Create a Distributed Database with High Availability with Apache ShardingSphere
What is Database High Availability (HA)?
Inthe digital age, modern business systems have to be highly available, reliable, and stable. As the cornerstone of the modern business system, databases are supposed to embrace high availability.
HA allows databases to switch over services between primary and secondary databases and to automatically select Master, so it can pick the best node as the master when the previous one crashes.
MySQL High Availability
There are plenty of MySQL high availability options, but each of them has its pros and cons. Below are several common high availability options:
-
Orchestrator is a MySQL HA and replication topology management tool written in Go. Its advantage lies in its support for manual adjustment of primary-secondary topology, automatic failover, automatic or manual recovery of master nodes through the Web visual console. However, the program needs to be deployed separately, and also has a steep learning curve due to the complex configurations.
-
MHA is another mature solution. It provides primary/secondary switching and failover capabilities. The good thing about it is that it can ensure the least data loss in the switching process while it can work with semi-synchronous and asynchronous replication frameworks. However, after MHA starts, only
Masteris monitored, and MHA doesn’t provide the load balancing feature for the read database. -
MGR implements group replication based on the distributed Paxos protocol to ensure data consistency. It is an official HA component provided by MySQL and no extra deployment program is required. Instead, users only need to install MGR Plugin in each data source node. The tool features high consistency, high fault tolerance, high scalability, and high flexibility.
Apache ShardingSphere High Availability
Apache ShardingSphere’s architecture actually separates storage from computing. The storage node represents the underlying database, such as MySQL, PostgreSQL, openGauss, etc., while compute node refers to ShardingSphere-JDBC or ShardingSphere-Proxy.
Accordingly, the high availability solutions for storage nodes and compute nodes are different. For stateless compute nodes, while they need to perceive the changes in storage nodes, they also need to set up separate load balancers and have the capabilities of service discovery and request distribution. Stateful storage nodes need to be equipped with the capabilities of data synchronization, connection testing, electing a master node, and so on.
Although ShardingSphere doesn’t provide a database with high availability, it can help users integrate database HA solutions such as primary-secondary switchover, faults discovery, traffic switching governance, and so on with the help of the database HA and through its capabilities of database discovery and dynamic perception.
When combined with the primary-secondary flow control feature in distributed scenarios, ShardingSphere can provide better high availability read/write splitting solutions. It will be easier to operate and manage ShardingSphere clusters if we use DistSQL’s dynamic high availability adjustment rules to get primary/secondary nodes' information.
Best Practices
Apache ShardingSphere adopts a plugin-oriented architecture, so all its enhanced capabilities can be used independently or together. Its high availability function is often used together with read/write splitting to distribute query requests to the slave databases according to the load balancing algorithm to ensure system HA, relieve primary database pressure, and improve business system throughput.
Here, we take HA+read/write splitting configuration with ShardingSphere DistSQL RAL statements as an example.
One thing to point out here is that ShardingSphere HA implementation leans on its distributed governance capability. Therefore, it can only be used under the cluster mode for the time being. Meanwhile, read/write splitting rules are revised in ShardingSphere 5.1.0. For details, please refer to the official documentation about read/write splitting.
Configuration
schemaName: database_discovery_db
dataSources:
ds_0:
url: jdbc:mysql://127.0.0.1:1231/demo_primary_ds?serverTimezone=UTC&useSSL=false
username: root
password: 123456
connectionTimeoutMilliseconds: 3000
idleTimeoutMilliseconds: 60000
maxLifetimeMilliseconds: 1800000
maxPoolSize: 50
minPoolSize: 1
ds_1:
url: jdbc:mysql://127.0.0.1:1232/demo_primary_ds?serverTimezone=UTC&useSSL=false
username: root
password: 123456
connectionTimeoutMilliseconds: 3000
idleTimeoutMilliseconds: 60000
maxLifetimeMilliseconds: 1800000
maxPoolSize: 50
minPoolSize: 1
ds_2:
url: jdbc:mysql://127.0.0.1:1233/demo_primary_ds?serverTimezone=UTC&useSSL=false
username: root
password: 123456
connectionTimeoutMilliseconds: 3000
idleTimeoutMilliseconds: 50000
maxLifetimeMilliseconds: 1300000
maxPoolSize: 50
minPoolSize: 1
rules:
- !READWRITE_SPLITTING
dataSourceGroups:
replication_ds:
type: Dynamic
props:
auto-aware-data-source-name: mgr_replication_ds
- !DB_DISCOVERY
dataSources:
mgr_replication_ds:
dataSourceNames:
- ds_0
- ds_1
- ds_2
discoveryHeartbeatName: mgr-heartbeat
discoveryTypeName: mgr
discoveryHeartbeats:
mgr-heartbeat:
props:
keep-alive-cron: '0/5 * * * * ?'
discoveryTypes:
mgr:
type: MGR
props:
group-name: b13df29e-90b6-11e8-8d1b-525400fc3996
Requirements
- ShardingSphere-Proxy 5.1.0 (Cluster mode + HA + dynamic read/write splitting rule)
- Zookeeper 3.7.0
- MySQL MGR cluster
SQL script
CREATE TABLE `t_user` (
`id` int(8) NOT NULL,
`mobile` char(20) NOT NULL,
`idcard` varchar(18) NOT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
View the primary-secondary relationship
mysql> SHOW READWRITE_SPLITTING RULES;
+----------------+-----------------------------+------------------------+------------------------+--------------------+---------------------+
| name | auto_aware_data_source_name | write_data_source_name | read_data_source_names | load_balancer_type | load_balancer_props |
+----------------+-----------------------------+------------------------+------------------------+--------------------+---------------------+
| replication_ds | mgr_replication_ds | ds_0 | ds_1,ds_2 | NULL | |
+----------------+-----------------------------+------------------------+------------------------+--------------------+---------------------+
1 row in set (0.09 sec)
View the secondary database state
mysql> SHOW READWRITE_SPLITTING READ RESOURCES;
+----------+---------+
| resource | status |
+----------+---------+
| ds_1 | enabled |
| ds_2 | enabled |
+----------+---------+
We can learn from the results shown above that, currently, the primary database is ds_0, while secondary databases are ds_1 and ds_2.
Let’s test INSERT:
mysql> INSERT INTO t_user(id, mobile, idcard) value (10000, '13718687777', '141121xxxxx');
Query OK, 1 row affected (0.10 sec)
View the ShardingSphere-Proxy log and see if the route node is the primary database ds_0.
[INFO ] 2022-02-28 15:28:21.495 [ShardingSphere-Command-2] org.apache.shardingsphere.sql - Logic SQL: INSERT INTO t_user(id, mobile, idcard) value (10000, '13718687777', '141121xxxxx')
[INFO ] 2022-02-28 15:28:21.495 [ShardingSphere-Command-2] org.apache.shardingsphere.sql - SQLStatement: MySQLInsertStatement(setAssignment=Optional.empty, onDuplicateKeyColumns=Optional.empty)
[INFO ] 2022-02-28 15:28:21.495 [ShardingSphere-Command-2] org.apache.shardingsphere.sql - Actual SQL: ds_0 ::: INSERT INTO t_user(id, mobile, idcard) value (10000, '13718687777', '141121xxxxx')
Let’s test SELECT (repeat it twice):
mysql> SELECT id, mobile, idcard FROM t_user WHERE id = 10000;
View the ShardingSphere-Proxy log and see if the route node is ds_1 or ds_2.
[INFO ] 2022-02-28 15:34:07.912 [ShardingSphere-Command-4] org.apache.shardingsphere.sql - Logic SQL: SELECT id, mobile, idcard FROM t_user WHERE id = 10000
[INFO ] 2022-02-28 15:34:07.913 [ShardingSphere-Command-4] org.apache.shardingsphere.sql - SQLStatement: MySQLSelectStatement(table=Optional.empty, limit=Optional.empty, lock=Optional.empty, window=Optional.empty)
[INFO ] 2022-02-28 15:34:07.913 [ShardingSphere-Command-4] org.apache.shardingsphere.sql - Actual SQL: ds_1 ::: SELECT id, mobile, idcard FROM t_user WHERE id = 10000
[INFO ] 2022-02-28 15:34:21.501 [ShardingSphere-Command-4] org.apache.shardingsphere.sql - Logic SQL: SELECT id, mobile, idcard FROM t_user WHERE id = 10000
[INFO ] 2022-02-28 15:34:21.502 [ShardingSphere-Command-4] org.apache.shardingsphere.sql - SQLStatement: MySQLSelectStatement(table=Optional.empty, limit=Optional.empty, lock=Optional.empty, window=Optional.empty)
[INFO ] 2022-02-28 15:34:21.502 [ShardingSphere-Command-4] org.apache.shardingsphere.sql - Actual SQL: ds_2 ::: SELECT id, mobile, idcard FROM t_user WHERE id = 10000
Switch to the primary database
Close the master database ds_0:
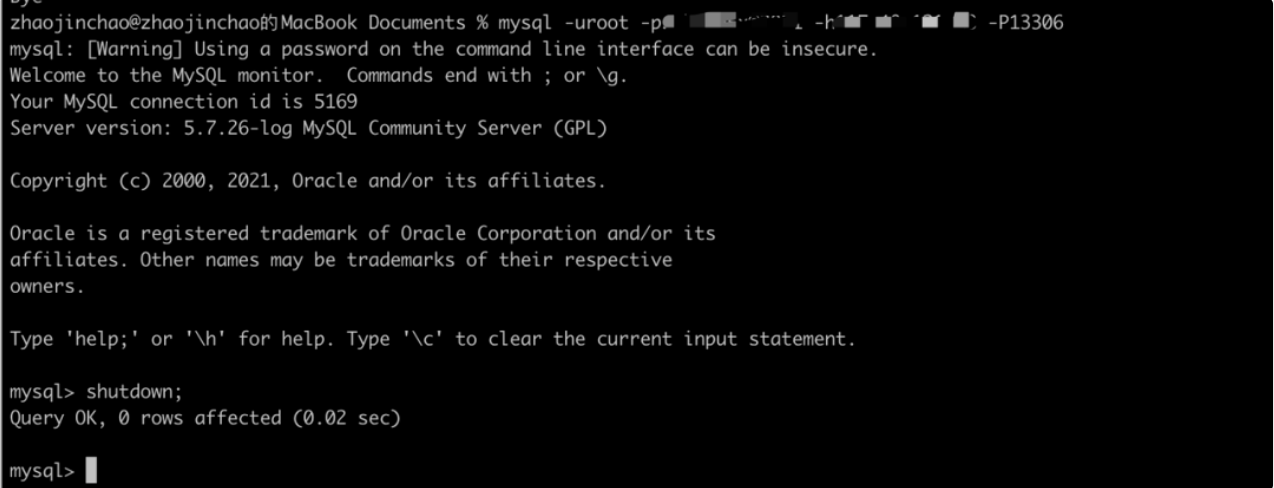
View if the primary database has changed and if the secondary database state is correct through DistSQL.
mysql> SHOW READWRITE_SPLITTING RULES;
+----------------+-----------------------------+------------------------+------------------------+--------------------+---------------------+
| name | auto_aware_data_source_name | write_data_source_name | read_data_source_names | load_balancer_type | load_balancer_props |
+----------------+-----------------------------+------------------------+------------------------+--------------------+---------------------+
| replication_ds | mgr_replication_ds | ds_1 | ds_2 | NULL | |
+----------------+-----------------------------+------------------------+------------------------+--------------------+---------------------+
1 row in set (0.01 sec)
mysql> SHOW READWRITE_SPLITTING READ RESOURCES;
+----------+----------+
| resource | status |
+----------+----------+
| ds_2 | enabled |
| ds_0 | disabled |
+----------+----------+
2 rows in set (0.01 sec)
Now, let’s INSERT another line of data:
mysql> INSERT INTO t_user(id, mobile, idcard) value (10001, '13521207777', '110xxxxx');
Query OK, 1 row affected (0.04 sec)
View the ShardingSphere-Proxy log and see if the route node is the primary database ds_1.
[INFO ] 2022-02-28 15:40:26.784 [ShardingSphere-Command-6] org.apache.shardingsphere.sql - Logic SQL: INSERT INTO t_user(id, mobile, idcard) value (10001, '13521207777', '110xxxxx')
[INFO ] 2022-02-28 15:40:26.784 [ShardingSphere-Command-6] org.apache.shardingsphere.sql - SQLStatement: MySQLInsertStatement(setAssignment=Optional.empty, onDuplicateKeyColumns=Optional.empty)
[INFO ] 2022-02-28 15:40:26.784 [ShardingSphere-Command-6] org.apache.shardingsphere.sql - Actual SQL: ds_1 ::: INSERT INTO t_user(id, mobile, idcard) value (10001, '13521207777', '110xxxxx')
Lastly, let’s test `SELECT(repeat it twice):
mysql> SELECT id, mobile, idcard FROM t_user WHERE id = 10001;
View the ShardingSphere-Proxy log and see if the route node is ds_2.
[INFO ] 2022-02-28 15:42:00.651 [ShardingSphere-Command-7] org.apache.shardingsphere.sql - Logic SQL: SELECT id, mobile, idcard FROM t_user WHERE id = 10001
[INFO ] 2022-02-28 15:42:00.651 [ShardingSphere-Command-7] org.apache.shardingsphere.sql - SQLStatement: MySQLSelectStatement(table=Optional.empty, limit=Optional.empty, lock=Optional.empty, window=Optional.empty)
[INFO ] 2022-02-28 15:42:00.651 [ShardingSphere-Command-7] org.apache.shardingsphere.sql - Actual SQL: ds_2 ::: SELECT id, mobile, idcard FROM t_user WHERE id = 10001
[INFO ] 2022-02-28 15:42:02.148 [ShardingSphere-Command-7] org.apache.shardingsphere.sql - Logic SQL: SELECT id, mobile, idcard FROM t_user WHERE id = 10001
[INFO ] 2022-02-28 15:42:02.149 [ShardingSphere-Command-7] org.apache.shardingsphere.sql - SQLStatement: MySQLSelectStatement(table=Optional.empty, limit=Optional.empty, lock=Optional.empty, window=Optional.empty)
[INFO ] 2022-02-28 15:42:02.149 [ShardingSphere-Command-7] org.apache.shardingsphere.sql - Actual SQL: ds_2 ::: SELECT id, mobile, idcard FROM t_user WHERE id = 10001
View the latest primary-secondary relationship changes through DistSQL. The state of ds_0 node is recovered as enabled, while ds_0 is integrated to read_data_source_names:
mysql> SHOW READWRITE_SPLITTING RULES;
+----------------+-----------------------------+------------------------+------------------------+--------------------+---------------------+
| name | auto_aware_data_source_name | write_data_source_name | read_data_source_names | load_balancer_type | load_balancer_props |
+----------------+-----------------------------+------------------------+------------------------+--------------------+---------------------+
| replication_ds | mgr_replication_ds | ds_1 | ds_0,ds_2 | NULL | |
+----------------+-----------------------------+------------------------+------------------------+--------------------+---------------------+
1 row in set (0.01 sec)
mysql> SHOW READWRITE_SPLITTING READ RESOURCES;
+----------+---------+
| resource | status |
+----------+---------+
| ds_0 | enabled |
| ds_2 | enabled |
+----------+---------+
2 rows in set (0.00 sec)
Based on the above-mentioned example, you now know more about ShardingSphere’s high availability and dynamic read/write splitting.
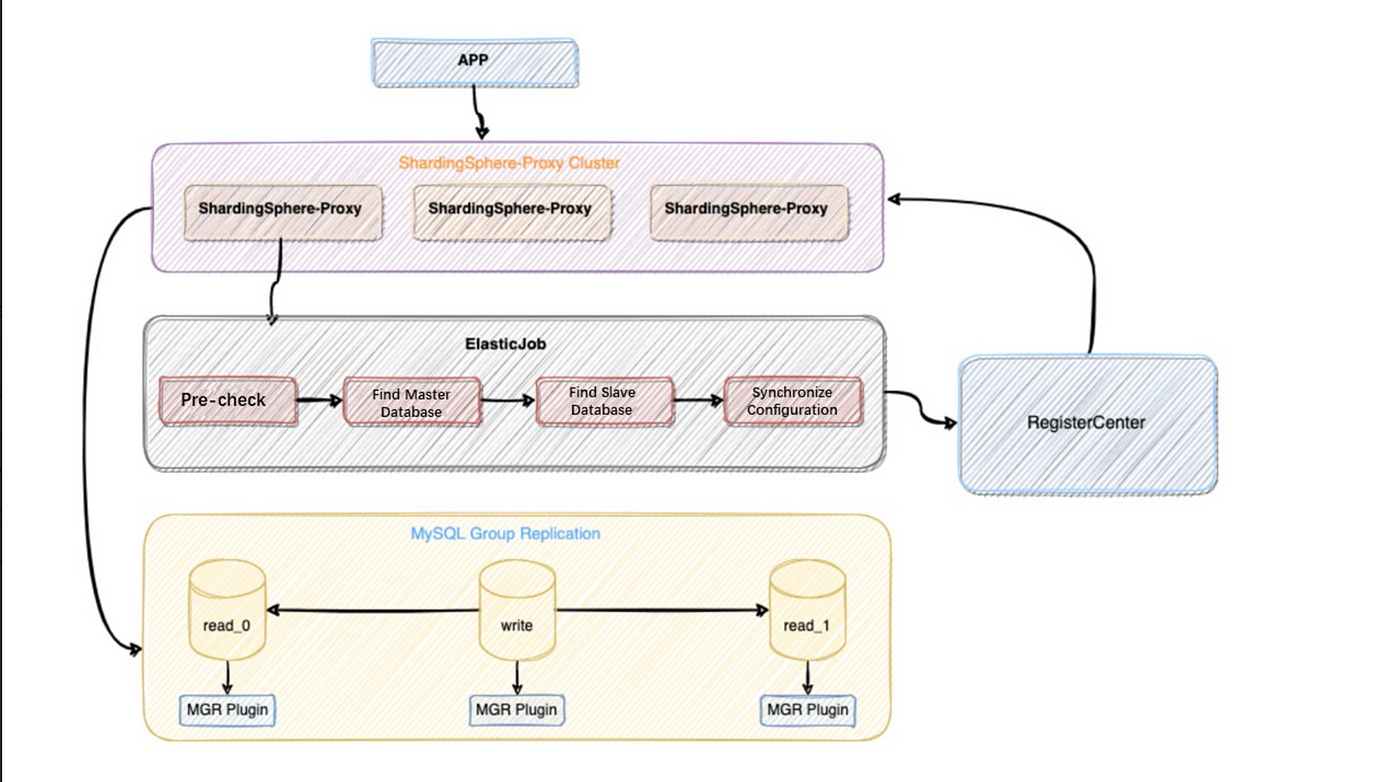
Next, we will introduce the principles behind the HA plans regarding the underlying database, also known as the storage nodes.
Principles
ShardingSphere’s high availability solutions allow users to further customize it and make extensions. Currently, we have completed two HA plans: a MySQL high availability solution based on MGR, and openGauss database high availability solution contributed by some community committers. The principles of the two solutions are basically the same.
Below is why and how ShardingSphere can achieve database high availability with MySQL as an example.
Prerequisite
ShardingSphere checks if the underlying MySQL cluster environment is ready by executing the following SQL statement. ShardingSphere cannot be started if any of the tests fail.
- Check if MGR is installed:
SELECT * FROM information_schema.PLUGINS WHERE PLUGIN_NAME='group_replication'
- View the MGR group member number: The underlying MGR cluster should consist of at least three nodes:
SELECT count(*) FROM performance_schema.replication_group_members
- Check whether the MGR cluster’s group name is consistent with that in the configuration: group name is the marker of a MGR group, and each group of a MGR cluster only has one group name.
SELECT * FROM performance_schema.global_variables WHERE VARIABLE_NAME='group_replication_group_name'
- Check if the current MGR is set as the single primary mode:
Currently, ShardingSphere does not support dual-write or multi-write scenarios. It only supports single-write mode:
SELECT * FROM performance_schema.global_variables WHERE VARIABLE_NAME='group_replication_single_primary_mode'
- Query all the node hosts, ports, and states in the MGR group cluster to check if the data source we configured is correct:
SELECT MEMBER_HOST, MEMBER_PORT, MEMBER_STATE FROM performance_schema.replication_group_members
Dynamic primary database discovery
- ShardingSphere finds the primary database URL according to the query master database SQL command provided by MySQL.
private String findPrimaryDataSourceURL(final Map<String, DataSource> dataSourceMap) {
String result = "";
String sql = "SELECT MEMBER_HOST, MEMBER_PORT FROM performance_schema.replication_group_members WHERE MEMBER_ID = "
+ "(SELECT VARIABLE_VALUE FROM performance_schema.global_status WHERE VARIABLE_NAME = 'group_replication_primary_member')";
for (DataSource each : dataSourceMap.values()) {
try (Connection connection = each.getConnection();
Statement statement = connection.createStatement();
ResultSet resultSet = statement.executeQuery(sql)) {
if (resultSet.next()) {
return String.format("%s:%s", resultSet.getString("MEMBER_HOST"), resultSet.getString("MEMBER_PORT"));
}
} catch (final SQLException ex) {
log.error("An exception occurred while find primary data source url", ex);
}
}
return result;
}
- Compare the primary database URLs found above one by one with the
dataSourcesURLs we configured. The matched data source is the primary database and it will be updated to the current ShardingSphere memory and be perpetuated to the registry center, through which it will be distributed to other compute nodes in the cluster.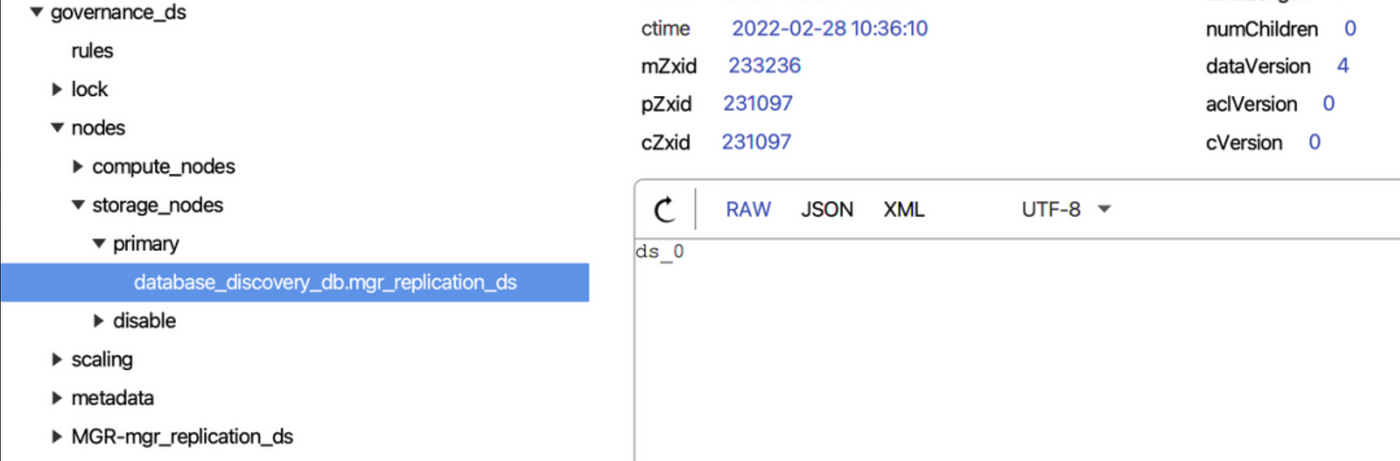
Dynamic secondary database discovery
There are two types of secondary database states in ShardingSpherez: enable and disable. The secondary database state will be synchronized to the ShardingSphere memory to ensure that read traffic can be routed correctly.
- Get all the nodes in the MGR group:
SELECT MEMBER_HOST, MEMBER_PORT, MEMBER_STATE FROM performance_schema.replication_group_members
- Disable secondary databases:
private void determineDisabledDataSource(final String schemaName, final Map<String, DataSource> activeDataSourceMap,
final List<String> memberDataSourceURLs, final Map<String, String> dataSourceURLs) {
for (Entry<String, DataSource> entry : activeDataSourceMap.entrySet()) {
boolean disable = true;
String url = null;
try (Connection connection = entry.getValue().getConnection()) {
url = connection.getMetaData().getURL();
for (String each : memberDataSourceURLs) {
if (null != url && url.contains(each)) {
disable = false;
break;
}
}
} catch (final SQLException ex) {
log.error("An exception occurred while find data source urls", ex);
}
if (disable) {
ShardingSphereEventBus.getInstance().post(new DataSourceDisabledEvent(schemaName, entry.getKey(), true));
} else if (!url.isEmpty()) {
dataSourceURLs.put(entry.getKey(), url);
}
}
}
Whether the secondary database is disabled is based on the data source we configured and all the nodes in the MGR group.
ShardingSphere can check one by one whether the data source we configured can obtain Connection properly, and verify whether the data source URL contains nodes of the MGR group.
If Connection cannot be obtained or the verification fails, ShardingSphere will disable the data source by an event trigger and synchronize it to the registry center.
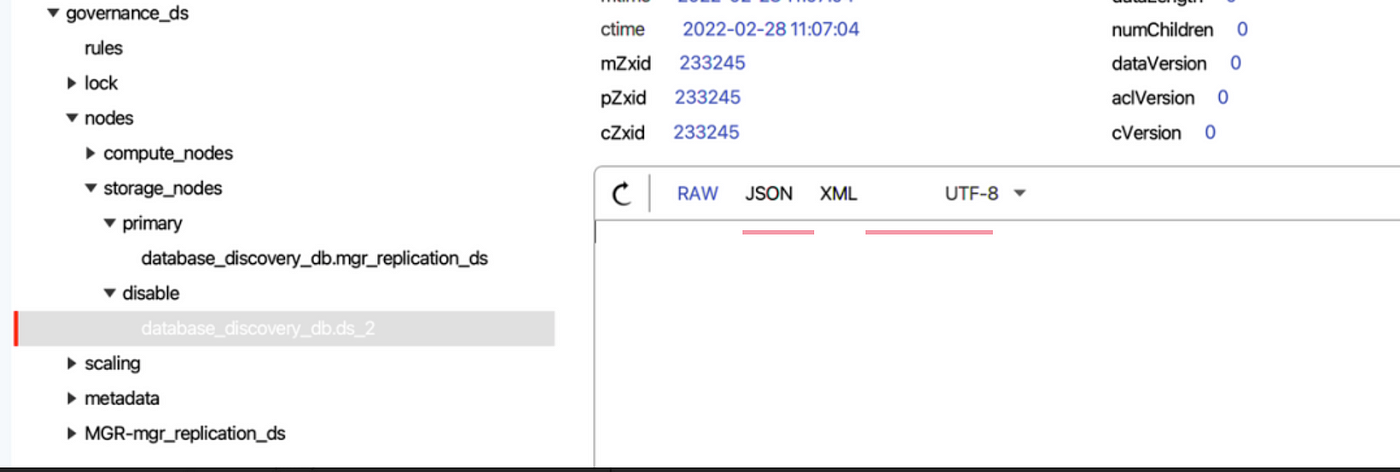
- Enable secondary databases:
private void determineEnabledDataSource(final Map<String, DataSource> dataSourceMap, final String schemaName,
final List<String> memberDataSourceURLs, final Map<String, String> dataSourceURLs) {
for (String each : memberDataSourceURLs) {
boolean enable = true;
for (Entry<String, String> entry : dataSourceURLs.entrySet()) {
if (entry.getValue().contains(each)) {
enable = false;
break;
}
}
if (!enable) {
continue;
}
for (Entry<String, DataSource> entry : dataSourceMap.entrySet()) {
String url;
try (Connection connection = entry.getValue().getConnection()) {
url = connection.getMetaData().getURL();
if (null != url && url.contains(each)) {
ShardingSphereEventBus.getInstance().post(new DataSourceDisabledEvent(schemaName, entry.getKey(), false));
break;
}
} catch (final SQLException ex) {
log.error("An exception occurred while find enable data source urls", ex);
}
}
}
}
After the crashed secondary database is recovered and added to the MGR group, our configuration will be checked to see whether the recovered data source is used. If yes, the event trigger will tell ShardingSphere that the data source needs to be enabled.
Heartbeat Mechanism
To ensure that the primary-secondary states are synchronized in real-time, the heartbeat mechanism is introduced to the HA module.
By integrating the ShardingSphere sub-project ElasticJob, the above processes are executed by the ElasticJob scheduler framework in a form of Job when the HA module is initialized, thus achieving the separation of function development and job scheduling.
Even if developers need to extend the HA function, they do not need to care about how jobs are developed and operated.
private void initHeartBeatJobs(final String schemaName, final Map<String, DataSource> dataSourceMap) {
Optional<ModeScheduleContext> modeScheduleContext = ModeScheduleContextFactory.getInstance().get();
if (modeScheduleContext.isPresent()) {
for (Entry<String, DatabaseDiscoveryDataSourceRule> entry : dataSourceRules.entrySet()) {
Map<String, DataSource> dataSources = dataSourceMap.entrySet().stream().filter(dataSource -> !entry.getValue().getDisabledDataSourceNames().contains(dataSource.getKey()))
.collect(Collectors.toMap(Entry::getKey, Entry::getValue));
CronJob job = new CronJob(entry.getValue().getDatabaseDiscoveryType().getType() + "-" + entry.getValue().getGroupName(),
each -> new HeartbeatJob(schemaName, dataSources, entry.getValue().getGroupName(), entry.getValue().getDatabaseDiscoveryType(), entry.getValue().getDisabledDataSourceNames())
.execute(null), entry.getValue().getHeartbeatProps().getProperty("keep-alive-cron"));
modeScheduleContext.get().startCronJob(job);
}
}
}
Conclusion
So far Apache ShardingSphere’s HA feature has proven to be applicable for MySQL and openGauss HA solutions.
Moving forward, it will integrate more MySQL HA products and support more database HA solutions.
As always, if you’re interested, you’re more than welcome to join us and contribute to the Apache ShardingSphere project.
Apache ShardingSphere Project Links:
Author
Zhao Jinchao
SphereEx Middleware Engineer & Apache ShardingSphere Committer
Currently, Zhao concentrates on developing the feature High Availability of Apache ShardingSphere.