Executor Engine: Performance Optimization Showcase with Apache ShardingSphere 5.1.0
Our community’s previous two blog posts about the SQL Format function and High Availability (HA) introduced a comprehensive overview of Apache ShardingSphere’s updates.
Apart from many new practical features, we also have been optimizing overall performance. In this post, our community author is going to showcase with specific SQL examples how Apache ShardingSphere’s Executor Engine performance is greatly optimized.
In this post, our community author is going to showcase with specific SQL examples how Apache ShardingSphere’s Executor Engine performance is greatly optimized.
Problem
Take the t_order table with 10 shards in a database as an example and max-connections-size-per-query uses the default configuration 1.
If the user executes the SELECT * FROM t_order statement, it will result in full routing. Since only one database connection is allowed to be created on the same database for each query, the underlying actual SQL results will be loaded in advance into memory for processing. This scenario not only imposes a restriction on database connection resource consumption but also occupies more memory resources.
However, if the user adjusts the value of max-connections-size-per-query to 10, then ten database connections can be created while executing actual SQL. Since database connections can hold result sets, no additional memory resources are occupied in this scenario. Yet, this method requires more database connection resources.
In order to better solve the issue, we optimized the performance of SQL Executor Engine in the just-released 5.1.0 version: SQL Rewriter Engine now supports optimization-oriented rewriting, which means multiple real SQL statements on the same data source can be merged through the UNION ALL statement.
The updates effectively reduce the consumed database connection resources in the Executor Engine and avoid occurrent memory merging, further improving SQL query performance in Online Transaction Processing (OLTP) scenarios.
What’s the Mechanism of Apache ShardingSphere Executor Engine?
First, it’s better to review Apache ShardingSphere’s microkernel and the principle that explains how the Executor Engine works in the processes. As shown in the figure below, the Apache ShardingSphere microkernel includes core processes: SQL Parser, SQL Router, SQL Rewriter, SQL Executor, and Result Merger.
SQL Parser Engine can parse the SQL statements entered by the user and generate SQL Statements containing contextual information.
SQL Router Engine then extracts the sharding conditions according to the context, combines the sharding rules configured by the user to calculate the data source that the actual SQL needs for execution, and then generates routing results.
SQL Rewriter Engine rewrites the original SQL according to the results returned by SQL Router Engine. There are two rewrite types, correctness-oriented and optimization-oriented.
SQL Executor Engine can safely and efficiently send the SQL returned by SQL Router and Rewriter to the underlying data source for execution.
The result set will eventually be processed by Merger Engine, which can generate and return a unified result set to the user.
From the execution process, it is clear that the SQL executor engine can directly interact with the underlying database and hold the executed result set. Since the performance and resource consumption of the entire Apache ShardingSphere is attributed to those of the Executor Engine, the community decided to adopt an automatic SQL executor engine to balance execution performance and resource consumption.
In terms of execution performance, assigning an independent database connection to the execution statement of each shard can make full use of multi-threading to improve execution performance, and also process I/O consumption in parallel.
In addition, this method can also help avoid prematurely loading the query result set into memory. The independent database connection can hold a reference to the cursor position of the query result set and thus when it’s necessary to get the data, the user only needs to move the cursor.
When it comes to resource management, the number of connections for business access to the database should be limited to prevent a business from occupying too many database connection resources and further affecting the normal data access of other businesses. When there are many table shards in a database instance, a virtual SQL statement without a sharding key can generate a large number of actual SQL statements placed in different tables of the same database. If each actual SQL occupies an independent connection, then a single query will undoubtedly occupy too many resources.
In order to solve the conflict between execution performance and resource control, Apache ShardingSphere proposes the concept of Connection Mode. Here is the definition of Connection Mode in the source code.
/**
* Connection Mode.
*/
public enum ConnectionMode {
MEMORY_STRICTLY, CONNECTION_STRICTLY
}
Based on the member names in the Connection Mode enumeration class, we can see that the SQL Executor Engine divides database connection into two modes: MEMORY_STRICTLY and CONNECTION_STRICTLY.
-
MEMORY_STRICTLYis the memory limit mode. When the user chooses the mode, for example for the same data source, if a virtual table corresponds to 10 real tables, the SQL Executor Engine will create 10 connections for execution in parallel. Since all result sets of shards are held by their connections, there is no need to load the result sets into memory in advance, thus effectively reducing memory usage; -
CONNECTION_STRICTLYis used to limit connections. When the connection limit mode is used, the SQL Executor Engine will only create one connection on a data source to strictly control the consumption of database connection resources. However, the result set is loaded into memory right after the real SQL is executed, so it will occupy some memory space.
How does the Apache ShardingSphere SQL executor engine help the user choose an appropriate connection mode? The principle behind it is shown in the figure below:
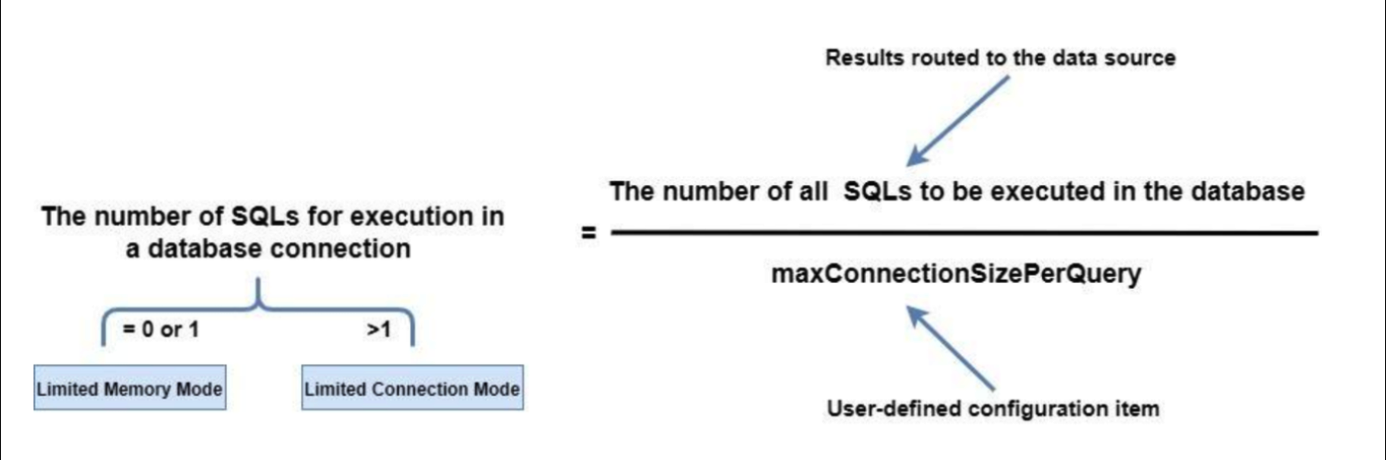
Users can specify the maximum connections allowed on the same data source for each statement by configuring maxConnectionSizePerQuery. According to the calculation formula above, when the number of SQL statements to be executed by each database connection is less than or equal to 1, each actual SQL statement is allocated an independent database connection. At this time, the memory limit mode will be selected and a database source allows the creation of multiple database connections for parallel execution. Otherwise, the connection limit mode will be selected and the same data source only allows the creation of one database connection for execution, and then load the result set into the memory result set, and then provide it to Merger Engine.
What is Optimized?
According to the mechanism mentioned above, when the user chooses the memory limit mode, more database connections will be consumed, but better performance can be obtained due to concurrent execution. With the connection limit mode, users can effectively control the connection resources, although there is too much-occupied memory and the execution performance will be less satisfying.
So, is it possible to use as few database connections and memory as possible for execution?
It’s obvious that the main factor in selecting an execution mode is the number of routing results on the same data source. Therefore, the most direct optimization is to merge the routing results on the same data source. SQL statements support merging multiple query statements through UNION ALL, so we use UNION ALL as an optimization method: multiple real SQL statements in the same data source are rewritten into one SQL statement, which is an optimization-oriented rewriting. The method can greatly reduce the acquisition of database connections, and can also convert memory result sets into streaming ones to reduce memory usage.
Considering that different database dialects have restrictions on the UNION ALL statement, we need to analyze the documents of MySQL, PostgreSQL, Oracle, and SQL Server, and then we get the following information:
MySQL: UNION ALL
For MySQL, the tips for using UNION ALL include:
-
Column names after
UNIONshall use the column name of the firstSELECTstatement. -
When a
UNIONstatement containsORDER BYandLIMIT, the user needs to use parentheses to enclose each query statement. SinceUNIONcannot guarantee the correct order of the final result sets. If you need to sort theUNIONresult set, it’s required to add theORDER BY LIMITclause at the end of theUNIONstatement.
# The UNION result set order is not guaranteed
(SELECT a FROM t1 WHERE a=10 AND B=1 ORDER BY a LIMIT 10) UNION (SELECT a FROM t2 WHERE a=11 AND B=2 ORDER BY a LIMIT 10);
# The UNION result set order is guaranteed
(SELECT a FROM t1 WHERE a=10 AND B=1) UNION (SELECT a FROM t2 WHERE a=11 AND B=2) ORDER BY a LIMIT 10;
UNIONdoes not supportSELECT HIGH_PRIORITYandSELECT INTOfile statements.
PostgreSQL: UNION ALL
-
Column names after
UNIONshould be the column names of the firstSELECTstatement. -
When a
UNIONstatement containsORDER BYandLIMIT, the user needs to use parentheses to enclose each query statement. The lastUNIONclause can not have parentheses. Without parentheses, theORDER BY LIMITclause is applied to the entireUNIONresult. -
The
UNIONstatement does not supportFOR NO KEY UPDATE,FOR UPDATE,FOR SHAREandFOR KEY SHARE.
Oracle: UNION ALL
-
The
UNIONstatement does not support BLOB,CLOB,BFILE,VARRAY,LONGtypes or nested tables. -
The
UNIONstatement does not supportfor_update_clause. -
The
UNIONstatement does not supportorder_by_clausein the selection clause. The user can only addorder_by_clauseat the end of the UNION statement.
SELECT product_id FROM order_items UNION SELECT product_id FROM inventories ORDER BY product_id;
- The
UNIONstatement does not supportSELECTstatements withTABLEcollection expressions;
SQL Server: UNION ALL
- When the
ORDER BYclause is used in aUNIONstatement, it must be placed above the lastSELECTclause to sort theUNIONresults. Based on the standards mentioned above, we can see that different database dialects can support the simpleSELECT * FROM table WHEREstatement, and with syntax adjustment, theORDER BY LIMITstatement can also be supported as well (however, there are some syntax differences).
Considering that optimization-oriented rewriting requires SQL compatibility, Apache ShardingSphere 5.1.0 is only developed to rewrite the simple statement SELECT * FROM table WHERE to quickly improve query performance in OLTP scenarios.
Here is the latest logic behind the RouteSQLRewriteEngine Rewriter Engine. In Apache ShardingSphere 5.1.0, the optimal rewriting logic for the SELECT * FROM table WHERE statement is added: first, NeedAggregateRewrite is used to judge rows, and only when the number of routing results in the same data source is greater than 1 and when the actual SQL statement follows the SELECT * FROM table WHERE structure, rewriting it into a UNION ALL statement will be performed.
/**
* Rewrite SQL and parameters.
*
* @param sqlRewriteContext SQL rewrite context
* @param routeContext route context
* @return SQL rewrite result
*/
public RouteSQLRewriteResult rewrite(final SQLRewriteContext sqlRewriteContext, final RouteContext routeContext) {
Map<RouteUnit, SQLRewriteUnit> result = new LinkedHashMap<>(routeContext.getRouteUnits().size(), 1);
for (Entry<String, Collection<RouteUnit>> entry : aggregateRouteUnitGroups(routeContext.getRouteUnits()).entrySet()) {
Collection<RouteUnit> routeUnits = entry.getValue();
if (isNeedAggregateRewrite(sqlRewriteContext.getSqlStatementContext(), routeUnits)) {
result.put(routeUnits.iterator().next(), createSQLRewriteUnit(sqlRewriteContext, routeContext, routeUnits));
} else {
result.putAll(createSQLRewriteUnits(sqlRewriteContext, routeContext, routeUnits));
}
}
return new RouteSQLRewriteResult(result);
}
Due to the UNION ALL rewriting function, the judgment logic for queryResults in Merger Engine also needs to be adjusted synchronously. Originally, multiple queryResults may be merged into one queryResults by UNION ALL. In this scenario, merging still needs to be executed.
@Override
public MergedResult merge(final List<QueryResult> queryResults, final SQLStatementContext<?> sqlStatementContext, final ShardingSphereSchema schema) throws SQLException {
if (1 == queryResults.size() && !isNeedAggregateRewrite(sqlStatementContext)) {
return new IteratorStreamMergedResult(queryResults);
}
Map<String, Integer> columnLabelIndexMap = getColumnLabelIndexMap(queryResults.get(0));
SelectStatementContext selectStatementContext = (SelectStatementContext) sqlStatementContext;
selectStatementContext.setIndexes(columnLabelIndexMap);
MergedResult mergedResult = build(queryResults, selectStatementContext, columnLabelIndexMap, schema);
return decorate(queryResults, selectStatementContext, mergedResult);
}
In order to make it easier for you to understand the optimization, we use the following sharding configuration and SELECT * FROM t_order to show the optimization effect. In the example below, the max-connections-size-per-query parameter is the default value 1.
rules:
- !SHARDING
tables:
t_order:
actualDataNodes: ds_${0..1}.t_order_${0..1}
tableStrategy:
standard:
shardingColumn: order_id
shardingAlgorithmName: t_order_inline
databaseStrategy:
standard:
shardingColumn: user_id
shardingAlgorithmName: database_inline
shardingAlgorithms:
database_inline:
type: INLINE
props:
algorithm-expression: ds_${user_id % 2}
t_order_inline:
type: INLINE
props:
algorithm-expression: t_order_${order_id % 2}
In Apache ShardingSphere Version 5.0.0, after we execute the SELECT * FROM t_order statement, we can get the following routing result: there are two data sources, ds_0 and ds_1, and each of them contains two routing results. Since max-connections-size-per -query is set to 1, it is impossible for each real SQL statement to have a database connection, so the connection limit mode is chosen.
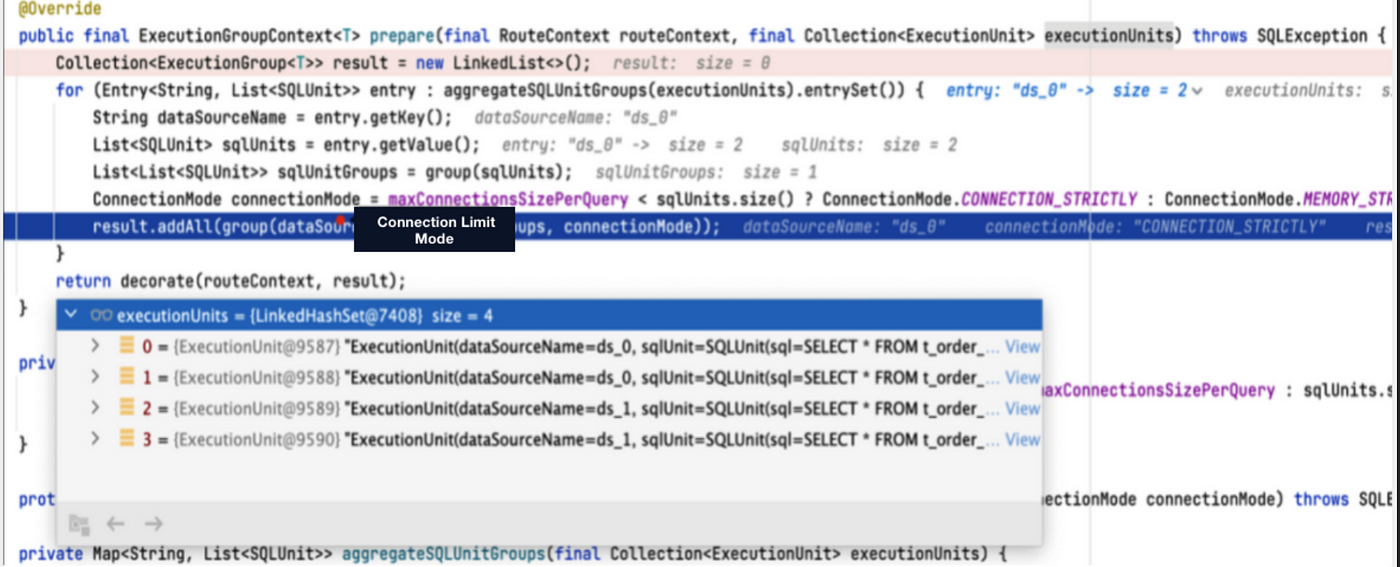
Since the connection limit mode is used at the same time, the result set is loaded into the memory after parallel execution, and the JDBCMemoryQueryResult is used for storage. Therefore, when the user result set is large, it will occupy more memory. The use of in-memory result sets also results in only in-memory merging, but not streaming merging.
private QueryResult createQueryResult(final ResultSet resultSet, final ConnectionMode connectionMode) throws SQLException {
return ConnectionMode.MEMORY_STRICTLY == connectionMode ? new JDBCStreamQueryResult(resultSet) : new JDBCMemoryQueryResult(resultSet);
}
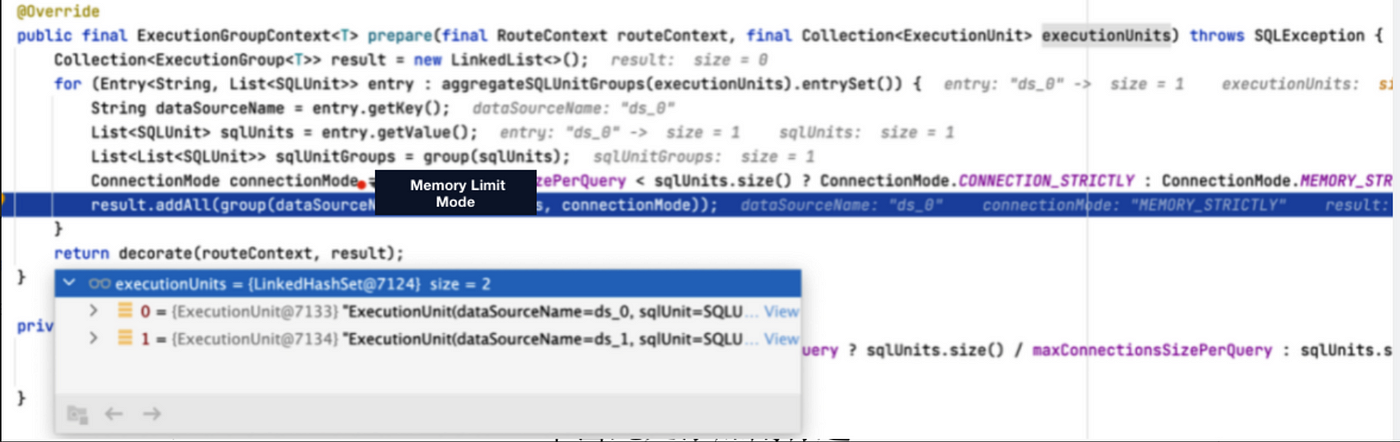
Now, in version 5.1.0, we can use UNION ALL to optimize the executed SQL: multiple routing results in the same data source are combined into one SQL for execution. The memory limit mode is chosen because one database connection can hold one result set. Under the memory limit mode, the streaming result set JDBCStreamQueryResult object is used to hold the result set, so the data in question can be queried by the streaming query method.
Performance Testing
From the example in the previous session, we’ve learned how UNION ALL used for optimization-oriented rewriting can effectively reduce the consumption of database connections, and avoid excessive memory usage by converting in-memory result sets into streaming result sets.
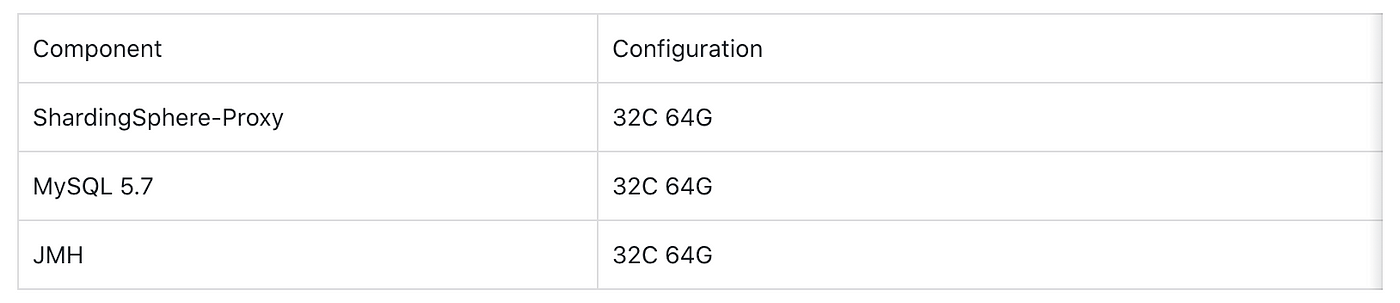
We conducted a stress testing to better measure performance improvement. The implementation details are as follows:

The machine configurations are as follows:
Referring to the sysbench table structure, we created 10 table shards, i.e. sbtest1~sbtest10. Each table shard is divided into 5 databases, and each database is divided into 10 tables.
The config-sharding.yaml configuration file is as follows.
schemaName: sbtest_sharding
dataSources:
ds_0:
url: jdbc:mysql://127.0.0.1:3306/sbtest?useSSL=false&useServerPrepStmts=true&cachePrepStmts=true&prepStmtCacheSize=8192&prepStmtCacheSqlLimit=1024
username: root
password: 123456
connectionTimeoutMilliseconds: 10000
idleTimeoutMilliseconds: 60000
maxLifetimeMilliseconds: 1800000
maxPoolSize: 50
minPoolSize: 1
ds_1:
url: jdbc:mysql://127.0.0.1:3306/sbtest?useSSL=false&useServerPrepStmts=true&cachePrepStmts=true&prepStmtCacheSize=8192&prepStmtCacheSqlLimit=1024
username: root
password: 123456
connectionTimeoutMilliseconds: 10000
idleTimeoutMilliseconds: 60000
maxLifetimeMilliseconds: 1800000
maxPoolSize: 50
minPoolSize: 1
ds_2:
url: jdbc:mysql://127.0.0.1:3306/sbtest?useSSL=false&useServerPrepStmts=true&cachePrepStmts=true&prepStmtCacheSize=8192&prepStmtCacheSqlLimit=1024
username: root
password: 123456
connectionTimeoutMilliseconds: 10000
idleTimeoutMilliseconds: 60000
maxLifetimeMilliseconds: 1800000
maxPoolSize: 50
minPoolSize: 1
ds_3:
url: jdbc:mysql://127.0.0.1:3306/sbtest?useSSL=false&useServerPrepStmts=true&cachePrepStmts=true&prepStmtCacheSize=8192&prepStmtCacheSqlLimit=1024
username: root
password: 123456
connectionTimeoutMilliseconds: 10000
idleTimeoutMilliseconds: 60000
maxLifetimeMilliseconds: 1800000
maxPoolSize: 50
minPoolSize: 1
ds_4:
url: jdbc:mysql://127.0.0.1:3306/sbtest?useSSL=false&useServerPrepStmts=true&cachePrepStmts=true&prepStmtCacheSize=8192&prepStmtCacheSqlLimit=1024
username: root
password: 123456
connectionTimeoutMilliseconds: 10000
idleTimeoutMilliseconds: 60000
maxLifetimeMilliseconds: 1800000
maxPoolSize: 50
minPoolSize: 1
rules:
- !SHARDING
tables:
sbtest1:
actualDataNodes: ds_${0..4}.sbtest1_${0..9}
tableStrategy:
standard:
shardingColumn: id
shardingAlgorithmName: table_inline_1
keyGenerateStrategy:
column: id
keyGeneratorName: snowflake
sbtest2:
actualDataNodes: ds_${0..4}.sbtest2_${0..9}
tableStrategy:
standard:
shardingColumn: id
shardingAlgorithmName: table_inline_2
keyGenerateStrategy:
column: id
keyGeneratorName: snowflake
sbtest3:
actualDataNodes: ds_${0..4}.sbtest3_${0..9}
tableStrategy:
standard:
shardingColumn: id
shardingAlgorithmName: table_inline_3
keyGenerateStrategy:
column: id
keyGeneratorName: snowflake
sbtest4:
actualDataNodes: ds_${0..4}.sbtest4_${0..9}
tableStrategy:
standard:
shardingColumn: id
shardingAlgorithmName: table_inline_4
keyGenerateStrategy:
column: id
keyGeneratorName: snowflake
sbtest5:
actualDataNodes: ds_${0..4}.sbtest5_${0..9}
tableStrategy:
standard:
shardingColumn: id
shardingAlgorithmName: table_inline_5
keyGenerateStrategy:
column: id
keyGeneratorName: snowflake
sbtest6:
actualDataNodes: ds_${0..4}.sbtest6_${0..9}
tableStrategy:
standard:
shardingColumn: id
shardingAlgorithmName: table_inline_6
keyGenerateStrategy:
column: id
keyGeneratorName: snowflake
sbtest7:
actualDataNodes: ds_${0..4}.sbtest7_${0..9}
tableStrategy:
standard:
shardingColumn: id
shardingAlgorithmName: table_inline_7
keyGenerateStrategy:
column: id
keyGeneratorName: snowflake
sbtest8:
actualDataNodes: ds_${0..4}.sbtest8_${0..9}
tableStrategy:
standard:
shardingColumn: id
shardingAlgorithmName: table_inline_8
keyGenerateStrategy:
column: id
keyGeneratorName: snowflake
sbtest9:
actualDataNodes: ds_${0..4}.sbtest9_${0..9}
tableStrategy:
standard:
shardingColumn: id
shardingAlgorithmName: table_inline_9
keyGenerateStrategy:
column: id
keyGeneratorName: snowflake
sbtest10:
actualDataNodes: ds_${0..4}.sbtest10_${0..9}
tableStrategy:
standard:
shardingColumn: id
shardingAlgorithmName: table_inline_10
keyGenerateStrategy:
column: id
keyGeneratorName: snowflake
defaultDatabaseStrategy:
standard:
shardingColumn: id
shardingAlgorithmName: database_inline
shardingAlgorithms:
database_inline:
type: INLINE
props:
algorithm-expression: ds_${id % 5}
allow-range-query-with-inline-sharding: true
table_inline_1:
type: INLINE
props:
algorithm-expression: sbtest1_${id % 10}
allow-range-query-with-inline-sharding: true
table_inline_2:
type: INLINE
props:
algorithm-expression: sbtest2_${id % 10}
allow-range-query-with-inline-sharding: true
table_inline_3:
type: INLINE
props:
algorithm-expression: sbtest3_${id % 10}
allow-range-query-with-inline-sharding: true
table_inline_4:
type: INLINE
props:
algorithm-expression: sbtest4_${id % 10}
allow-range-query-with-inline-sharding: true
table_inline_5:
type: INLINE
props:
algorithm-expression: sbtest5_${id % 10}
allow-range-query-with-inline-sharding: true
table_inline_6:
type: INLINE
props:
algorithm-expression: sbtest6_${id % 10}
allow-range-query-with-inline-sharding: true
table_inline_7:
type: INLINE
props:
algorithm-expression: sbtest7_${id % 10}
allow-range-query-with-inline-sharding: true
table_inline_8:
type: INLINE
props:
algorithm-expression: sbtest8_${id % 10}
allow-range-query-with-inline-sharding: true
table_inline_9:
type: INLINE
props:
algorithm-expression: sbtest9_${id % 10}
allow-range-query-with-inline-sharding: true
table_inline_10:
type: INLINE
props:
algorithm-expression: sbtest10_${id % 10}
allow-range-query-with-inline-sharding: true
keyGenerators:
snowflake:
type: SNOWFLAKE
props:
worker-id: 123
We use the JMH test program to test different cases:
@State(Scope.Thread)
public class QueryOptimizationTest {
private PreparedStatement unionAllForCaseOneStatement;
private PreparedStatement unionAllForCaseTwoStatement;
@Setup(Level.Trial)
public void setup() throws Exception {
Connection connection = DriverManager.getConnection("jdbc:mysql://127.0.0.1:3307/sharding_db?useSSL=false", "root", "123456");
// CASE 1
unionAllForCaseOneStatement = connection.prepareStatement("SELECT COUNT(k) AS countK FROM sbtest1 WHERE id < ?;");
// CASE 2
unionAllForCaseTwoStatement = connection.prepareStatement("SELECT SUM(k) AS sumK FROM sbtest1 WHERE id < ?;");
}
@Benchmark
public void testUnionAllForCaseOne() throws SQLException {
unionAllForCaseOneStatement.setInt(1, 200);
unionAllForCaseOneStatement.executeQuery();
}
@Benchmark
public void testUnionAllForCaseTwo() throws SQLException {
unionAllForCaseTwoStatement.setInt(1, 200);
unionAllForCaseTwoStatement.executeQuery();
}
}
In the performance test, each CASE needed to test 3 groups and then an average value was taken.
Then we switched to the old version, aab226b72ba574061748d8f94c461ea469f9168f to for compiling and packaging, and we also tested 3 groups and took the average value.
The final test results are shown below.

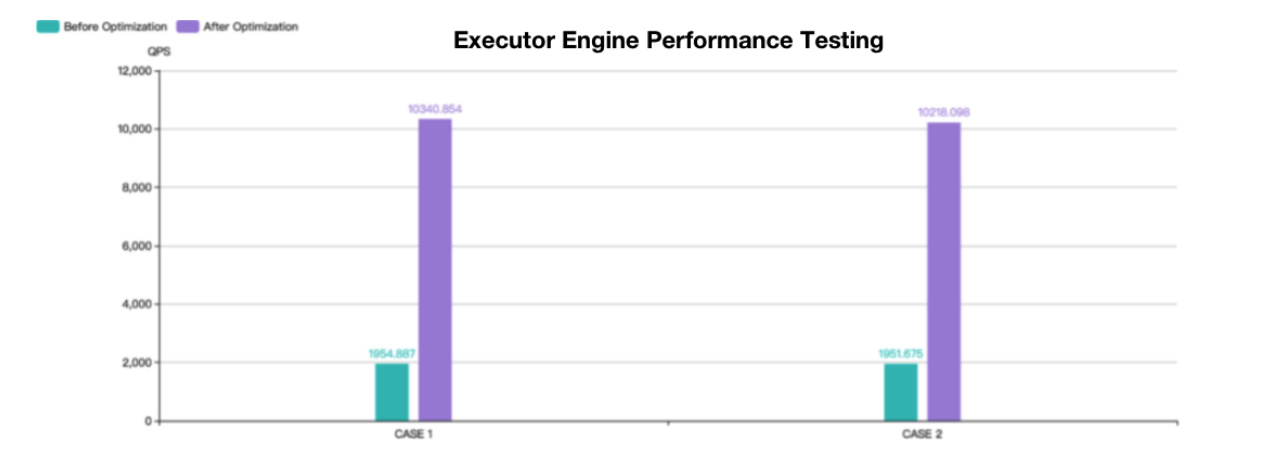
Both CASE 1 and CASE 2 tests are based on the sysbench table structure with a data volume of 1 million. The number of shards in the test tables is relatively large but the overall performance is still improved by about 4 times. Theoretically, the more shards, the better the performance.
Summary
Apache ShardingSphere 5.1.0 has achieved a lot of performance optimizations at both the protocol layer and the kernel layer.
This blog only covers the SQL Executor Engine and its optimizations. In the future, the community will produce more comprehensive guides for performance optimizations.
References
- https://shardingsphere.apache.org/document/current/en/reference/sharding/execute/
- https://github.com/apache/shardingsphere/issues/13942
- MySQL UNION: https://dev.mysql.com/doc/refman/8.0/en/union.html
- PostgreSQL UNION: https://www.postgresql.org/docs/14/sql-select.html
- Oracle UNION: https://docs.oracle.com/en/database/oracle/oracle-database/21/sqlrf/The-UNION-ALL-INTERSECT-MINUS-Operators.html
- SQL Server UNION: https://docs.microsoft.com/en-us/sql/t-sql/language-elements/set-operators-union-transact-sql?view=sql-server-ver15
Author
Duan Zhengqiang
SphereEx Senior Middleware Engineer & Apache ShardingSphere Committer
Duan has been contributing to Apache ShardingSphere since 2018, and previously was an engineering lead at numerous data sharding projects.
He loves open source and sharing his tech stories and experiences with fellow developers. He now devotes himself to developing the Apache ShardingSphere kernel module.
