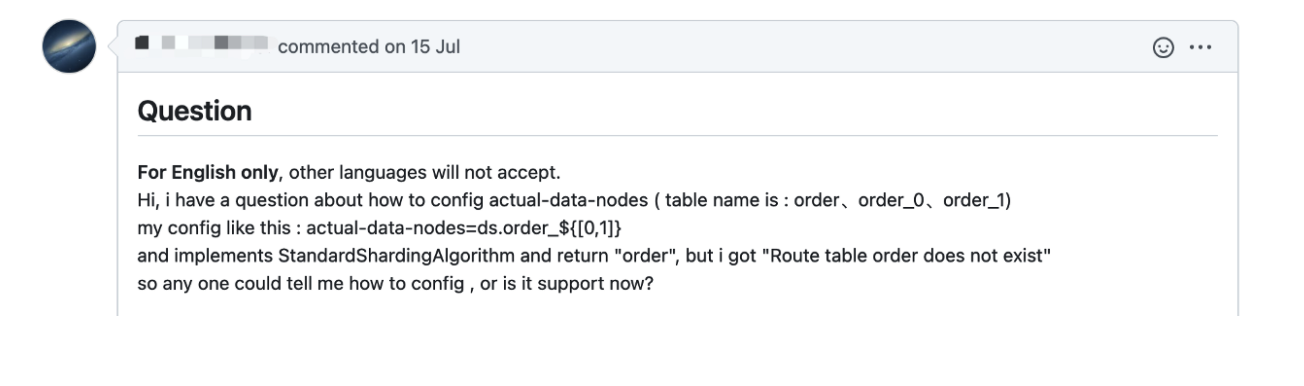
Why You Need AutoTable?
Apache ShardingSphere Version 5.0.0 launched AutoTable, a new method that makes sharding configuration easier for you.
Literally, AutoTable means automated table sharding. When you use AutoTable, you only need to specify the sharding count and the datasource. Thanks to AutoTable, you no longer need to worry about actual table distribution.The correct configuration format is shown as follows:
autoTables:
t_order:
# Specify your datasources
actualDataSources: ds_${0..7}
shardingStrategy:
standard:
shardingColumn: order_id
shardingAlgorithmName: mod
shardingAlgorithms:
mod:
type: MOD
props:
# Specify your sharding-count
sharding-count: 32
Due to AutoTable configuration, ShardingSphere is able to recognize that the logic table t_order has 8 datasources and needs 32 sharding tables, and then it automatically calculates the distribution result: 8 sharding databases* 4 sharding tables. The result is exactly the same.
AutoTable & DistSQL
Now, you know more about AutoTable. However, when you combine AutoTable with DistSQL, the results are even more impressive as it can greatly simplify sharding configuration for you. Unlike the old method, the DistSQL configuration rule works immediately so you no longer need to restart it anymore. Besides, one rule change will never have impact on others.
DistSQL supports three expressions used to manage sharding table rules: create, alter and drop.
# Create a sharding table rule
CREATE SHARDING TABLE RULE t_order (
RESOURCES(resource_0,resource_1),
SHARDING_COLUMN=order_id,TYPE(NAME=hash_mod,PROPERTIES("sharding-count"=4))
);
# Ater a sharding table rule
ALTER SHARDING TABLE RULE t_order (
RESOURCES(resource_0,resource_1),
SHARDING_COLUMN=order_id,TYPE(NAME=hash_mod,PROPERTIES("sharding-count"=10))
);
# Drop a sharding table rule
DROP SHARDING TABLE RULE t_order;
> Note: Rule alteration may have impact on old data. In order to fix the problem, we provide ShardingSphere Scaling that allows you to migrate data and makes it more convenient for you to manage distributed data. We are happy to share more about ShardingSphere Scaling in the near future.
FAQ
Can I use AutoTable in ShardingSphere-JDBC?
Yes, you can.
Both ShardingSphere-JDBC and ShardingSphere-Proxy support AutoTable. What’s more, you can also use DistSQL in Proxy for dynamic configuration in order to meet your various access demands.
Which Sharding Algorithms Does AutoTable Support?
AutoTable supports all automatic sharding algorithms:
-
MOD:Modulo Sharding Algorithm
-
HASH_MOD :Hash Modulo Sharding Algorithm
-
VOLUME_RANGE:Volume Based Range Sharding Algorithm
-
BOUNDARY_RANGE:Boundary Based Range Sharding Algorithm
-
AUTO_INTERVAL : Auto Interval Sharding Algorithm
For more information, please read the Apache ShardingSphere document “Automatic Sharding Algorithm”.
In addition to using build-in algorithms, you can also develop SPI extension to customize your own sharding algorithm when necessary.
I Have Already Used YAML. Can I Use AutoTable Now?
We don’t recommend you to do that.
If you’re sure that such switch can make the table distribution result conform to your expectation, you may have a try. Otherwise, please don’t do that.
However, if you want to create a new table, you are welcome to use AutoTable.
What‘s the Best Scenario for AutoTable?
AutoTable aims to be your butler for sharding configuration. All you need to do is to tell it how many shards you need, and then it saves you the trouble of remembering the actual table location and table count.
To use AutoTable, you better configure rules first and then use CREATE TABLE to create tables. Old habits die hard but please change your old habit: create tables first and then configure rules. Now ShardingSphere is more like an access point of your distributed database, instead of middleware.
My Data Source Names Are Non-Contiguous or I Have Too Many Data Source Names. Can I Use AutoTable?
Yes, you can. When you specify your datasources, their names are not required to be continuous. To solve the problem, you can use enumeration-expression and inline-expression at the same time:
CREATE SHARDING TABLE RULE t_order (
RESOURCES('resource_${0..9}',resource_12,resource_15,"resource_$->{17..19}"),
...
);
Can I use AutoTable and the Old Method Together?
Yes, you can.
For more information, please read: [https://github.com/apache/shardingsphere/blob/master/shardingsphere-jdbc/shardingsphere-jdbc-core/src/test/resources/config/config-sharding.yaml] ()
Reward:
@CatYangWei was the first GitHub user to ask about AutoTable.
We’d like to thank him for helping us find the problem. We do appreciate that. In order to express our gratitude, we will contact you later and send you a gift. as a token of appreciation from the community👏👏👏
We also welcome other community members to help us find more issues, to improve the community.
ShardingSphere Community:
ShardingSphere Github: https://github.com/apache/shardingsphere
ShardingSphere Twitter: https://twitter.com/ShardingSphere
ShardingSphere Slack Channel: apacheshardingsphere.slack.com
Contributor Guide:https://shardingsphere.apache.org/community/en/involved/
Author
Longtao Jiang

SphereEx Middleware Development Engineer & Apache ShardingSphere Contributor.