How to construct the distributed database
Author | Liang Zhang
Relational databases have dominated the database field for the past few decades, and the stability, security, and ease of use they bring have become the cornerstone for building modern systems. With the rapid development of the Internet, the database structured in a stand-alone system has been unable to meet the increasingly high concurrent requests and increasingly large data storage needs, therefore, distributed database are more widely adopted.
Historically, the database space has been dominated by Western technology companies and communities. Apache ShardingSphere is one of these distributed database solutions and is currently the only database middleware in the Apache Software Foundation.
1 Background
Fully compatible with SQL and transactions for traditional relational databases, and naturally friendly to distribution, is the design goal of distributed database solutions. Its core functions are mainly concentrated in the following points:
-
Distributed storage: Data storage is not limited by the disk capacity of a single machine, and the storage capacity can be improved by increasing the number of data servers;
-
Separation of computing and storage: Computing nodes are stateless and can increase computing power through horizontal expansion. Storage nodes and computing nodes can be optimized hierarchically;
-
Distributed transaction: A high-performance, distributed transaction processing engine that fully supports the original meaning of local transactions ACID;
-
Elastic scaling: You can dynamically expand and shrink data storage nodes anytime, anywhere without affecting existing applications;
-
Consensus replication: Automatically copy the data to multiple copies across data centers in a strong and consistent manner to ensure the absolute security of the data;
-
HTAP: The same set of products is used to mix transactional operations of OLTP and analytical operations of OLAP.
The implementation solutions of distributed database can be divided into aggressive and stable. The aggressive implementation solution refers to the development of a new architecture of NewSQL. Such products are focus on higher performance in exchange for the lack of stability and the lack of experience in operation and maintenance; the stable implementation solution refers to the middleware that provides incremental capabilities based on the existing database. Such products sacrifice some performance to ensure the stability of the database and reuse of operation and maintenance experience.
2 Architecture
Apache ShardingSphere is an open source ecosystem distributed database solutions, consisting of three separate products, Sharding-JDBC, Sharding-Proxy, and Sharding-Sidecar (planned). They all provide functions of data scale out, distributed transaction and distributed governance for a variety of diverse application scenarios such as Java Isomorphic, heterogeneous languages, and cloud-native. As Apache ShardingSphere continues to explore query optimizers and distributed transaction engines, it has gradually broken the product boundaries of implementations and evolved into a platform-level solution that is both aggressive and stable all in one.
Sharding-JDBC
Defines itself as a lightweight Java framework that provides extra service at Java JDBC layer. With the client end connecting directly to the database, it provides service in the form of jar and requires no extra deployment and dependence. It can be considered as an enhanced JDBC driver, which is fully compatible with JDBC and all kinds of ORM frameworks.
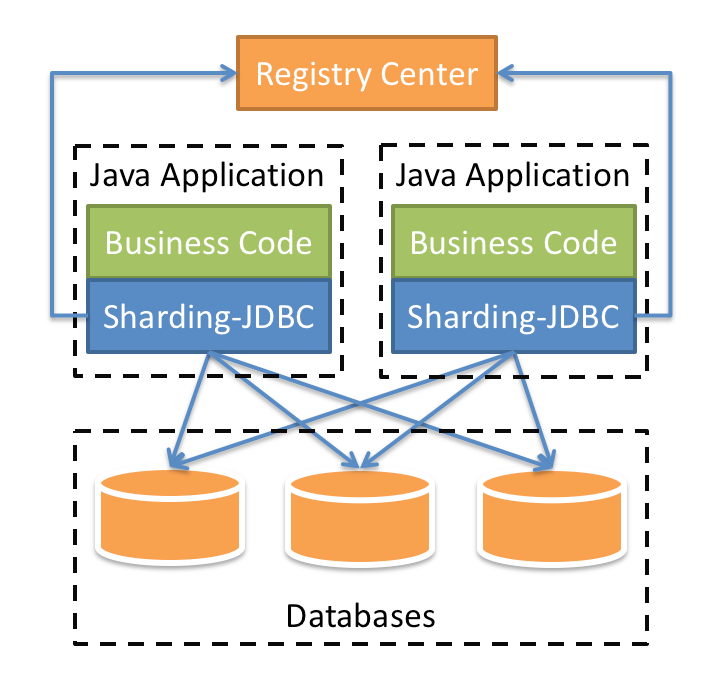
Sharding-Proxy
Defines itself as a transparent database proxy, providing a database server that encapsulates database binary protocol to support heterogeneous languages. Friendlier to DBA, the MySQL/PostgreSQL version provided now can use any kind of client access (such as MySQL Command Client, MySQL Workbench, Navicat etc.) that is compatible of MySQL/PostgreSQL protocol to operate data.
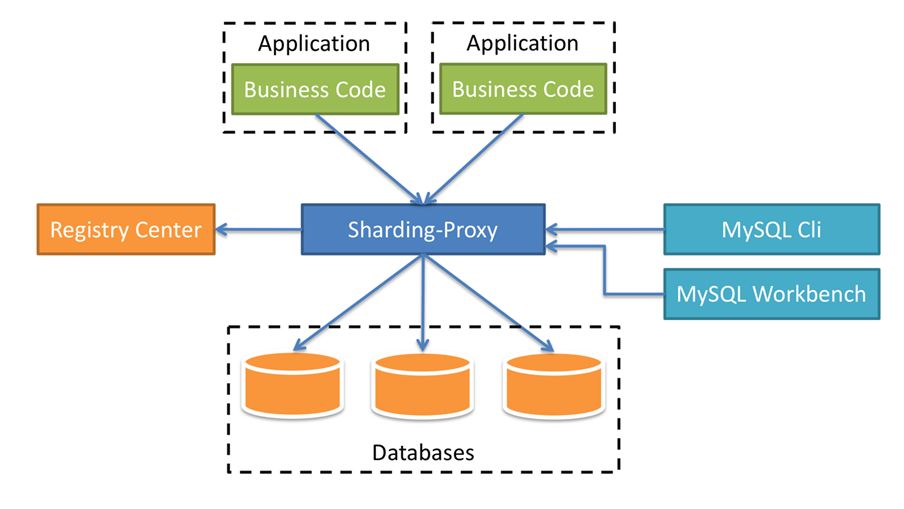
Sharding-Sidecar (Planned)
Defines itself as a cloud native database agent of the Kubernetes environment, in charge of all the access to the database in the form of sidecar. It provides a mesh layer interacting with the database, we call this as Database Mesh.
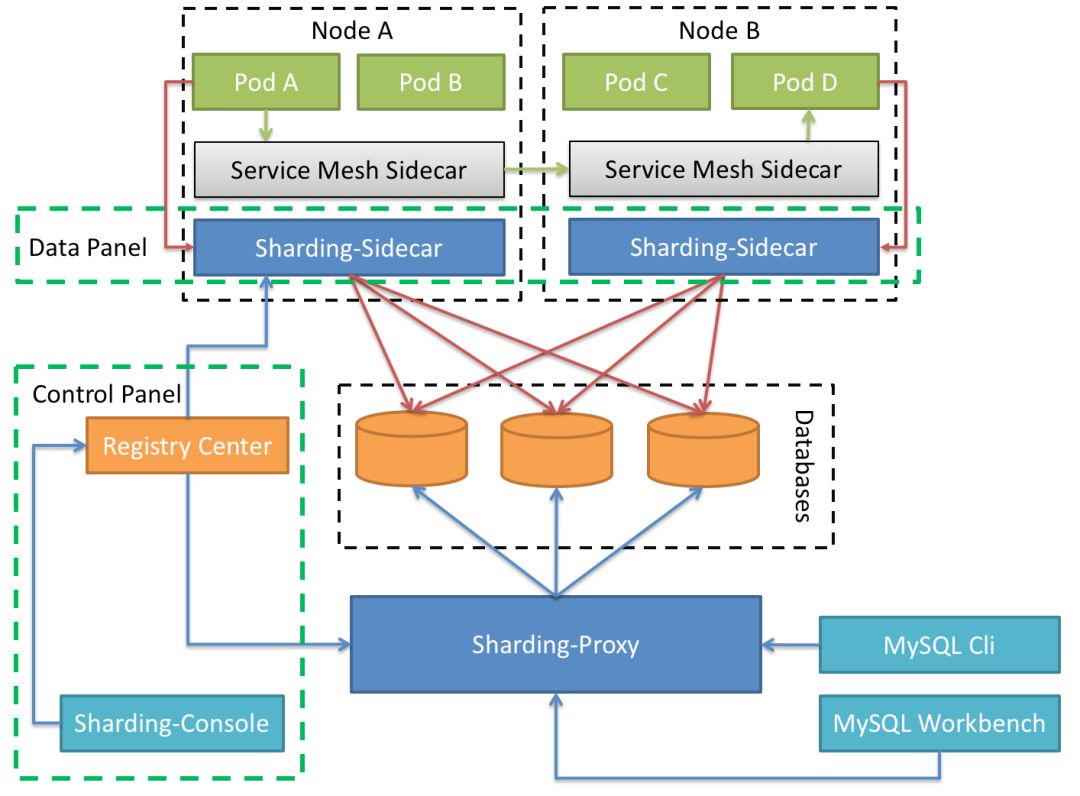
Hybrid architecture with separate computing and storage
ShardingSphere-JDBC adopts decentralized architecture, applicable to high-performance light-weight OLTP application developed with Java; ShardingSphere-Proxy provides static entry and all languages support, applicable for OLAP application and the sharding databases management and operation situation.
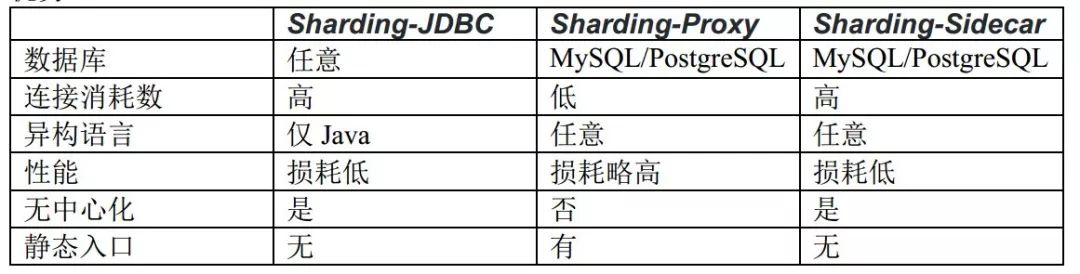
Each architecture solution has its own advantages and disadvantages. The following table compares the advantages and disadvantages of various architecture models in different scenarios:
Apache ShardingSphere is an ecosystem composed of multiple access points. By mixing Sharding-JDBC and Sharding-Proxy, and using the same configuration center to configure the sharding strategy uniformly, it is possible to flexibly build application systems suitable for various scenarios, allowing architects to freely adjust the best system suitable for the current business Architecture.
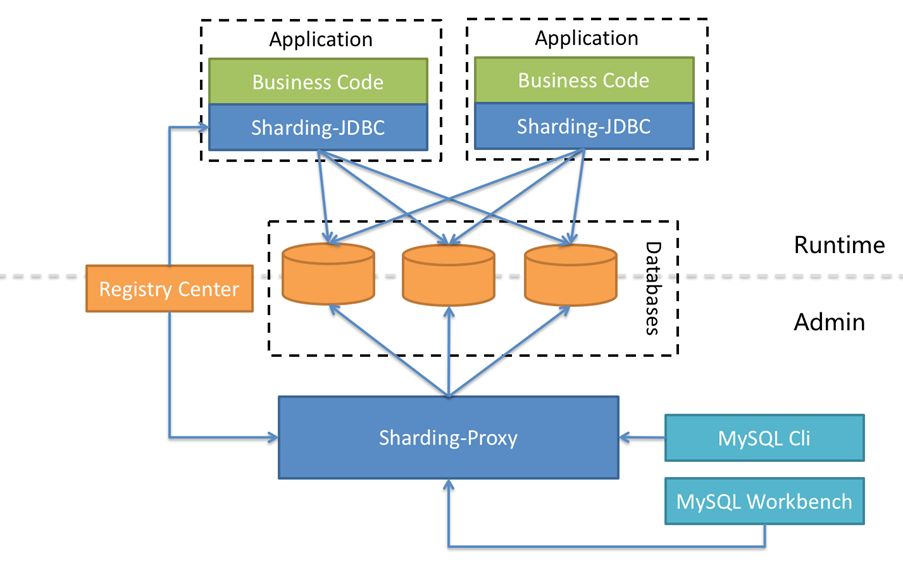
Apache ShardingSphere adopts Share Nothing architecture, and its JDBC and Proxy access endpoints both adopt a stateless design. As a computing node, Apache ShardingSphere is responsible for the final calculation and summary of the acquired data. Since it does not store data itself, Apache ShardingSphere can push the calculation down to the data node to take full advantage of the database’s own computing power. Apache ShardingSphere can increase the computing power by increasing the number of deployed nodes; increase the storage capacity by increasing the number of database nodes.
3 Core functions
Data sharding, distributed transactions, elastic scaling, and distributed governance are the four core functions of Apache ShardingSphere at the current stage.
Data sharding
Divide and governance is the solution used by Apache ShardingSphere to process big data. Apache ShardingSphere enables distributed storage capabilities in databases through data sharding solutions.
It can automatically route SQL to the corresponding data node according to the user’s configured sharding algorithm to achieve the purpose of operating multiple databases. Users can use multiple databases managed by Apache ShardingSphere like a stand-alone database. Currently supports MySQL, PostgreSQL, Oracle, SQLServer and any database that supports SQL92 standard and JDBC standard protocol. The core flow of data sharding is shown in the figure below:
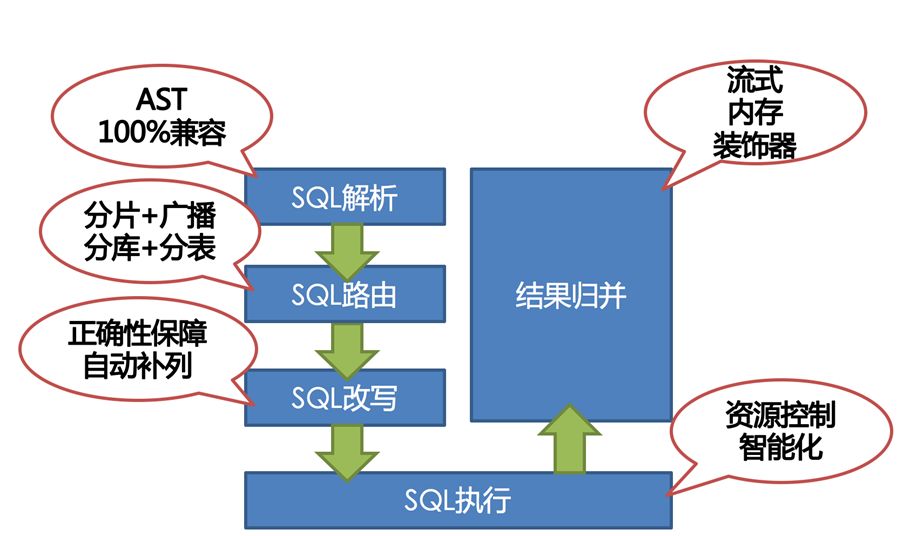
The main process is as follows:
-
Obtain the SQL and parameters input by the user by parsing the database protocol package or JDBC driver;
-
Parse SQL into AST (Abstract Syntax Tree) according to lexical analyzer and grammar analyzer, and extract the information required for sharding;
-
Match the shard key according to the user configured algorithm and calculate the routing path;
-
Rewrite SQL as distributed executable SQL;
-
Send SQL to each data node in parallel, the execution engine is responsible for balancing the connection pool and memory resources;
-
Perform streaming or full memory result set merge calculation according to AST;
-
Encapsulate the database protocol package or JDBC result set, and return to the client.
Distributed transaction
Transaction is the core function of the database system. Distributed uncertainty and transaction complexity determine that there is no standard solution in the field of distributed transactions.
Facing the current situation, Apache ShardingSphere provides a highly open solution that uses standard interfaces to unify and integrate third-party distributed transaction frameworks independently selected by developers to meet the application requirements of various scenarios. In addition, Apache ShardingSphere also provides a new distributed transaction solution JDTX to make up for the lack of existing solutions.
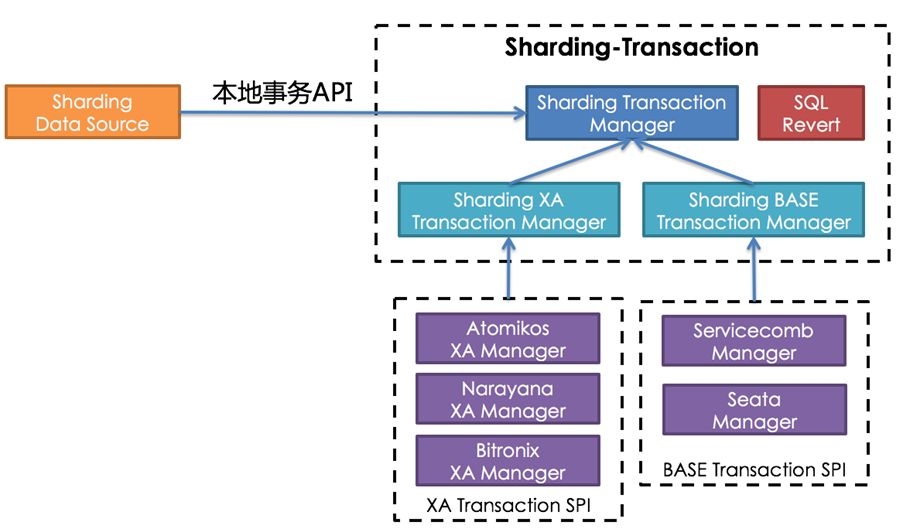
Standardized integrated interface
Apache ShardingSphere provides a unified adaptation interface for local transactions, two-phase transactions, and BASE transactions, and docks with a large number of existing third-party mature solutions. Through the standard interface, developers can easily integrate other integration solutions into the Apache ShardingSphere platform.
However, the integration of a large number of third-party solutions cannot cover all branches of distributed transaction requirements. Each solution has its own suitable and unsuitable scenarios. The solutions are mutually exclusive, and their advantages cannot be used together. For the most common 2PC (two-phase commit) and BASE transactions, there are the following advantages and disadvantages:
-
Two-phase commit: The two-phase distributed transaction based on the XA protocol incurs little business intrusion. Its biggest advantage is that it is transparent to the user. Developers can use distributed transactions based on the XA protocol like local transactions. The XA protocol can strictly guarantee the ACID characteristics of transactions, but it is also a double-edged sword. In the process of transaction execution, all required resources need to be locked, which is more suitable for short transactions whose execution time is determined. For long transactions, the exclusive use of resources during the entire transaction will cause the concurrency performance of business systems that rely on hot data to decline significantly. Therefore, in high-concurrency performance-oriented scenarios, distributed transactions based on the XA protocol two-phase commit type are not the best choice.
-
BASE transaction: If the transaction that implements the transaction element of ACID is called a rigid transaction, the transaction based on the BASE transaction element is called a BASE transaction. BASE is an abbreviation of the three elements of basic availability, flexible state and final consistency. In ACID transactions, the requirements for consistency and isolation are very high. During the execution of the transaction, all resources must be occupied. The idea of BASE transactions is to move the mutex operation from the resource level to the business level through business logic. By relaxing the requirements for strong consistency and isolation, only when the entire transaction ends, the data is consistent. During the execution of the transaction, any data obtained by the read operation may be changed. This weak consistency design can be used in exchange for system throughput improvement.
Both ACID-based two-phase transactions and BASE-based final consistency transactions are not silver bullets, and the differences between them can be compared in detail through the following table.
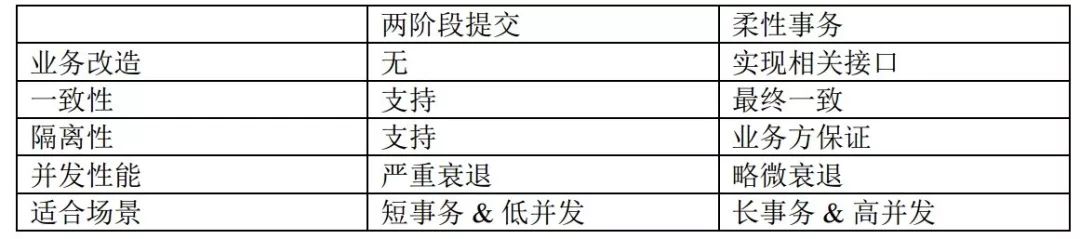
A two-phase transaction that lacks concurrency guarantee cannot be called a perfect distributed transaction solution; a BASE transaction that lacks the original support of ACID cannot even be called a database transaction, which is more suitable for service layer transaction processing.
At present, it is difficult to find a distributed transaction solution that can be used universally without trade-offs.
A new generation of distributed transaction middleware JDTX
JDTX is a self-developed distributed transaction middleware by JD.com, which has not yet been open sourced. Its design goals are strongly consistent (supporting ACID’s transaction meaning), high performance (not less than local transaction performance), 1PC (completely abandoning two-phase commit and two-phase lock) fully distributed transaction middleware, currently available for Relational Database. It adopts a completely open SPI design method to provide the possibility of interfacing with NoSQL, and can maintain multiple heterogeneous data in the same transaction in the future.
JDTX uses a fully self-developed transaction processing engine to convert data in SQL operations into KV (key-value pairs), and on the basis of it, implements the MVCC (multi-version snapshot) transaction visibility engine and the database design concept. Similar WAL (Write-ahead Logging System) storage engine. You can understand the composition of JDTX through the following architecture diagram:
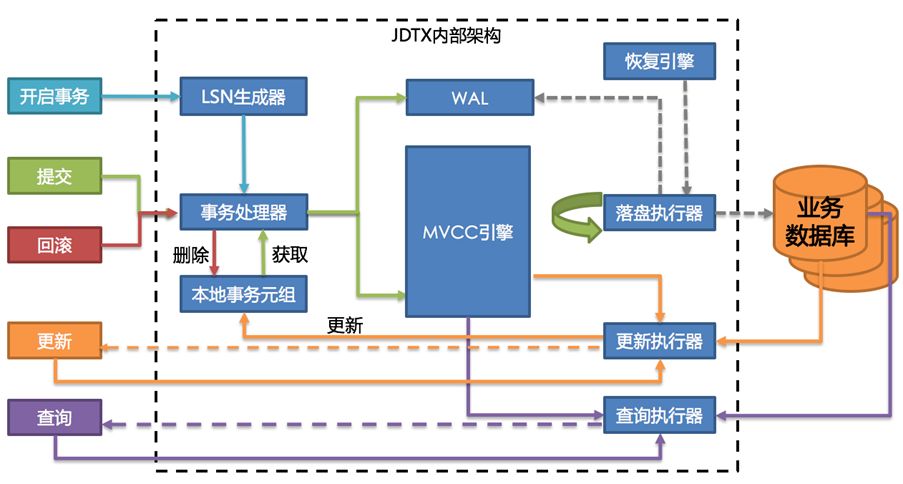
Its design feature is to separate the data in the transaction (called active data) from the data that is not in the transaction (called placement data). After the active data is placed on the WAL, it is saved in the form of KV to the MVCC memory engine. Placed data is synchronized to the final storage medium (such as a relational database) by asynchronously flashing the REDO logs in WAL in a flow controllable manner. The transactional memory query engine is responsible for retrieving relevant data from the active data in KV format using SQL, merging it with the data on the market, and obtaining the data version that is visible to the current transaction according to the transaction isolation level.
JDTX reinterprets the database transaction model with a new architecture. The main highlights are:
1. Convert distributed transactions to local one
JDTX’s MVCC engine is a centralized cache. It can internalize the two-phase commit to the one-phase commit to maintain the atomicity and consistency of the data in a single node, that is, reduce the scope of distributed transactions to the scope of local transactions. JDTX guarantees the atomicity and consistency of transaction data by ensuring that all access to transaction data passes through the active data of the MVCC engine + the final data-end data combination.
2. Fully support all transaction isolation levels
Implementing transaction isolation in the way of MVCC. At present, it fully supports the read and repeatable reads in the four standard isolation levels, which can already meet most of the needs.
3. High performance
The method of asynchronously flashing active data to the storage medium greatly improves the upper limit of data writing performance. Its performance bottleneck has shifted from the time of writing to the database to the time of placing it to WAL and MVCC engine.
Similar to the WAL system of the database, the WAL of JDTX also adopts the way of sequential log appending, so it can be simply understood that the time-consuming WAL of JDTX = the time-consuming WAL of the database system. The MVCC engine uses a KV data structure, which takes less time to write than a database that maintains BTree indexes. Therefore, the upper limit of the data update performance of JDTX can even be higher than that of no transaction.
4. High availability
Both WAL and MVCC engines can maintain high availability and horizontal scalability through active and standby and sharding. When the MVCC engine is completely unavailable, the data in WAL can be synchronized to the database through the recovery mode to ensure the integrity of the data.
5. Support transactions between different databases
The design scheme of separating transaction active data and order placement data makes its placement data storage end without any restrictions. Since the transaction active data is stored in the back-end storage medium through the asynchronous drop-off executor, whether the back-end is a homogeneous database has no effect. Using JDTX can ensure that distributed transactions across multiple storage ends (such as MySQL, PostgreSQL, and even MongoDB, Redis, and NoSQL) are maintained within the same transaction semantics.
Through the distributed transaction unified adaptation interface provided by Apache ShardingSphere, JDTX can be easily integrated into the Apache ShardingSphere ecosystem like other third-party distributed transaction solutions, seamlessly combining data sharding and distributed transactions, so that they have composition distribution The capacity of a distributed database infrastructure. The Apache ShardingSphere at the forefront of the product is used for SQL parsing, database protocols, and data sharding; the JDTX at the middle layer is used to process transactional active data through KV and MVCC; the bottom-most database is only used as the final data storage end. The following figure is the architecture diagram of ShardingSphere + JDTX.
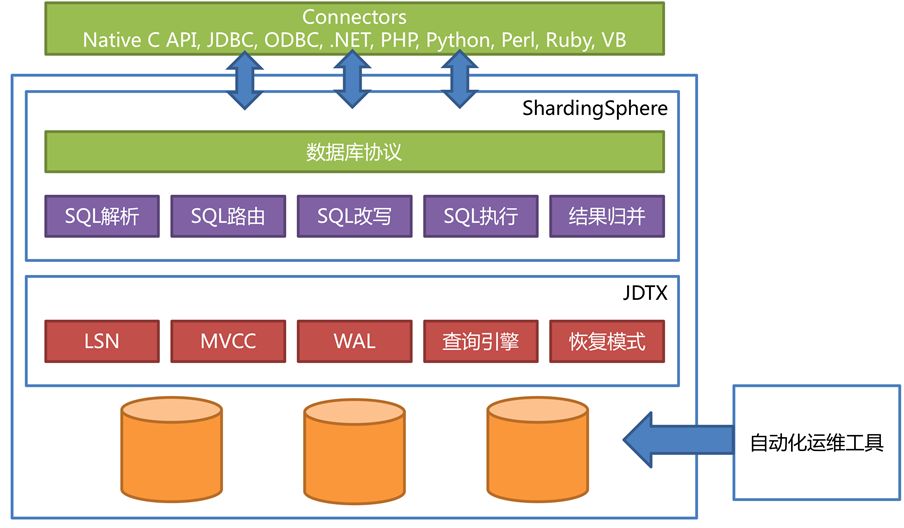
It can be said that the existence of JDTX has made Apache ShardingSphere break the position of stable database middleware, while maintaining stability, and gradually developing towards aggressive NewSQL.
Elastic Scaling
Unlike stateless service-based applications, data nodes hold important user data that cannot be lost. When the capacity of the data node is not enough to bear the rapidly growing business, the expansion of the data node is inevitable. According to the different sharding strategies configured by the user, the expansion strategy will also be different.
Elastic scaling allows the database managed by Apache ShardingSphere to expand and contract without stopping external services. Elastic scaling is divided into two components, elastic migration and range expansion, which are currently incubating.
Elastic migration
Data migration is a standard expansion and reduction solution for users to customize sharding strategies. During the migration process, two sets of data nodes need to be prepared. While continuing to provide services, the original data node writes the data to the new data node in the form of stock and increment. The entire migration process does not need to stop external services, you can smoothly transition the old and new data nodes. Apache ShardingSphere will also provide a workflow interface, allowing the migration process to be fully autonomous and controllable. The architecture diagram of flexible migration is as follows:
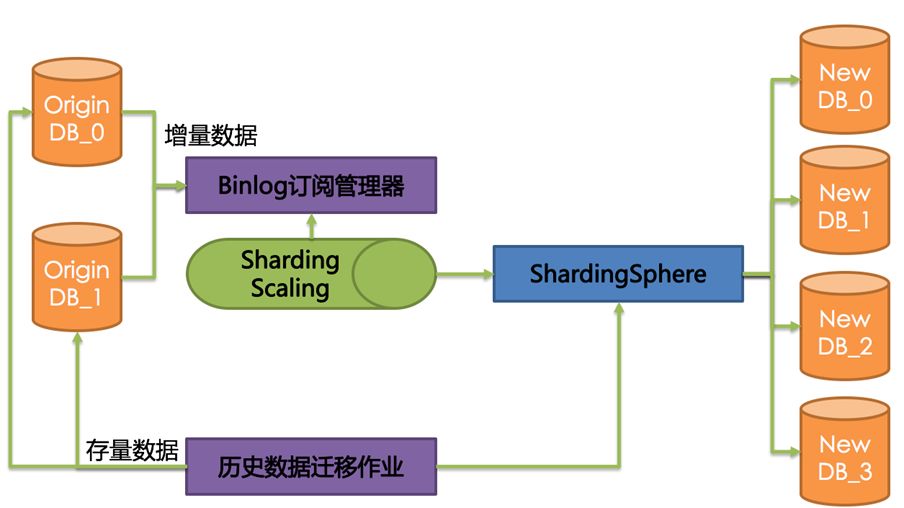
The specific process is as follows:
-
Modify the data sharding configuration through the configuration center to trigger the migration process.
-
After recording the location before the current migration data is turned on, start the historical migration operation and migrate the entire amount of data in batches.
-
Open the Binlog subscription job and migrate the incremental data after the site.
-
Set the comparison data according to the sampling rate.
-
Set the original data source to be read-only to ensure the completion of real-time data migration.
-
Switch the application connection to the new data source.
-
The old data source goes offline.
The time of migration may vary from a few minutes to several weeks depending on the amount of data. You can roll back or re-migrate at any time during the migration process. The entire migration process is completely autonomous and controllable, reducing the risks during the migration process; and through manual tools to completely shield manual operations, to avoid the huge workload caused by cumbersome operations.
Range expansion
If elastic migration is called hard scaling, then range expansion is called soft scaling. The scope expansion of Apache ShardingSphere does not involve kernel transformation and data migration. It only needs to optimize the scope sharding strategy to achieve the goal of automatic expansion (shrinkage). With scope expansion, users do not need to be aware of the necessary concepts in the sharding strategy and sharding key and other database partitioning schemes, making Apache ShardingSphere closer to an integrated distributed database.
Range expansion users only need to provide a database resource pool to Apache ShardingSphere. The capacity inspector will look for the next data node in order from the resource pool when the table capacity reaches the threshold, and modify the range metadata of the sharding strategy after the new data node creates a new table. When there are no new data nodes in the resource pool, Apache ShardingSphere will add new tables to the database that has already created tables in the same order. When a large amount of table data is deleted, the data of the previous data node will no longer be compact, and the garbage collector will periodically compress the table range to free up more fragmented space. The structure of scope expansion is as follows:
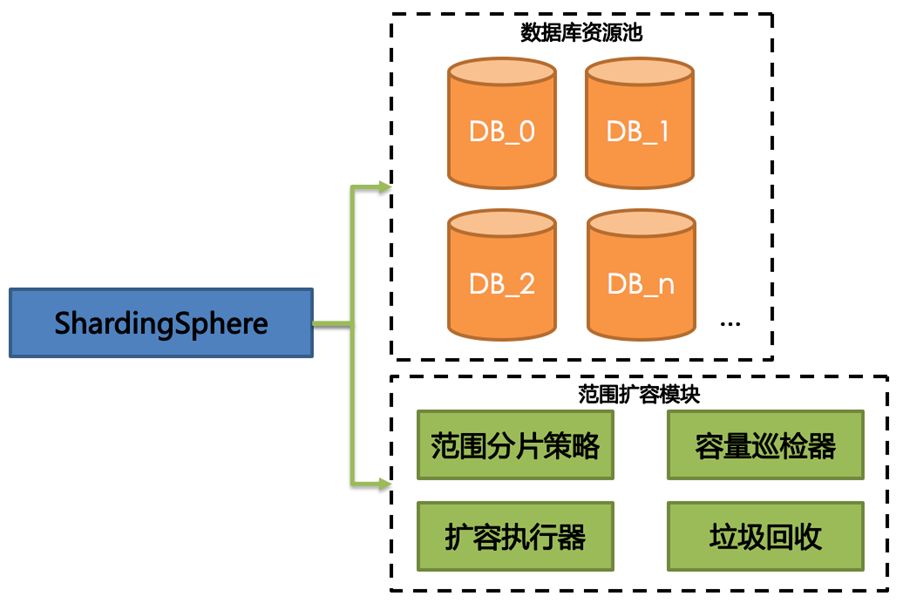
Apache ShardingSphere provides a more flexible elastic scaling strategy for different application scenarios. Two projects related to elastic scaling that are still incubating are also striving to provide trial versions as soon as possible.
Distributed governance
The design goal of the governance module is to better manage and use distributed databases.
Database governance
In line with the design philosophy of all distributed systems, divide and governance is also a guideline for distributed databases. The existence of database governance capabilities can prevent management costs from increasing with the number of database instances.
Dynamic configuration
Apache ShardingSphere uses the configuration center to manage the configuration, which can be propagated to all access-end instances in a very short time after the configuration is modified. The configuration center adopts the open SPI method, which can make full use of the configuration center’s own capabilities, such as configuration multi-version changes.
High availability
Apache ShardingSphere uses a registry to manage the running state of the access point instances and database instances. The registration center also uses the open SPI method of the configuration center. The realization of some registration centers can cover the capabilities of the configuration center, so users can use the capabilities of the registration center and the configuration center in a stack.
Apache ShardingSphere provides the ability to disable the database instance and fuse the access end, respectively, to deal with scenarios where the database instance is unavailable and the access end is hit by heavy traffic.
Apache ShardingSphere is currently incubating highly available SPI, allowing users to reuse the highly available solutions provided by the database itself. The MGR high availability solution for MySQL is currently being connected. Apache ShardingSphere can automatically detect MGR election changes and quickly propagate them to all application instances.
Observability
A large number of database and access-end instances make DBA and operation and maintenance personnel unable to quickly perceive the current system status. Apache ShardingSphere implements the OpenTracing protocol to send monitoring data to a third-party APM system that implements its protocol; in addition, Apache ShardingSphere also provides automated probes for Apache SkyWalking, which allows it to be used as an observable product Of users directly observed the performance of Apache ShardingSphere, the call chain relationship and the overall topology of the system.
Data governance
Thanks to Apache ShardingSphere’s flexible processing capabilities for SQL and high compatibility with database protocols, data-related governance capabilities are also easily added to the product ecosystem.
Desensitization
Apache ShardingSphere allows users to automatically encrypt the specified data column and store it in the database without modifying the code, and decrypt it when the application obtains the data to ensure the security of the data. When the data in the database is leaked inadvertently, the sensitive data information is completely encrypted, so it will not cause greater security risks.
Shadow Schema Table
Apache ShardingSphere can automatically route user-marked data to the shadow schema (table) when the system performs a full link pressure test. The shadow schema (table) pressure measurement function can make online pressure measurement a normal state, and users do not need to care about the cleaning of pressure measurement data. This function is also under high-speed incubation.
4 Roadmap
As you can see, Apache ShardingSphere is on the track of rapid development, and more and more functions that have no strong relationship with the “sub-database and sub-table” were added to it. But the functions of these products are not obtrusive, but they can help Apache ShardingSphere become a more diversified distributed database solution. Apache ShardingSphere will focus on the following lines in the future.
Pluggable platform
More and more scattered functions need to be further sorted out. The existing architecture of Apache ShardingSphere is not enough to fully absorb such a wide range of product functions. The flexible functional pluggable platform is the adjustment direction of Apache ShardingSphere’s future architecture.
The pluggable platform completely disassembles Apache ShardingSphere from both technical and functional aspects. The landscape of Apache ShardingSphere is as follows:
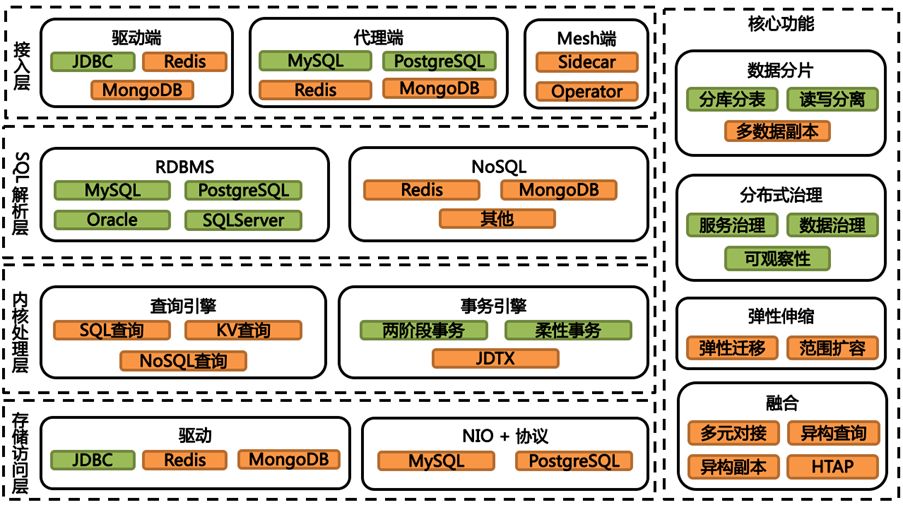
Apache ShardingSphere will be horizontally divided into 4 layers according to the technical architecture, namely the access layer, SQL parsing layer, kernel processing layer and storage access layer; and the functions will be integrated into the 4-layer architecture in a pluggable form.
Apache ShardingSphere’s support for database types will be completely open. In addition to relational databases, NoSQL will also be fully open. The database dialects do not affect each other and are completely decoupled. In terms of functions, Apache ShardingSphere uses a superimposed architecture model, so that various functions can be flexibly combined. Each functional module only needs to pay attention to its own core functions, and the Apache ShardingSphere architecture is responsible for the superposition and combination of functions. Even if there is no function, Apache ShardingSphere can be directly started as a blank access terminal, providing developers with customized development of infrastructure such as scaffolding and SQL parsing. The database integrated into the Apache ShardingSphere ecosystem will directly obtain all the basic capabilities provided by the platform; the functions developed on the Apache ShardingSphere platform will also directly receive all the support of the database types that have been connected to the platform. The database type and function type will be arranged and combined in a multiplied manner. The combination of infrastructure and Lego will provide Apache ShardingSphere with various imagination and improvement spaces.
Query optimizer
At present, Apache ShardingSphere only distributes SQL to the corresponding database through correct routing and rewriting to manipulate the data. The query optimizer that calculates and issues the database that can be fully utilized, but cannot effectively support complex related queries and subqueries. The SQL on KV query optimizer based on relational algebra has become mature with the development of JDTX, and its accumulated experience is fed back to the SQL query optimizer, which can enable Apache ShardingSphere to better support complex queries such as subqueries and cross-database related queries.
Consensus replication
The multiple data copy capabilities required by distributed databases are not currently available in Apache ShardingSphere. In the future, Apache ShardingSphere will provide multi-copy write capability based on Raft.
Database Mesh
The Sharding-Sidecar access point mentioned above is the third access point form of Apache ShardingSphere in the future, and aims to better cooperate with Kubernetes to create a cloud-native database.
The focus of Database Mesh is how to organically connect distributed data access applications and databases. It is more concerned with interactions, which is to effectively sort out the interaction between messy applications and databases. With Database Mesh, applications and databases that access the database will eventually form a huge grid system. Applications and databases only need to be seated in the grid system, and they are all managed by the meshing layer.
Data Federation
After supporting more database types, Apache ShardingSphere will focus on the unified query optimizer of multiple and heterogeneous database types. In addition, Apache ShardingSphere will also cooperate with JDTX to incorporate more diverse data storage media into the same transaction.
5 Open source and community
Apache ShardingSphere was first open sourced on the GitHub platform on January 17, 2016. The original name of the open source project was Sharding-JDBC. On November 10, 2018, ShardingSphere changed its name and officially entered the Apache Software Foundation incubator.
In the four years that open source has traveled, the architectural model of Apache ShardingSphere is constantly evolving, and the range of functions of the overall product is rapidly expanding. It has gradually evolved into a distributed database solution from the Java development framework of sub-database and sub-table at the beginning of open source.
With the expansion of the Apache ShardingSphere ecosystem, the status of the project controlled by a few developers has long been broken. The current Apache ShardingSphere has nearly one hundred contributors and nearly 20 core committers, who have jointly created this community that follows the Apache Way. Apache ShardingSphere is a standard Apache Software Foundation open source project and is not controlled by a commercial company or a few core developers.
At present, more than 100 companies have clearly stated that they are using Apache ShardingSphere, and readers can find the user wall that adopts the company from the official website.
As the community matures, Apache ShardingSphere grows faster and faster. We sincerely invite interested developers to participate in the Apache ShardingSphere community to improve the expanding ecosystem.
project address:
https://github.com/apache/shardingsphere
6 About the author
Zhang Liang, head of data research and development at JD.com, initiator of Apache ShardingSphere & PMC, head of JDTX.
Love open source, leading open source projects ShardingSphere (formerly known as Sharding-JDBC) and Elastic-Job. Good at using java as the main distributed architecture, admiring elegant code, and having more research on how to write expressive code.
At present, the main energy is invested in making ShardingSphere and JDTX into the industry’s first-class financial data solutions. ShardingSphere has entered the Apache incubator. It is the first open source project of the JingDong Group to enter the Apache Foundation and the first distributed database middleware of the Apache Foundation.