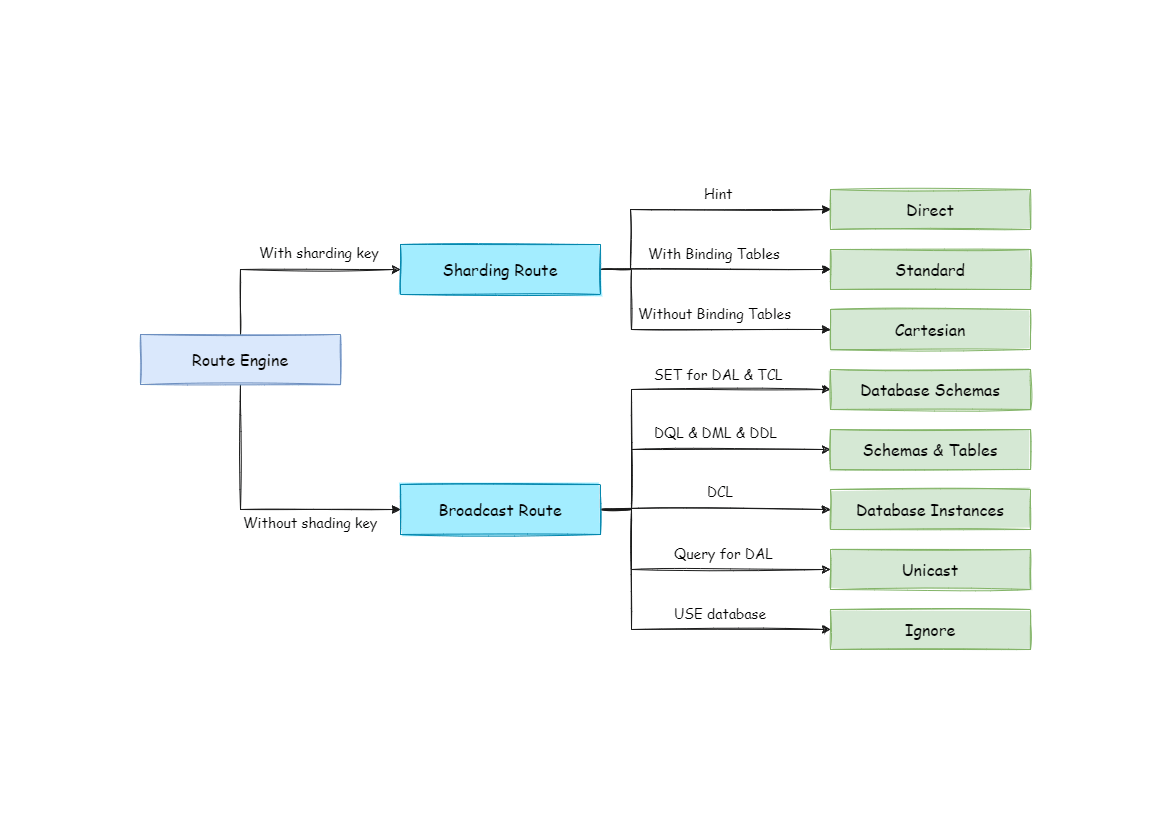
Sharding strategies for databases and tables are matched based on the parsing context, and routing paths are generated. SQL with shard keys can be divided into the single-shard router (the shard key operator is equal), multi-shard router (the shard key operator is IN), and range router (the shard key operator is BETWEEN). SQL that does not carry shard keys adopts broadcast routing.
Sharding strategies can usually be configured either by the built-in database or by the user. The built-in database scheme is relatively simple, and the built-in sharding strategy can be roughly divided into mantissa modulo, hash, range, label, time, etc.
The sharding strategies configured by the user are more flexible. You can customize the compound sharding strategy based on the user’s requirements. If it is used with automatic data migration, users do not need to work on the sharding strategies.
Sharding and data balancing can be automatically achieved by the middle layer of the database, and distributed databases can achieve elastic scalability. In the planning of ShardingSphere, the elastic scaling function will be available at V4.x.
The scenario that is routed based on shard keys is divided into three types: direct route, standard route, and Cartesian route.
The requirement for direct route is relatively harsh. It needs to be sharded by Hint (using HintAPI to specify routes to databases and tables), and it can avoid SQL parsing and subsequent result merge on the premise of having database shards but not table shards.
Therefore, it is the most compatible one and can execute any SQL in complex scenarios including sub-queries and custom functions. The direct route can also be used when shard keys are not in SQL. For example, set the key for database sharding to 3,
hintManager.setDatabaseShardingValue(3);
If the routing algorithm is value % 2, when a logical database t_order corresponds to two physical databasest_order_0 and t_order_1, the SQL will be executed on t_order_1 after routing.
The following is a sample code using the API.
String sql = "SELECT * FROM t_order";
try (
HintManager hintManager = HintManager.getInstance();
Connection conn = dataSource.getConnection();
PreparedStatement pstmt = conn.prepareStatement(sql)) {
hintManager.setDatabaseShardingValue(3);
try (ResultSet rs = pstmt.executeQuery()) {
while (rs.next()) {
//...
}
}
}
The standard route is the most recommended sharding method, and it is applicable to SQL that does not contain an associated query or only contains the associated query between binding tables.
When the sharding operator is equal, the routing result will fall into a single database (table). When the sharding operator is BETWEEN or IN, the routing result will not necessarily fall into a unique database (table).
Therefore, logical SQL may eventually be split into multiple real SQL to be executed. For example, if the data sharding is carried out according to the odd and even numbers of order_id, the SQL for a single table query is as follows:
SELECT * FROM t_order WHERE order_id IN (1, 2);
Then the routing result should be:
SELECT * FROM t_order_0 WHERE order_id IN (1, 2);
SELECT * FROM t_order_1 WHERE order_id IN (1, 2);
An associated query for a binding table is as complex as a single table query and they have the same performance. For example, if the SQL of an associated query that contains binding tables is as follows:
SELECT * FROM t_order o JOIN t_order_item i ON o.order_id=i.order_id WHERE order_id IN (1, 2);
Then the routing result should be:
SELECT * FROM t_order_0 o JOIN t_order_item_0 i ON o.order_id=i.order_id WHERE order_id IN (1, 2);
SELECT * FROM t_order_1 o JOIN t_order_item_1 i ON o.order_id=i.order_id WHERE order_id IN (1, 2);
As you can see, the number of SQL splits is consistent with that of a single table.
The Cartesian route is the most complex one because it cannot locate sharding rules according to the relationship between binding tables, so associated queries between unbound tables need to be disassembled and executed as cartesian product combinations. If the SQL in the previous example was not configured with binding table relationships, the routing result would be:
SELECT * FROM t_order_0 o JOIN t_order_item_0 i ON o.order_id=i.order_id WHERE order_id IN (1, 2);
SELECT * FROM t_order_0 o JOIN t_order_item_1 i ON o.order_id=i.order_id WHERE order_id IN (1, 2);
SELECT * FROM t_order_1 o JOIN t_order_item_0 i ON o.order_id=i.order_id WHERE order_id IN (1, 2);
SELECT * FROM t_order_1 o JOIN t_order_item_1 i ON o.order_id=i.order_id WHERE order_id IN (1, 2);
The Cartesian route query has low performance, so think carefully when you use it.
For SQL that does not carry shard keys, broadcast routes are used. According to the SQL type, it can be further divided into five types: full database and table route, full database route, full instance route, unicast route, and block route.
The full database table route is used to handle operations on all real tables related to its logical tables in the database, including DQL and DML without shard keys, as well as DDL, etc. For example:
SELECT * FROM t_order WHERE good_prority IN (1, 10);
All tables in all databases will be traversed, matching logical tables and real table names one by one. The table that can be matched will be executed. The routing result would be:
SELECT * FROM t_order_0 WHERE good_prority IN (1, 10);
SELECT * FROM t_order_1 WHERE good_prority IN (1, 10);
SELECT * FROM t_order_2 WHERE good_prority IN (1, 10);
SELECT * FROM t_order_3 WHERE good_prority IN (1, 10);
The full database route is used to handle operations on the database, including database management commands of type SET for database settings and transaction control statements such as TCL.
In this case, all real database matching names are traversed based on the logical database name, and the command is executed in the real database. For example:
SET autocommit=0;
If the command is executed in t_order, t_order which has two real databases, it is actually executed on both t_order_0 and t_order_1.
Full instance route is used for DCL operations, and authorized statements are used for database instances.
No matter how many schemas are contained in an instance, each database instance is executed only once. For example:
CREATE USER customer@127.0.0.1 identified BY '123';
This command will be executed on all real database instances to ensure that users can access each instance.
The unicast route is used to obtain the information of a real table. It only needs to obtain data from any real table in any database. For example:
DESCRIBE t_order;
t_order_0 and t_order_1, the two real tables of t_order, have the same description structure, so this command is executed only once on any real table.
Block route is used to block SQL operations on the database, for example:
USE order_db;
This command will not be executed in a real database because ShardingSphere uses the logical Schema and there is no need to send the Schema shift command to the database.
The overall structure of the routing engine is as follows.