回答:
回答:
Spring 命名空间使用规范并未强制要求将 xsd 文件部署至公网地址,但考虑到部分用户的需求,我们也将相关 xsd 文件部署至 ShardingSphere 官网。
实际上 shardingsphere-jdbc-spring-namespace 的 jar 包中 META-INF\spring.schemas 配置了 xsd 文件的位置: META-INF\namespace\sharding.xsd 和 META-INF\namespace\replica-query.xsd,只需确保 jar 包中该文件存在即可。
shardingsphere-transaction-xa-core 后,如何避免 spring-boot 自动加载默认的 JtaTransactionManager?回答:
@SpringBootApplication(exclude = JtaAutoConfiguration.class)。回答:
某些解压缩工具在解压 ShardingSphere-Proxy 二进制包时可能将文件名截断,导致找不到某些类。
解决方案:
打开 cmd.exe 并执行下面的命令:
tar zxvf apache-shardingsphere-${RELEASE.VERSION}-shardingsphere-proxy-bin.tar.gz
回答:
使用 ShardingSphere-Proxy 时,可以通过 DistSQL 动态的创建或移除 logic schema,语法如下:
CREATE (DATABASE | SCHEMA) [IF NOT EXISTS] schemaName;
DROP (DATABASE | SCHEMA) [IF EXISTS] schemaName;
例:
CREATE DATABASE sharding_db;
DROP SCHEMA sharding_db;
回答:
introspect using JDBC metadata 选项)。回答:
schema 或者没有添加 resource 时,ShardingSphere-Proxy 无法执行 SQL。schema 和 resource 之后再使用第三方数据库工具连接。resource 的详情请参考。相关介绍回答:
行表达式标识符可以使用 ${...} 或 $->{...},但前者与 Spring 本身的属性文件占位符冲突,因此在 Spring 环境中使用行表达式标识符建议使用 $->{...}。
回答:
Java的整数相除结果是整数,但是对于 inline 表达式中的 Groovy 语法则不同,整数相除结果是浮点数。 想获得除法整数结果需要将 A/B 改为 A.intdiv(B)。
回答:
不需要,ShardingSphere 会自动识别。
SingleKeyTableShardingAlgorithm,遇到 ClassCastException: Integer can not cast to Long?回答:
必须确保数据库表中该字段和分片算法该字段类型一致,如:数据库中该字段类型为 int(11),泛型所对应的分片类型应为 Integer,如果需要配置为 Long 类型,请确保数据库中该字段类型为 bigint。
StandardShardingAlgorithm 自定义算法时,指定了 Comparable 的具体类型为 Long, 且数据库表中字段类型为 bigint,出现 ClassCastException: Integer can not cast to Long 异常。回答:
实现 doSharding 方法时,不建议指定方法声明中 Comparable 具体的类型,而是在 doSharding 方法实现中对类型进行转换,可以参考 ModShardingAlgorithm#doSharding 方法
回答:
ShardingSphere 采用 snowflake 算法作为默认的分布式自增主键策略,用于保证分布式的情况下可以无中心化的生成不重复的自增序列。因此自增主键可以保证递增,但无法保证连续。
而 snowflake 算法的最后 4 位是在同一毫秒内的访问递增值。因此,如果毫秒内并发度不高,最后 4 位为零的几率则很大。因此并发度不高的应用生成偶数主键的几率会更高。
在 3.1.0 版本中,尾数大多为偶数的问题已彻底解决,参见:https://github.com/apache/shardingsphere/issues/1617
回答:
allow.range.query.with.inline.sharding 设置为 true 即可(默认为 false)。allow-range-query-with-inline-sharding 设置为 true 即可(默认为 false)。KeyGenerateAlgorithm 接口,也配置了 Type,但是自定义的分布式主键依然不生效?回答:
Service Provider Interface (SPI) 是一种为了被第三方实现或扩展的 API,除了实现接口外,还需要在 META-INF/services 中创建对应文件来指定 SPI 的实现类,JVM 才会加载这些服务。
具体的 SPI 使用方式,请大家自行搜索。
与分布式主键 KeyGenerateAlgorithm 接口相同,其他 ShardingSphere 的扩展功能也需要用相同的方式注入才能生效。
回答:是的,可以支持。但原生自增主键有使用限制,即不能将原生自增主键同时作为分片键使用。
由于 ShardingSphere 并不知晓数据库的表结构,而原生自增主键是不包含在原始 SQL 中内的,因此 ShardingSphere 无法将该字段解析为分片字段。如自增主键非分片键,则无需关注,可正常返回;若自增主键同时作为分片键使用,ShardingSphere 无法解析其分片值,导致 SQL 路由至多张表,从而影响应用的正确性。
而原生自增主键返回的前提条件是 INSERT SQL 必须最终路由至一张表,因此,面对返回多表的 INSERT SQL,自增主键则会返回零。
回答:
由于数据加密的 DDL 尚未开发完成,因此对于自动生成 DDL 语句的 JPA 与 数据加密一起使用时,会导致 JPA 的实体类(Entity)无法同时满足 DDL 和 DML 的情况。
解决方案如下:
cipherColumn 和 assistedQueryColumn 代替逻辑列。回答:
urlSource 的方式定义 dataSource。maxPoolSize、idleTimeout 等。如需增加或覆盖参数配置,请在 dataSource 中通过 PROPERTIES 指定。DistSQL 删除资源时,出现 Resource [xxx] is still used by [SingleTableRule]。回答:
被规则引用的资源将无法被删除。
若资源只被 single table rule 引用,且用户确认可以忽略该限制,则可以添加可选参数 ignore single tables 进行强制删除。
DistSQL 添加资源时,出现 Failed to get driver instance for jdbcURL=xxx。回答:
ShardingSphere-Proxy 在部署过程中没有添加 jdbc 驱动,需要将 jdbc 驱动放入 ShardingSphere-Proxy 解压后的 ext-lib 目录,例如:mysql-connector。
回答:
在 ShardingSphere-Proxy 以及 ShardingSphere-JDBC 1.5.0 版本之后提供了 sql.show 的配置,可以将解析上下文和改写后的 SQL 以及最终路由至的数据源的细节信息全部打印至 info 日志。
sql.show 配置默认关闭,如果需要请通过配置开启。
注意:5.x版本以后,
sql.show参数调整为sql-show。
回答:
ShardingSphere 使用 lombok 实现极简代码。关于更多使用和安装细节,请参考 lombok官网。
org.apache.shardingsphere.sql.parser.autogen 包下的代码由 ANTLR 生成,可以执行以下命令快速生成:
./mvnw -Dcheckstyle.skip=true -Drat.skip=true -Dmaven.javadoc.skip=true -Djacoco.skip=true -DskipITs -DskipTests install -T1C
生成的代码例如 org.apache.shardingsphere.sql.parser.autogen.PostgreSQLStatementParser 等 Java 文件由于较大,默认配置的 IDEA 可能不会索引该文件。
可以调整 IDEA 的属性:idea.max.intellisense.filesize=10000。
回答:
SQLServer 和 PostgreSQL 获取不加别名的聚合列会改名。例如,如下 SQL:
SELECT SUM(num), SUM(num2) FROM tablexxx;
SQLServer 获取到的列为空字符串和(2),PostgreSQL 获取到的列为空 sum 和 sum(2)。这将导致 ShardingSphere 在结果归并时无法找到相应的列而出错。
正确的 SQL 写法应为:
SELECT SUM(num) AS sum_num, SUM(num2) AS sum_num2 FROM tablexxx;
回答:
针对上面问题解决方式有两种:
配置启动 JVM 参数 “-oracle.jdbc.J2EE13Compliant=true”
通过代码在项目初始化时设置 System.getProperties().setProperty(“oracle.jdbc.J2EE13Compliant”, “true”);
原因如下:
org.apache.shardingsphere.sharding.merge.dql.orderby.OrderByValue#getOrderValues() 方法如下:
private List<Comparable<?>> getOrderValues() throws SQLException {
List<Comparable<?>> result = new ArrayList<>(orderByItems.size());
for (OrderItem each : orderByItems) {
Object value = resultSet.getObject(each.getIndex());
Preconditions.checkState(null == value || value instanceof Comparable, "Order by value must implements Comparable");
result.add((Comparable<?>) value);
}
return result;
}
使用了 resultSet.getObject(int index) 方法,针对 TimeStamp oracle 会根据 oracle.jdbc.J2EE13Compliant 属性判断返回 java.sql.TimeStamp 还是自定义 oralce.sql.TIMESTAMP 详见 ojdbc 源码 oracle.jdbc.driver.TimestampAccessor#getObject(int var1) 方法:
Object getObject(int var1) throws SQLException {
Object var2 = null;
if(this.rowSpaceIndicator == null) {
DatabaseError.throwSqlException(21);
}
if(this.rowSpaceIndicator[this.indicatorIndex + var1] != -1) {
if(this.externalType != 0) {
switch(this.externalType) {
case 93:
return this.getTimestamp(var1);
default:
DatabaseError.throwSqlException(4);
return null;
}
}
if(this.statement.connection.j2ee13Compliant) {
var2 = this.getTimestamp(var1);
} else {
var2 = this.getTIMESTAMP(var1);
}
}
return var2;
}
回答:
为保证源码的可读性,ShardingSphere 编码规范要求类、方法和变量的命名要做到顾名思义,避免使用缩写,因此可能导致部分源码文件命名较长。由于 Windows 版本的 Git 是使用 msys 编译的,它使用了旧版本的 Windows Api,限制文件名不能超过 260 个字符。
解决方案如下:
打开 cmd.exe(你需要将 git 添加到环境变量中)并执行下面的命令,可以让 git 支持长文件名:
git config --global core.longpaths true
如果是 Windows 10,还需要通过注册表或组策略,解除操作系统的文件名长度限制(需要重启):
在注册表编辑器中创建
HKLM\SYSTEM\CurrentControlSet\Control\FileSystem LongPathsEnabled, 类型为REG_DWORD,并设置为1。 或者从系统菜单点击设置图标,输入“编辑组策略”, 然后在打开的窗口依次进入“计算机管理” > “管理模板” > “系统” > “文件系统”,在右侧双击“启用 win32 长路径”。
参考资料: https://docs.microsoft.com/zh-cn/windows/desktop/FileIO/naming-a-file https://ourcodeworld.com/articles/read/109/how-to-solve-filename-too-long-error-in-git-powershell-and-github-application-for-windows
回答:
ShardingSphere 中很多功能实现类的加载方式是通过 SPI 注入的方式完成的,如分布式主键,注册中心等;这些功能通过配置中 type 类型来寻找对应的 SPI 实现,因此必须在配置文件中指定类型。
metadata 加载速度?回答:
4.0.1 以上的版本,以提高 metadata 的加载速度。max.connections.size.per.query(默认值为1)调高(版本 >= 3.0.0.M3 且低于 5.0.0)。max-connections-size-per-query(默认值为1)调高(版本 >= 5.0.0)。回答:
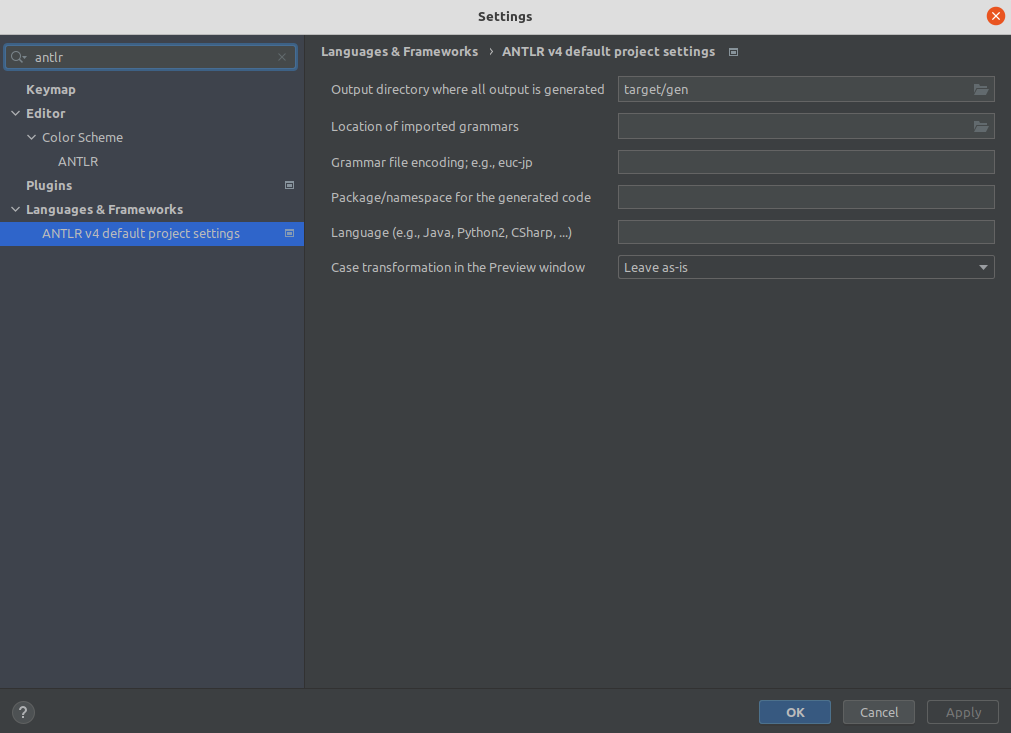
进入 Settings -> Languages & Frameworks -> ANTLR v4 default project settings 配置生成代码的输出目录为 target/gen,如图:
Proxool 时分库结果不正确?回答:
使用 Proxool 配置多个数据源时,应该为每个数据源设置 alias,因为 Proxool 在获取连接时会判断连接池中是否包含已存在的 alias,不配置 alias 会造成每次都只从一个数据源中获取连接。
以下是 Proxool 源码中 ProxoolDataSource 类 getConnection 方法的关键代码:
if(!ConnectionPoolManager.getInstance().isPoolExists(this.alias)) {
this.registerPool();
}
更多关于 alias 使用方法请参考 Proxool官网。
PS:sourceforge 网站需要翻墙访问。
回答:
需要特别注意,Spring Boot 2.x 环境下配置文件的属性名称约束为仅允许小写字母、数字和短横线,即 [a-z][0-9] 和 -。
原因如下:
Spring Boot 2.x 环境下,ShardingSphere 通过 Binder 来绑定配置文件,属性名称不规范(如:驼峰或下划线等)会导致属性设置不生效从而校验属性值时抛出 NullPointerException 异常。参考以下错误示例:
下划线示例:database_inline
spring.shardingsphere.rules.sharding.sharding-algorithms.database_inline.type=INLINE
spring.shardingsphere.rules.sharding.sharding-algorithms.database_inline.props.algorithm-expression=ds-$->{user_id % 2}
Caused by: org.springframework.beans.factory.BeanCreationException: Error creating bean with name 'database_inline': Initialization of bean failed; nested exception is java.lang.NullPointerException: Inline sharding algorithm expression cannot be null.
...
Caused by: java.lang.NullPointerException: Inline sharding algorithm expression cannot be null.
at com.google.common.base.Preconditions.checkNotNull(Preconditions.java:897)
at org.apache.shardingsphere.sharding.algorithm.sharding.inline.InlineShardingAlgorithm.getAlgorithmExpression(InlineShardingAlgorithm.java:58)
at org.apache.shardingsphere.sharding.algorithm.sharding.inline.InlineShardingAlgorithm.init(InlineShardingAlgorithm.java:52)
at org.apache.shardingsphere.spring.boot.registry.AbstractAlgorithmProvidedBeanRegistry.postProcessAfterInitialization(AbstractAlgorithmProvidedBeanRegistry.java:98)
at org.springframework.beans.factory.support.AbstractAutowireCapableBeanFactory.applyBeanPostProcessorsAfterInitialization(AbstractAutowireCapableBeanFactory.java:431)
...
驼峰示例:databaseInline
spring.shardingsphere.rules.sharding.sharding-algorithms.databaseInline.type=INLINE
spring.shardingsphere.rules.sharding.sharding-algorithms.databaseInline.props.algorithm-expression=ds-$->{user_id % 2}
Caused by: org.springframework.beans.factory.BeanCreationException: Error creating bean with name 'databaseInline': Initialization of bean failed; nested exception is java.lang.NullPointerException: Inline sharding algorithm expression cannot be null.
...
Caused by: java.lang.NullPointerException: Inline sharding algorithm expression cannot be null.
at com.google.common.base.Preconditions.checkNotNull(Preconditions.java:897)
at org.apache.shardingsphere.sharding.algorithm.sharding.inline.InlineShardingAlgorithm.getAlgorithmExpression(InlineShardingAlgorithm.java:58)
at org.apache.shardingsphere.sharding.algorithm.sharding.inline.InlineShardingAlgorithm.init(InlineShardingAlgorithm.java:52)
at org.apache.shardingsphere.spring.boot.registry.AbstractAlgorithmProvidedBeanRegistry.postProcessAfterInitialization(AbstractAlgorithmProvidedBeanRegistry.java:98)
at org.springframework.beans.factory.support.AbstractAutowireCapableBeanFactory.applyBeanPostProcessorsAfterInitialization(AbstractAutowireCapableBeanFactory.java:431)
...
从异常堆栈中分析可知: AbstractAlgorithmProvidedBeanRegistry.registerBean 方法调用 PropertyUtil.containPropertyPrefix(environment, prefix) 方法判断指定前缀 prefix 的配置是否存在,而 PropertyUtil.containPropertyPrefix(environment, prefix) 方法,在 Spring Boot 2.x 环境下使用了 Binder,不规范的属性名称(如:驼峰或下划线等)会导致属性设置不生效。