Kernel Optimizations & Upgrade Guide for Apache ShardingSphere 5.0.0 — The Ideal Database Management Ecosystem
Kernel Optimizations & Upgrade Guide for Apache ShardingSphere 5.0.0 — The Ideal Database Management Ecosystem
Having undergone almost two years of development and optimization, the Apache ShardingSphere 5.0.0 GA version has been recently released. Compared with the 4.1.1 GA version, the new version’s kernel is greatly improved:
-
Kernel optimizations are subject to the pluggable architecture allowing users to combine kernel features as they wish.
-
Aiming to improve SQL distributed query capabilities, the Federation Execution Engine is created to satisfy users’ needs in complex business scenarios.
-
We also made optimizations at the API level to help users reduce costs.
This article will give you a better understanding of some kernel-related changes we made, and the feature differences between the new and the previous ShardingSphere versions. You will also learn more about these optimizations and how to use 5.0.0 version in a practical scenario case that integrates data sharding, read/write splitting, as well as encryption and decryption.
Pluggable Architecture Kernel
The North-Star of Apache ShardingSphere’s 5.0.0 GA version. Our mission with the Database Plus concept is to build a standard layer and ecosystem above fragmented databases’ basic services, and provide users with additional features. A unified and standardized database usage specification provides for upper-level applications, and the challenges faced by businesses due to underlying databases fragmentation get minimized as much as possible. The three characteristics of Database Plus are Link, Enhance, and Pluggable.
ShardingSphere can provide users with management services and enhanced features including distributed database, data security, database gateway, and stress testing. The plugin oriented kernel architecture allows for modularity, and users can flexibly extend the features as they need.
The emergence of the Database Plus concept indicates that ShardingSphere has evolved from a middleware into an innovative distributed database ecosystem. Since we set Database Plus as our new direction and there are many extension points in our pluggable system, having a pluggable kernel was a given. The figure below illustrates the new pluggable Kernel:
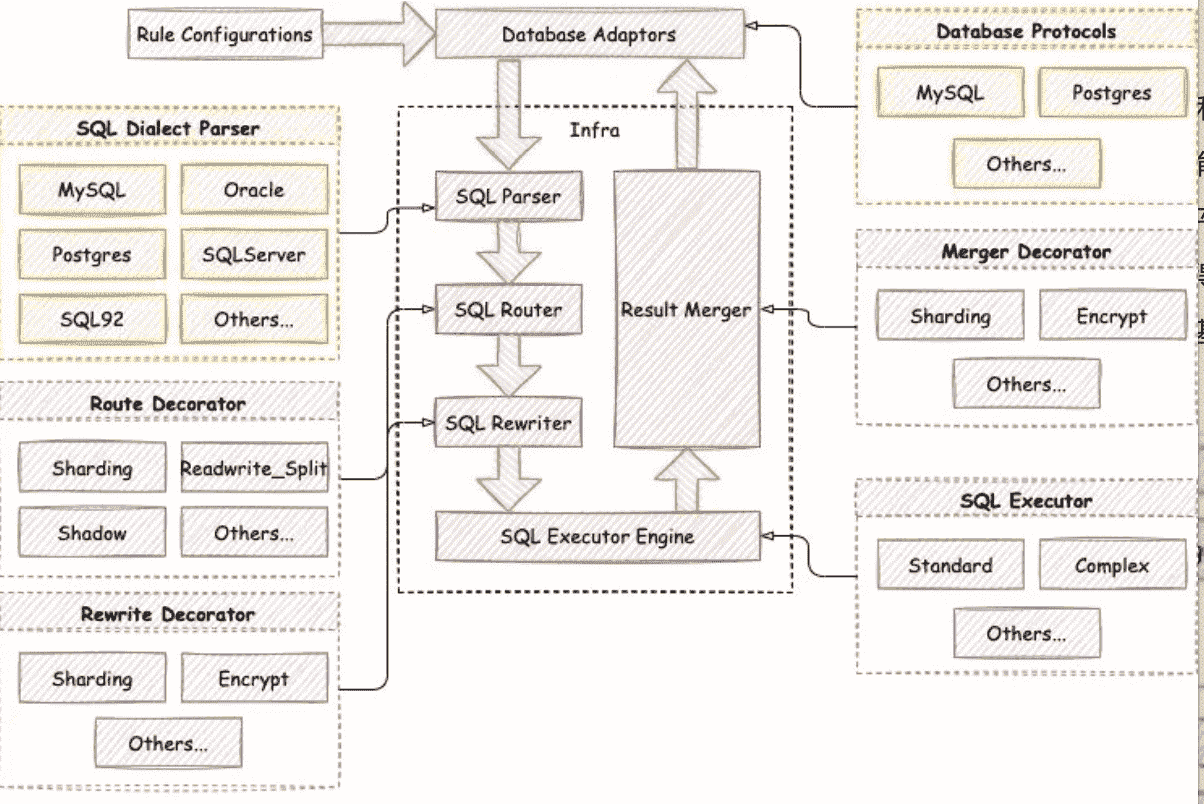
All of Apache ShardingSphere kernel’s processes (i.e. metadata loader, SQL parser, SQL router, SQL rewriter, and SQL executor & result merger) provide extension points on which ShardingSphere implements default features such as data sharding, read/write splitting, encryption & decryption, shadow database stress testing, and high availability.
We can divide the extension points into two categories: feature-based extension points and technology-based extension points.
Among the kernel processes, technical extension points include the extension points of the SQL Parser Engine and SQL Executor engine. Function extension points are the extension points of the Metadata Loading, SQL Router Engine, SQL Rewriter Engine, and SQL Executor & Result Merger Engine.
The extension points of the SQL Parser Engine are SQL AST Analysis and SQL Tree Traversal. The SQL Parser Engine built on these two extension points can parse and support many database dialects such as MySQL, PostgreSQL, Oracle, SQLServer, openGauss, and SQL92 by default. Users can also write code to parse more database dialects not currently supported by Apache ShardingSphere SQL Parser, or develop SQL Audit and other new features.
How about the SQL Execution Engine extension points? Its extension depends on different execution methods. Currently, Apache ShardingSphere’s SQL Executor has a single-threaded execution engine and a multi-threaded execution engine. The single-threaded execution engine is used to execute transaction statements, while the multi-threaded one applies to scenarios that do not include transactions to improve SQL execution performance. In the future, we will provide more execution engines such as MPP Execution Engine that meets the requirements for SQL execution in distribution scenarios.
Apache ShardingSphere provides function extension points for data sharding, read/write splitting, encryption & decryption, shadow database stress testing, and high availability. These features implement all or part of the function extension points to meet their needs. Meanwhile, within each of them, internal sub-level function extension points such as Sharding Strategy, Distributed ID Generator, and Load Balancing Algorithm are also provided. The following extension points are implemented in the Apache ShardingSphere kernel functions:
-
Data Sharding: implements all the extension points of the metadata loader, SQL router, SQL rewriter and result merger. For the data sharding function, extension points such as sharding algorithm and distributed ID are provided.
-
Read/write Splitting: implements the function extension point SQL Router and for the function, the Load Balancing Algorithm extension point is provided.
-
Encryption & Decryption: implements metadata Loader, SQL Rewriter and Result Merger. Inside, the Encrypt and Decrypt Algorithm extension point is provided.
-
Shadow Database Stress Testing: implements the extension point SQL Router. The sub-level extension point Shadow Algorithm is provided.
-
High Availability: also implements the SQL Router extension point.
Given the extension points, Apache ShardingSphere functions are truly scalable. Multi-tenancy, SQL Audit, and other new features will be seamlessly added to the ecosystem via these extension points.
Additionally, a user can also leverage these extension points to develop custom features when development needs to quickly deploy a distributed database system. For a detailed description of the pluggable architecture’s extension points, please refer to the developer manual:
We compare the 5.0.0 GA version’s pluggable kernel with that of the 4.1.1 GA version and find some major differences (as shown in the table below):
| Version | 4.1.1 GA | 5.0.0 GA |
|---|---|---|
| Positioning | Database Sharding Middleware | Distributed Database Ecosystem |
| Functions | Only provide basic functions | Provide infrastructure and best practices |
| Coupling | High coupling; intertwined | Low coupling; independent |
| Feature Combination | Fixed feature combination; features like read-write splitting and encryption & decryption must combine with data sharding. | Free feature combination. Users can freely combine features like data sharding, read-write splitting, shadow database stress testing, encryption or decryption, and high availability. |
First, the two versions have different product positioning. Version 5.0.0 GA is the milestone in Apache ShardingSphere’s evolution from a database sharding middleware into a distributed database ecosystem where features can be easily integrated into the pluggable architecture.
Second, the 4.1.1 GA version only supports basic functions, while the 5.0.0 GA version cares about the infrastructure and feature best practices. Users are even allowed to drop some features and develop their custom functions on the kernel infrastructure. In terms of coupling, the kernel functions in the 5.0.0 GA version are isolated from each other, so they cannot perceive the existence of another feature, ensuring kernel stability to the greatest extent. Lastly, considering function combination, the 5.0.0 version places all features (e.g. data sharding, read/write splitting, shadow database stress testing, encryption & decryption, and high availability) at the same level, so users can combine features as they prefer. The 4.1.1 GA version imposes data sharding on other functions.
In summary, the enhanced 5.0.0 GA version’s pluggable kernel allows users to freely combine functions to satisfy their business needs just as if they were building blocks. However, adopting the new pluggable architecture also changes the ways we use kernel functions.
In this article, we’d like to showcase some practical examples and showcase how to combine these functions in the 5.0.0 GA version.
Federation Execution Engine
Federation Execution Engine is another spotlight of the 5.0.0 GA version’s kernel. We aim to support distributed query statements that don’t work in the 4.1.1 GA version, such as cross-database instances related queries and subqueries. Thanks to the Federation Execution Engine, developers no longer need to worry about the usage scope of SQLs, and they can concentrate on their business function development, reducing function limitations at the business level.
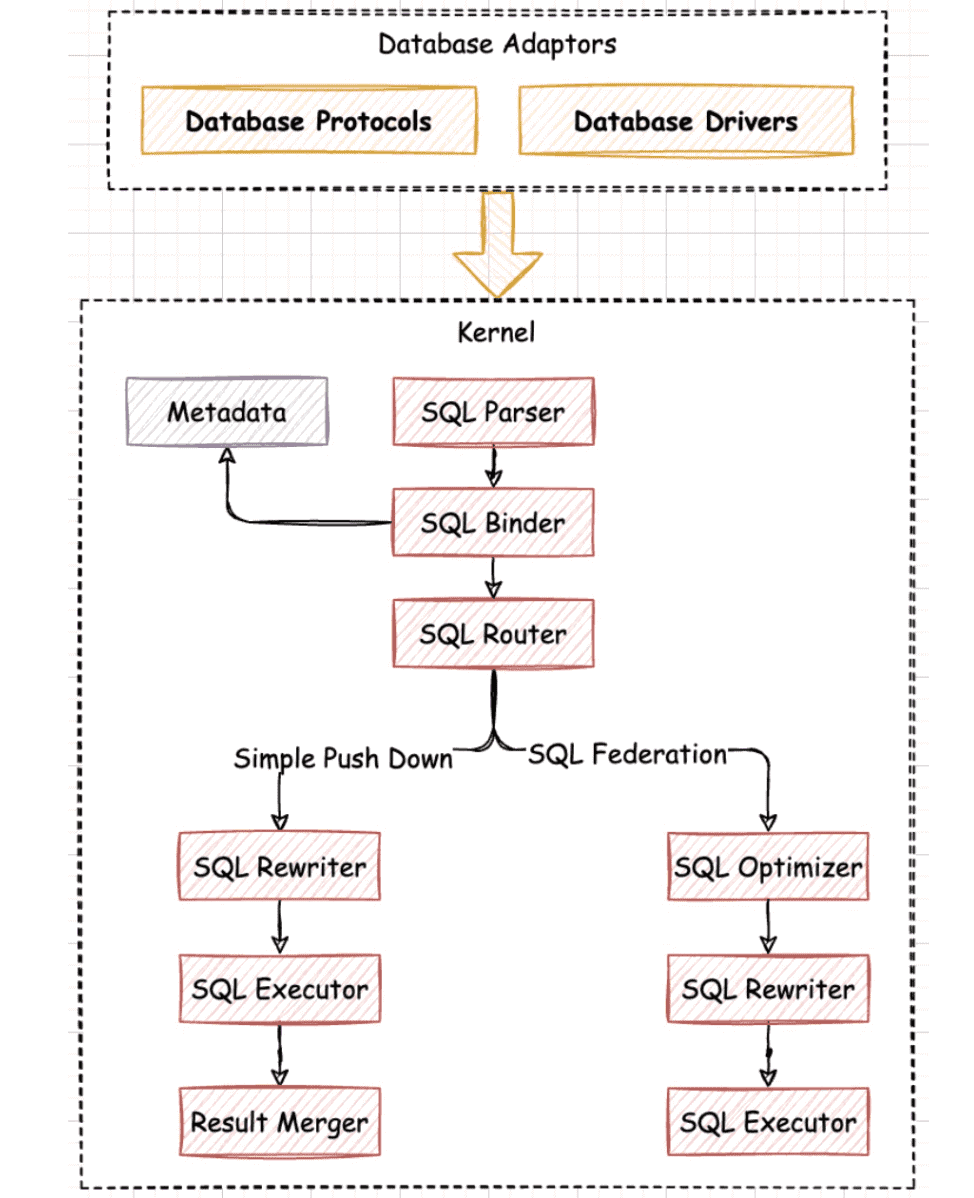
The figure above illustrates the flow of the Federation Execution Engine. In general, the flow still follows the sequence: SQL Parser, SQL Router, SQL Rewriter, and then SQL Executor. The only different step is the additional SQL Optimizer used in the Federation Execution Engine. The optimizer contains RBO (Rule-Based Optimizer) and CBO (Cost-Based Optimizer) to optimize distributed query statements and get the execution plan with minimal cost. In the SQL Router, the router engine analyzes whether a SQL statement is given to cross-database instances and if yes, it determines to use Federation Execution Engine to execute the SQL.
The Federation Execution Engine is still an experimental feature, so it is disabled by default. If you want to use the engine, you can enable it by configuring sql-federation-enabled: true.
Federation Execution Engine applies to cross-database instances related queries and subqueries, and some aggregate queries not supported by the kernel. There are specific scenario examples below that we give to help you understand the statements supported by the Federation Execution Engine.
- Cross-DataNode Related Query: Federation Execution Engine is used when multiple tables of a relational query are distributed on different database instances.
For example, see the following data sharding configuration: t_order and t_order_item tables are table shards with multiple data nodes, and no binding table rules are configured, while t_user and t_user_role are single tables distributed on different database instances.
rules:
- !SHARDING
tables:
t_order:
actualDataNodes: ds_${0..1}.t_order_${0..1}
tableStrategy:
standard:
shardingColumn: order_id
shardingAlgorithmName: t_order_inline
t_order_item:
actualDataNodes: ds_${0..1}.t_order_item_${0..1}
tableStrategy:
standard:
shardingColumn: order_id
shardingAlgorithmName: t_order_item_inline
The following SQL commands are often used for cross-database instances, so it’s suggested to use Federation Execution Engine to complete these relational queries:
SELECT * FROM t_order o INNER JOIN t_order_item i ON o.order_id = i.order_id WHERE o.order_id = 1;
SELECT * FROM t_order o INNER JOIN t_user u ON o.user_id = u.user_id WHERE o.user_id = 1;
SELECT * FROM t_order o LEFT JOIN t_user_role r ON o.user_id = r.user_id WHERE o.user_id = 1;
SELECT * FROM t_order_item i LEFT JOIN t_user u ON i.user_id = u.user_id WHERE i.user_id = 1;
SELECT * FROM t_order_item i RIGHT JOIN t_user_role r ON i.user_id = r.user_id WHERE i.user_id = 1;
SELECT * FROM t_user u RIGHT JOIN t_user_role r ON u.user_id = r.user_id WHERE u.user_id = 1;
- Sub query: Simple Push Down Engine supports subqueries with consistent sharding conditions, and sub-queries routed to a single shard. When you don’t specify the same shard key for the sub-query and the outer query, or you give the inconsistent value of a shard key, you will need the Federation Execution Engine.
The code block below displays some sub-queries supported by the Federation Execution Engine:
SELECT * FROM (SELECT * FROM t_order) o;
SELECT * FROM (SELECT * FROM t_order) o WHERE o.order_id = 1;
SELECT * FROM (SELECT * FROM t_order WHERE order_id = 1) o;
SELECT * FROM (SELECT * FROM t_order WHERE order_id = 1) o WHERE o.order_id = 2;
- Aggregate Query: Currently, Apache ShardingSphere Simple Push Down Engine cannot support all aggregate queries. However, you can use Federation Execution Engine to execute aggregate queries not supported by Simple Push Down Engine.
SELECT user_id, SUM(order_id) FROM t_order GROUP BY user_id HAVING SUM(order_id) > 10;
SELECT (SELECT MAX(user_id) FROM t_order) a, order_id FROM t_order;
SELECT COUNT(DISTINCT user_id), SUM(order_id) FROM t_order;
Federation Execution Engine significantly enhances distributed query capabilities of Apache ShardingSphere. In the future, we will continue to optimize Apache ShardingSphere, aiming at reducing memory usage of the Federation Execution Engine, and improve distributed query capabilities.
Feature API Adjustments
To help users minimize related costs, the 5.0.0 GA version has made many optimizations at the API level. According to some community feedback, the Data Sharding API was too complex and difficult to understand. After a community-level discussion, we decided to provide a brand-new data sharding API in the new GA version.
With Apache ShardingSphere project positioning changed from a database middleware to a distributed database ecosystem, we had to develop a transparent data sharding function. To be precise, in the 5.0.0 GA, we provide users with Auto Sharding Strategy, so they don’t need to worry about the details of the databases and tables because they can use auto sharding to specify the number of shards. Due to the new pluggable architecture and some enhanced functions such as shadow database stress testing, kernel function APIs have been adjusted accordingly. In this section, we introduce the adjustments made in different APIs.
Data Sharding API
Following the previous 4.x version was released, users often reached out to us in the community and complained that the API for data sharding was too complex and hard to use. The code block below shows you the data sharding configuration in the 4.1.1 GA version. In the old version, there were five sharding strategies, namely standard, complex, inline, hint, and none. It was difficult for users to understand and use different parameters of different sharding strategies.
shardingRule:
tables:
t_order:
databaseStrategy:
standard:
shardingColumn: order_id
preciseAlgorithmClassName: xxx
rangeAlgorithmClassName: xxx
complex:
shardingColumns: year, month
algorithmClassName: xxx
hint:
algorithmClassName: xxx
inline:
shardingColumn: order_id
algorithmExpression: ds_${order_id % 2}
none:
tableStrategy:
...
In the 5.0.0 GA version, we simplify the sharding strategies in Data Sharding API. First, the original inline strategy is now removed, and we retain the remaining four sharding strategies i.e. standard, complex, hint, and none.
At the same time, the Sharding Algorithm is extracted from Sharding Strategy. Now users can configure it under the property shardingAlgorithms and specify shardingAlgorithmName as a reference in Sharding Strategy.
- !SHARDING
tables:
t_order:
databaseStrategy:
standard:
shardingColumn: order_id
shardingAlgorithmName: database_inline
complex:
shardingColumns: year, month
shardingAlgorithmName: database_complex
hint:
shardingAlgorithmName: database_hint
none:
tableStrategy:
...
shardingAlgorithms:
database_inline:
type: INLINE
props:
algorithm-expression: ds_${order_id % 2}
database_complex:
type: CLASS_BASED
props:
strategy: COMPLEX
algorithmClassName: xxx
database_hint:
type: CLASS_BASED
props:
strategy: HINT
algorithmClassName: xxx
The code block above is the new configuration, which differs from the Sharding configuration in the 4.1.1 GA version. The new sharding API is more concise and clear.
To help users reduce configuration workload, Apache ShardingSphere provides many built-in sharding algorithms, and they can also choose custom settings via the sharding algorithmCLASS_BASED. For more information about the built-in sharding algorithms, please read “Built-in Algorithm-Sharding Algorithm”:
To implement transparent data sharding, we add Automated Sharding Strategy into the 5.0.0 GA version. The code block below shows you the difference between Automated Sharding Strategy configuration and manual sharding strategy configuration:
rules:
- !SHARDING
autoTables:
# Automated Sharding Strategy
t_order:
actualDataSources: ds_0, ds_1
shardingStrategy:
standard:
shardingColumn: order_id
shardingAlgorithmName: auto_mod
keyGenerateStrategy:
column: order_id
keyGeneratorName: snowflake
shardingAlgorithms:
auto_mod:
type: MOD
props:
sharding-count: 4
tables:
# Manual Sharding Strategy
t_order:
actualDataNodes: ds_${0..1}.t_order_${0..1}
tableStrategy:
standard:
shardingColumn: order_id
shardingAlgorithmName: table_inline
dataBaseStrategy:
standard:
shardingColumn: user_id
shardingAlgorithmName: database_inline
Automated Sharding Strategy must be configured under autoTables attribute. Users only need to specify the data source for data storage as well as the number of shards via Automated Sharding Algorithm. They no longer need to manually set data distribution through actualDataNodes, or to pay extra attention to setting database sharding strategy and table sharding strategy, as Apache ShardingSphere automatically helps users manage data sharding.
We also remove defaultDataSourceName from Data Sharding API. We have repeatedly highlighted that Apache ShardingSphere is a distributed database ecosystem now. The message we want to send to users is that you can directly use the services provided by Apache ShardingSphere but when you use the services, you’ll probably feel like you are just using a traditional database. You don’t have to perceive underlying database storage. Apache ShardingSphere’s built-in SingleRule can manage single tables beyond data sharding, aiming to help users implement single table automatic loading & routing.
Additionally, to further simplify configuration, in conjunction with the defaultDatabaseStrategy and defaultTableStrategy sharding strategies in Data Sharding API, defaultShardingColumn as the default sharding key is added as well.
When multiple tables have the same sharding key, the user only needs to use the default defaultShardingColumn rather than shardingColumn. The sharding strategy of the t_order table is set via the default defaultShardingColumn(see the codes below).
rules:
- !SHARDING
tables:
t_order:
actualDataNodes: ds_${0..1}.t_order_${0..1}
tableStrategy:
standard:
shardingAlgorithmName: table_inline
defaultShardingColumn: order_id
defaultDatabaseStrategy:
standard:
shardingAlgorithmName: database_inline
defaultTableStrategy:
none:
- Read/Write Splitting API
We didn’t make a lot of changes to the Read/write Splitting API in the 5.0.0 GA version. We only adjusted fromMasterSlave to ReadWriteSplitting while other usages are unchanged. The following code block shows you the differences between the Read/write Splitting API of the 4.1.1 GA version and that of the 5.0.0 GA version.
# 4.1.1 GA Read/Write Splitting API
masterSlaveRule:
name: ms_ds
masterDataSourceName: master_ds
slaveDataSourceNames:
- slave_ds_0
- slave_ds_1
# 5.0.0 GA Read/Write Splitting API
rules:
- !READWRITE_SPLITTING
dataSourceGroups:
pr_ds:
writeDataSourceName: write_ds
readDataSourceNames:
- read_ds_0
- read_ds_1
Additionally, the High Availability function developed in the pluggable architecture plus Read/write Splitting can provide an automated switch between master and slave, producing a high availability version of read-write splitting. If you are interested in the high-availability function, keep an eye on our GitHub repo or socials. We will soon publish related documents and technical blogs.
- Encryption & Decryption API
There are no changes in the 5.0.0 version API.
- !ENCRYPT
encryptors:
aes_encryptor:
type: AES
props:
aes-key-value: 123456abc
md5_encryptor:
type: MD5
tables:
t_encrypt:
columns:
user_id:
cipherColumn: user_cipher
encryptorName: aes_encryptor
order_id:
cipherColumn: order_cipher
encryptorName: md5_encryptor
- Shadow Database Stress Testing API
We completely adjust the Shadow Database Stress Testing API in version 5.0.0 GA. The first adjustment is the deletion of logical columns in Shadow Database, and the creation of Shadow Database Matching Algorithm to help users flexibly control routing.
The code block below is the Shadow Database Stress Testing API of the old 4.1.1 GA version. Honestly, the function is quite simple: according to the logic column value, users can judge whether the shadow database stress test is enabled or not.
shadowRule:
column: shadow
shadowMappings:
ds: shadow_ds
In the 5.0.0 GA version, Shadow Database Stress Testing API is much more powerful. Users can enable the test via enable attribute. At the same time, fine-grained control of production tables is implemented.
The new API also supports a variety of matching algorithms, such as column value matching algorithm, column regular expression matching algorithm, and SQL comment matching algorithm.
rules:
- !SHADOW
enable: true
dataSources:
shadowDataSource:
sourceDataSourceName: ds
shadowDataSourceName: shadow_ds
tables:
t_order:
dataSourceNames:
- shadowDataSource
shadowAlgorithmNames:
- user-id-insert-match-algorithm
- simple-hint-algorithm
shadowAlgorithms:
user-id-insert-match-algorithm:
type: COLUMN_REGEX_MATCH
props:
operation: insert
column: user_id
regex: "[1]"
simple-hint-algorithm:
type: SIMPLE_HINT
props:
shadow: true
foo: bar
Due to the word limit of the article, we cannot introduce the shadow database stress testing function in detail — but we will share more related technical content soon. If you’re interested in shadow database matching algorithms, please read “Shadow Algorithm”:“Shadow Algorithm”
Your Upgrade Guide to Apache ShardingSphere 5.0.0
In previous sections, we discussed some optimizations related to 5.0.0 GA’s kernel, namely the pluggable kernel, Federation Execution Engine, and kernel function API adjustments. There are additional differences to be discussed later, but I guess what you’re most concerned about now is how to upgrade from 4.1.1 GA to the 5.0.0 GA version.
In this section, taking a typical scenario integrating data sharding, read/write splitting, and encryption/decryption as an example, we will explain in detail the solutions to some issues you may encounter during your upgrade process.
Using the 4.1.1 GA version, you must add read/write splitting and encryption/decryption on data sharding. The old version’s configuration is shown below:
shardingRule:
tables:
t_order:
actualDataNodes: ms_ds_${0..1}.t_order_${0..1}
tableStrategy:
inline:
shardingColumn: order_id
algorithmExpression: t_order_${order_id % 2}
t_order_item:
actualDataNodes: ms_ds_${0..1}.t_order_item_${0..1}
tableStrategy:
inline:
shardingColumn: order_id
algorithmExpression: t_order_item_${order_id % 2}
bindingTables:
- t_order,t_order_item
broadcastTables:
- t_config
defaultDataSourceName: ds_0
defaultDatabaseStrategy:
inline:
shardingColumn: user_id
algorithmExpression: ms_ds_${user_id % 2}
defaultTableStrategy:
none:
masterSlaveRules:
ms_ds_0:
masterDataSourceName: ds_0
slaveDataSourceNames:
- ds_0_slave_0
- ds_0_slave_1
loadBalanceAlgorithmType: ROUND_ROBIN
ms_ds_1:
masterDataSourceName: ds_1
slaveDataSourceNames:
- ds_1_slave_0
- ds_1_slave_1
loadBalanceAlgorithmType: ROUND_ROBIN
encryptRule:
encryptors:
aes_encryptor:
type: aes
props:
aes.key.value: 123456abc
tables:
t_order:
columns:
content:
cipherColumn: content_cipher
encryptor: aes_encryptor
t_user:
columns:
telephone:
cipherColumn: telephone_cipher
encryptor: aes_encryptor
In the configuration above, t_order and t_order_item are configured with a sharding rule, and the content field of the t_order table is also set with the encrypt rule of the AES encryptor algorithm. t_user is an unsharded table, and the telephone field is also configured with encrypt rule. In addition, note that the read/write splitting rule and encrypt rule are configured as attributes in Shard Rule. Such configuration proves that other functions are all heavily dependent on data sharding in 4.1.1 GA.
After the configuration is complete, we start the 4.1.1 GA version’s Proxy adopter and initialize the t_order, t_order_item, and t_user tables. The execution results of the initialization statements are as follows:
CREATE TABLE t_order(order_id INT(11) PRIMARY KEY, user_id INT(11), content VARCHAR(100));
# Logic SQL: CREATE TABLE t_order(order_id INT(11) PRIMARY KEY, user_id INT(11), content VARCHAR(100))
# Actual SQL: ds_0 ::: CREATE TABLE t_order_0(order_id INT(11) PRIMARY KEY, user_id INT(11), content VARCHAR(100))
# Actual SQL: ds_0 ::: CREATE TABLE t_order_1(order_id INT(11) PRIMARY KEY, user_id INT(11), content VARCHAR(100))
# Actual SQL: ds_1 ::: CREATE TABLE t_order_0(order_id INT(11) PRIMARY KEY, user_id INT(11), content VARCHAR(100))
# Actual SQL: ds_1 ::: CREATE TABLE t_order_1(order_id INT(11) PRIMARY KEY, user_id INT(11), content VARCHAR(100))
CREATE TABLE t_order_item(item_id INT(11) PRIMARY KEY, order_id INT(11), user_id INT(11), content VARCHAR(100));
# Logic SQL: CREATE TABLE t_order_item(item_id INT(11) PRIMARY KEY, order_id INT(11), user_id INT(11), content VARCHAR(100))
# Actual SQL: ds_0 ::: CREATE TABLE t_order_item_0(item_id INT(11) PRIMARY KEY, order_id INT(11), user_id INT(11), content VARCHAR(100))
# Actual SQL: ds_0 ::: CREATE TABLE t_order_item_1(item_id INT(11) PRIMARY KEY, order_id INT(11), user_id INT(11), content VARCHAR(100))
# Actual SQL: ds_1 ::: CREATE TABLE t_order_item_0(item_id INT(11) PRIMARY KEY, order_id INT(11), user_id INT(11), content VARCHAR(100))
# Actual SQL: ds_1 ::: CREATE TABLE t_order_item_1(item_id INT(11) PRIMARY KEY, order_id INT(11), user_id INT(11), content VARCHAR(100))
CREATE TABLE t_user(user_id INT(11) PRIMARY KEY, telephone VARCHAR(100));
# Logic SQL: CREATE TABLE t_user(user_id INT(11) PRIMARY KEY, telephone VARCHAR(100))
# Actual SQL: ds_0 ::: CREATE TABLE t_user(user_id INT(11) PRIMARY KEY, telephone VARCHAR(100))
The routing & rewriting of the t_order table sharding is normal, but the rewriting of the encryption/decryption function failed. Why?
Because the 4.1.1 GA version does not support rewriting DDL statements in the encryption and decryption scenario. Thus, users have to create encrypt and decrypt tables on the underlying database in advance. Currently, the DDL statement’s encryption and decryption rewriting has been perfectly developed in the 5.0.0 GA version and users no longer need to repeat the unnecessary operation anymore..
Since the t_order_item table does not require encryption or decryption, its routing & rewriting results are normal. But, the t_user table also suffers the problem of failed encrypting/decrypting DDL statements rewriting, and what’s worse, the t_user table is routed to the ds_0 data source. To fix such problems, we configure defaultDataSourceName: ds_0 in Sharding Rule. The rule is designed for routing unsharded tables.
As for the t_order table and the t_user table, we use the following SQL statements and manually create encrypt/decrypt tables on the underlying database of the routing result.
# ds_0 Creare t_order_0, t_order_1 and t_user
CREATE TABLE t_order_0(order_id INT(11) PRIMARY KEY, user_id INT(11), content_plain VARCHAR(100), content_cipher VARCHAR(100))
CREATE TABLE t_order_1(order_id INT(11) PRIMARY KEY, user_id INT(11), content_plain VARCHAR(100), content_cipher VARCHAR(100))
CREATE TABLE t_user(user_id INT(11) PRIMARY KEY, telephone_plain VARCHAR(100), telephone_cipher VARCHAR(100))
# ds_1 Create t_order_0 and t_order_1
CREATE TABLE t_order_0(order_id INT(11) PRIMARY KEY, user_id INT(11), content_plain VARCHAR(100), content_cipher VARCHAR(100))
CREATE TABLE t_order_1(order_id INT(11) PRIMARY KEY, user_id INT(11), content_plain VARCHAR(100), content_cipher VARCHAR(100))
After restarting the Proxy, we add data to the t_order, t_order_item, and t_user tables, during which data will be routed to the data node according to the shard key and the configured sharding strategy. The t_user table is routed to ds_0 data source based on the defaultDataSourceName configuration.
INSERT INTO t_order(order_id, user_id, content) VALUES(1, 1, 'TEST11'), (2, 2, 'TEST22'), (3, 3, 'TEST33');
# Logic SQL: INSERT INTO t_order(order_id, user_id, content) VALUES(1, 1, 'TEST11'), (2, 2, 'TEST22'), (3, 3, 'TEST33')
# Actual SQL: ds_0 ::: INSERT INTO t_order_0(order_id, user_id, content_cipher, content_plain) VALUES(2, 2, 'mzIhTs2MD3dI4fqCc5nF/Q==', 'TEST22')
# Actual SQL: ds_1 ::: INSERT INTO t_order_1(order_id, user_id, content_cipher, content_plain) VALUES(1, 1, '3qpLpG5z6AWjRX2sRKjW2g==', 'TEST11'), (3, 3, 'oVkQieUbS3l/85axrf5img==', 'TEST33')
INSERT INTO t_order_item(item_id, order_id, user_id, content) VALUES(1, 1, 1, 'TEST11'), (2, 2, 2, 'TEST22'), (3, 3, 3, 'TEST33');
# Logic SQL: INSERT INTO t_order_item(item_id, order_id, user_id, content) VALUES(1, 1, 1, 'TEST11'), (2, 2, 2, 'TEST22'), (3, 3, 3, 'TEST33')
# Actual SQL: ds_0 ::: INSERT INTO t_order_item_0(item_id, order_id, user_id, content) VALUES(2, 2, 2, 'TEST22')
# Actual SQL: ds_1 ::: INSERT INTO t_order_item_1(item_id, order_id, user_id, content) VALUES(1, 1, 1, 'TEST11'), (3, 3, 3, 'TEST33')
INSERT INTO t_user(user_id, telephone) VALUES(1, '11111111111'), (2, '22222222222'), (3, '33333333333');
# Logic SQL: INSERT INTO t_user(user_id, telephone) VALUES(1, '11111111111'), (2, '22222222222'), (3, '33333333333')
# Actual SQL: ds_0 ::: INSERT INTO t_user(user_id, telephone_cipher, telephone_plain) VALUES(1, 'jFZBCI7G9ggRktThmMlClQ==', '11111111111'), (2, 'lWrg5gaes8eptaQkUM2wtA==', '22222222222'), (3, 'jeCwC7gXus4/1OflXeGW/w==', '33333333333')
We can then execute a few simple query statements to check if the read/write splitting function works. It can be seen in the log that thet_orderand t_order_item tables have been encrypted, decrypted, and rewritten, and they are routed to the correct slave database as well. However, the t_user table is still routed to the ds_0 data source for execution while the configured read-write splitting does not work. Why?
Because in the 4.1.1 GA version, read/write splitting and encryption & decryption are integrated into data sharding, naturally restricting functions except for sharding.
SELECT * FROM t_order WHERE user_id = 1 AND order_id = 1;
# Logic SQL: SELECT * FROM t_order WHERE user_id = 1 AND order_id = 1
# Actual SQL: ds_1_slave_0 ::: SELECT order_id, user_id, content_plain, content_cipher FROM t_order_1 WHERE user_id = 1 AND order_id = 1
SELECT * FROM t_order_item WHERE user_id = 1 AND order_id = 1;
# Logic SQL: SELECT * FROM t_order_item WHERE user_id = 1 AND order_id = 1
# Actual SQL: ds_1_slave_1 ::: SELECT * FROM t_order_item_1 WHERE user_id = 1 AND order_id = 1
SELECT * FROM t_user WHERE user_id = 1;
# Logic SQL: SELECT * FROM t_user WHERE user_id = 1
# Actual SQL: ds_0 ::: SELECT user_id, telephone_plain, telephone_cipher FROM t_user WHERE user_id = 1
The 5.0.0 GA version adopts a pluggable architecture and an upgraded kernel, to allow users to combine these functions without any restrictions. Additionally, in the new version, we delete defaultDataSourceNameso users don’t need additional configuration anymore. Now ShardingSphere implements single-table metadata loading and routing through SingleRuleby default. Let’s take a look at how to configure and use the function in the 5.0.0 GA version. The configuration code is shown below:
rules:
- !SHARDING
tables:
t_order:
actualDataNodes: ms_ds_${0..1}.t_order_${0..1}
tableStrategy:
standard:
shardingColumn: order_id
shardingAlgorithmName: t_order_inline
t_order_item:
actualDataNodes: ms_ds_${0..1}.t_order_item_${0..1}
tableStrategy:
standard:
shardingColumn: order_id
shardingAlgorithmName: t_order_item_inline
bindingTables:
- t_order,t_order_item
broadcastTables:
- t_config
defaultDatabaseStrategy:
standard:
shardingColumn: user_id
shardingAlgorithmName: database_inline
defaultTableStrategy:
none:
shardingAlgorithms:
database_inline:
type: INLINE
props:
algorithm-expression: ms_ds_${user_id % 2}
t_order_inline:
type: INLINE
props:
algorithm-expression: t_order_${order_id % 2}
t_order_item_inline:
type: INLINE
props:
algorithm-expression: t_order_item_${order_id % 2}
- !READWRITE_SPLITTING
dataSourceGroups:
ms_ds_0:
writeDataSourceName: ds_0
readDataSourceNames:
- ds_0_slave_0
- ds_0_slave_1
loadBalancerName: ROUND_ROBIN
ms_ds_1:
writeDataSourceName: ds_1
readDataSourceNames:
- ds_1_slave_0
- ds_1_slave_1
loadBalancerName: ROUND_ROBIN
- !ENCRYPT
encryptors:
aes_encryptor:
type: AES
props:
aes-key-value: 123456abc
tables:
t_order:
columns:
content:
cipherColumn: content_cipher
encryptor: aes_encryptor
t_user:
columns:
telephone:
cipherColumn: telephone_cipher
encryptor: aes_encryptor
The biggest configuration difference between the 5.0.0 GA version and the 4.1.1 GA version lies in the relationship between different functions. In the 5.0.0 version, their positions are parallel and independent unlike the functional dependency relation in 4.1.1 GA. Users can flexibly load or unload these pluggable features. When you use some functions together, the deployment is quite similar to a delivery pipeline.
For example, your read/write splitting rule is based on two sets of master-slave relationships, and then two logical data sources are aggregated, namelyms_ds_0 and ms_ds_1; then since your data sharding rule is based on the logical data sources aggregated by read/write splitting, your configured data sharding rule aggregates the logical table t_order; encryption/decryption function focuses on rewriting columns and values, and configures encryption and decryption rules for the logical table aggregated by the data sharding feature. The functions Read/write Splitting, Data Sharding, and Encryption and Decryption are transferred one by one, and at the same time, the functions are continuously added through the decoration mode.
To compare with the functions of the 4.1.1 GA version, we execute the same initialization statement, Insert Into statement, and Query statement to test the 5.0.0 GA version.
CREATE TABLE t_order(order_id INT(11) PRIMARY KEY, user_id INT(11), content VARCHAR(100));
# Logic SQL: CREATE TABLE t_order(order_id INT(11) PRIMARY KEY, user_id INT(11), content VARCHAR(100))
# Actual SQL: ds_1 ::: CREATE TABLE t_order_0(order_id INT(11) PRIMARY KEY, user_id INT(11), content_cipher VARCHAR(100), content_plain VARCHAR(100))
# Actual SQL: ds_1 ::: CREATE TABLE t_order_1(order_id INT(11) PRIMARY KEY, user_id INT(11), content_cipher VARCHAR(100), content_plain VARCHAR(100))
# Actual SQL: ds_0 ::: CREATE TABLE t_order_0(order_id INT(11) PRIMARY KEY, user_id INT(11), content_cipher VARCHAR(100), content_plain VARCHAR(100))
# Actual SQL: ds_0 ::: CREATE TABLE t_order_1(order_id INT(11) PRIMARY KEY, user_id INT(11), content_cipher VARCHAR(100), content_plain VARCHAR(100))
CREATE TABLE t_order_item(item_id INT(11) PRIMARY KEY, order_id INT(11), user_id INT(11), content VARCHAR(100));
# Logic SQL: CREATE TABLE t_order_item(item_id INT(11) PRIMARY KEY, order_id INT(11), user_id INT(11), content VARCHAR(100))
# Actual SQL: ds_1 ::: CREATE TABLE t_order_item_0(item_id INT(11) PRIMARY KEY, order_id INT(11), user_id INT(11), content VARCHAR(100))
# Actual SQL: ds_1 ::: CREATE TABLE t_order_item_1(item_id INT(11) PRIMARY KEY, order_id INT(11), user_id INT(11), content VARCHAR(100))
# Actual SQL: ds_0 ::: CREATE TABLE t_order_item_0(item_id INT(11) PRIMARY KEY, order_id INT(11), user_id INT(11), content VARCHAR(100))
# Actual SQL: ds_0 ::: CREATE TABLE t_order_item_1(item_id INT(11) PRIMARY KEY, order_id INT(11), user_id INT(11), content VARCHAR(100))
CREATE TABLE t_user(user_id INT(11) PRIMARY KEY, telephone VARCHAR(100));
# Logic SQL: CREATE TABLE t_user(user_id INT(11) PRIMARY KEY, telephone VARCHAR(100))
# Actual SQL: ds_1 ::: CREATE TABLE t_user(user_id INT(11) PRIMARY KEY, telephone_cipher VARCHAR(100), telephone_plain VARCHAR(100))
The 5.0.0 GA version supports rewriting encryption and decryption DDL statements, so when creating thet_order, , routing and rewriting in data sharding, read/write splitting, and encryption/decryption are performed well.
You can see in the log that thet_user table is routed to the ds_1 data source for execution. In the 5.0.0 GA version, although the t_user table is a single table, users do not need to configure the data source because when the table creation statement executes, ShardingSphere can randomly select a data source for routing. To ensure accurate routing results, we must ensure its uniqueness in the logic database.
INSERT INTO t_order(order_id, user_id, content) VALUES(1, 1, 'TEST11'), (2, 2, 'TEST22'), (3, 3, 'TEST33');
# Logic SQL: INSERT INTO t_order(order_id, user_id, content) VALUES(1, 1, 'TEST11'), (2, 2, 'TEST22'), (3, 3, 'TEST33')
# Actual SQL: ds_1 ::: INSERT INTO t_order_1(order_id, user_id, content_cipher, content_plain) VALUES(1, 1, '3qpLpG5z6AWjRX2sRKjW2g==', 'TEST11'), (3, 3, 'oVkQieUbS3l/85axrf5img==', 'TEST33')
# Actual SQL: ds_0 ::: INSERT INTO t_order_0(order_id, user_id, content_cipher, content_plain) VALUES(2, 2, 'mzIhTs2MD3dI4fqCc5nF/Q==', 'TEST22')
INSERT INTO t_order_item(item_id, order_id, user_id, content) VALUES(1, 1, 1, 'TEST11'), (2, 2, 2, 'TEST22'), (3, 3, 3, 'TEST33');
# Logic SQL: INSERT INTO t_order_item(item_id, order_id, user_id, content) VALUES(1, 1, 1, 'TEST11'), (2, 2, 2, 'TEST22'), (3, 3, 3, 'TEST33')
# Actual SQL: ds_1 ::: INSERT INTO t_order_item_1(item_id, order_id, user_id, content) VALUES(1, 1, 1, 'TEST11'), (3, 3, 3, 'TEST33')
# Actual SQL: ds_0 ::: INSERT INTO t_order_item_0(item_id, order_id, user_id, content) VALUES(2, 2, 2, 'TEST22')
INSERT INTO t_user(user_id, telephone) VALUES(1, '11111111111'), (2, '22222222222'), (3, '33333333333');
# Logic SQL: INSERT INTO t_user(user_id, telephone) VALUES(1, '11111111111'), (2, '22222222222'), (3, '33333333333')
# Actual SQL: ds_1 ::: INSERT INTO t_user(user_id, telephone_cipher, telephone_plain) VALUES(1, 'jFZBCI7G9ggRktThmMlClQ==', '11111111111'), (2, 'lWrg5gaes8eptaQkUM2wtA==', '22222222222'), (3, 'jeCwC7gXus4/1OflXeGW/w==', '33333333333')
When you insert data into the t_user table, automatic routing is performed according to the information stored in the metadata. For example, since t_user is routed to the ds_1 data source in the previous step, other statements will follow the metadata t_user: ds_1.
SELECT * FROM t_order WHERE user_id = 1 AND order_id = 1;
# Logic SQL: SELECT * FROM t_order WHERE user_id = 1 AND order_id = 1
# Actual SQL: ds_1_slave_0 ::: SELECT `t_order_1`.`order_id`, `t_order_1`.`user_id`, `t_order_1`.`content_cipher` AS `content` FROM t_order_1 WHERE user_id = 1 AND order_id = 1
SELECT * FROM t_order_item WHERE user_id = 1 AND order_id = 1;
# Logic SQL: SELECT * FROM t_order_item WHERE user_id = 1 AND order_id = 1
# Actual SQL: ds_1_slave_1 ::: SELECT * FROM t_order_item_1 WHERE user_id = 1 AND order_id = 1
SELECT * FROM t_user WHERE user_id = 1;
# Logic SQL: SELECT * FROM t_user WHERE user_id = 1
# Actual SQL: ds_1_slave_0 ::: SELECT `t_user`.`user_id`, `t_user`.`telephone_cipher` AS `telephone` FROM t_user WHERE user_id = 1
When we execute Query statements, we find that the t_user table is routed to the ds_1_slave_0 data source, which completes the read-write splitting of a single table. The Apache ShardingSphere 5.0.0 GA kernel can internally maintain data distribution information of a single table via metadata loading; we also fully consider the scenarios of different function combinations, making Apache ShardingSphere perfectly support operations on a single table.
Of course, there are more new features in the 5.0.0 GA version. In this upgrade guide, we only compare some features supported in the two GA versions. We hope this article can help you understand the new features and successfully implement the version upgrade. If you are interested, visit our repo, or please read our documentation and test the new version by yourself.
Conclusion
Having undergone two years of development, the new-look Apache ShardingSphere with its pluggable kernel gives all developers indefinite development possibilities. In the future, we will continue to develop more new features of the pluggable kernel to expand the Apache ShardingSphere ecosystem with amazing functions. The Federation Execution Engine is just the beginning of distributed queries. We will make more efforts to optimize its memory and performance, to provide you with more reliable and efficient distributed queries.
As always, you’re welcome to join us in developing the Apache ShardingSphere project.
References
-
Apache ShardingSphere Release Notes:https://github.com/apache/shardingsphere/releases
-
Brand new sharding configuration API of Release 5.x:https://github.com/apache/shardingsphere/issues/5017
-
Automatic Sharding Strategies for Databases and Tables:https://github.com/apache/shardingsphere/issues/5937
-
Contributor Guide:https://shardingsphere.apache.org/community/en/involved/
Open Source Project Links:
ShardingSphere Github: https://github.com/apache/shardingsphere
ShardingSphere Twitter: https://twitter.com/ShardingSphere
ShardingSphere Slack Channel:https://join.slack.com/t/apacheshardingsphere/shared_invite/zt-sbdde7ie-SjDqo9~I4rYcR18bq0SYTg
GitHub Issues: https://github.com/apache/shardingsphere/issues
Contributor Guide:https://shardingsphere.apache.org/community/cn/involved/
Author
Duan Zhengqiang

SphereEx Senior Middleware Development Engineer & Apache ShardingSphere Committer
He started contributing to Apache ShardingSphere middleware in 2018 and previously was an engineering lead at numerous data sharding projects. He loves open source and sharing his tech stories and experiences with others. He now devotes himself to developing the Apache ShardingSphere kernel module.